Claude Features
Notes on features of Claude from Anthropic's course. Covers extended thinking, citations and prompt caching.
Extended Thinking
Not compatible with pre-filling and temperature features.
A feature to give the model more time before generating a response. You can get to see the reasoning process that leads to the answer - more transparency and hopefully better quality responses. You in turn have to pay more due to token usage and have increased latency.
Causes the response to go from a simple block of text to a 2 part structured response - a thinking block and a text block:
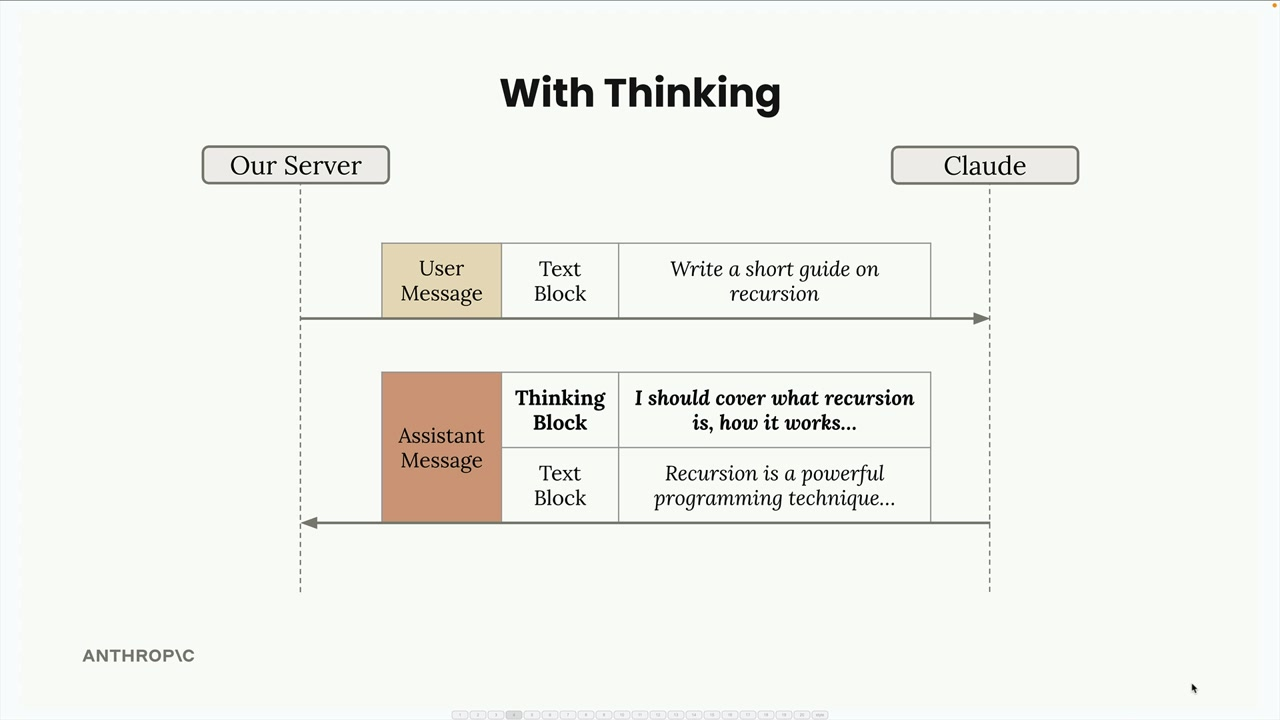
The thinking block is signed to ensure the thinking text was not changed.
It's useful for when standard prompts are not getting you there and you need more insight in order to improve.
Redacted thinking - when a thinking process is flagged by internal safety systems, the thinking block can become redacted. The thinking block is still sent back too you, but this time it's encrypted which means you can still send it back to Claude in a multi-convo flow without losing context. For testing purposes you can also cause Claude to send a redacted thinking response.
Enabling Thinking
You enable this feature as part of the chat function:
def chat(
messages,
system=None,
temperature=1.0,
stop_sequences=[],
tools=None,
thinking=False,
thinking_budget=1024
):
Image Support
Claude also has vision capabilities for visual analysis tasks. There are various constraints around the number of images in a single request, max size of an image, max dimensions etc. Each image has an associated token usage:
tokens = (width * height) / 750
You send images in base64 using an image block:
{
"type": "image",
"source": {
"type": "base64",
"media_type": "image/png",
"data": image_bytes,
}
},
Image Prompting
The same techniques apply as for regular prompts:
- Providing detailed guidelines and analysis steps
- Using one-shot or multi-shot examples
- Breaking down complex tasks into smaller steps

"Invest time in crafting detailed, structured prompts rather than relying on simple questions if you want reliable results."
PDF Support
You can also send base64 encoded PDFs for Claude to analyse:
{
"type": "document",
"source": {
"type": "base64",
"media_type": "application/pdf",
"data": file_bytes,
},
},
Note that now the type is a document instead of an image.
Claude can handle the following for PDFs:
- Text content throughout the document
- Images and charts embedded in the PDF
- Tables and their data relationships
- Document structure and formatting
Citations
You can enable citations to provide transparency and verify the info Claude is providing you. This works for PDFs and for plain text. To enable this feature you set the citation field:
{
"type": "document",
"source": {
"type": "base64",
"media_type": "application/pdf",
"data": file_bytes,
},
"title": "earth.pdf",
"citations": { "enabled": True }
}
Citations are useful when:
- Users need to verify information for accuracy
- You're working with authoritative documents that users should be able to reference
- Transparency about information sources is critical for your application
- Users might want to explore the broader context around specific facts

- cited_text - The exact text from your document that supports Claude's statement
- document_index - Which document Claude is referencing (useful when you provide multiple documents)
- document_title - The title you assigned to the document
- start_page_number - Where the cited text begins
- end_page_number - Where the cited text ends
Prompt Caching
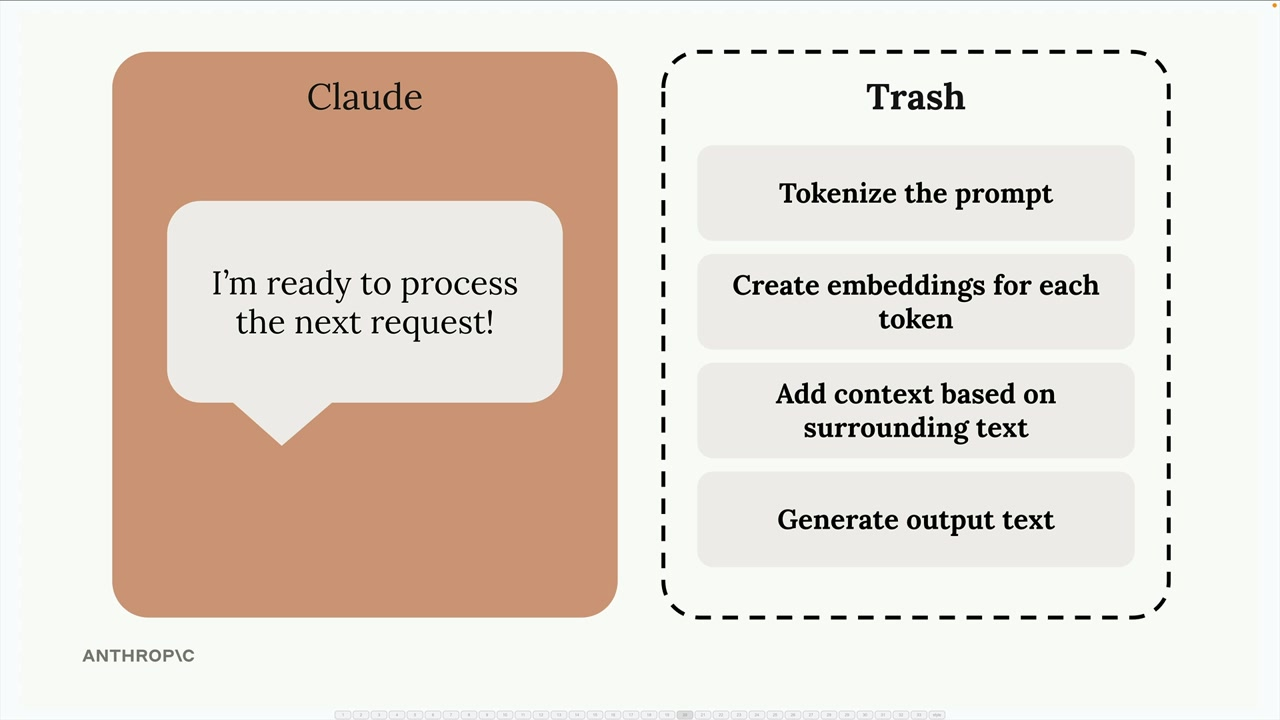
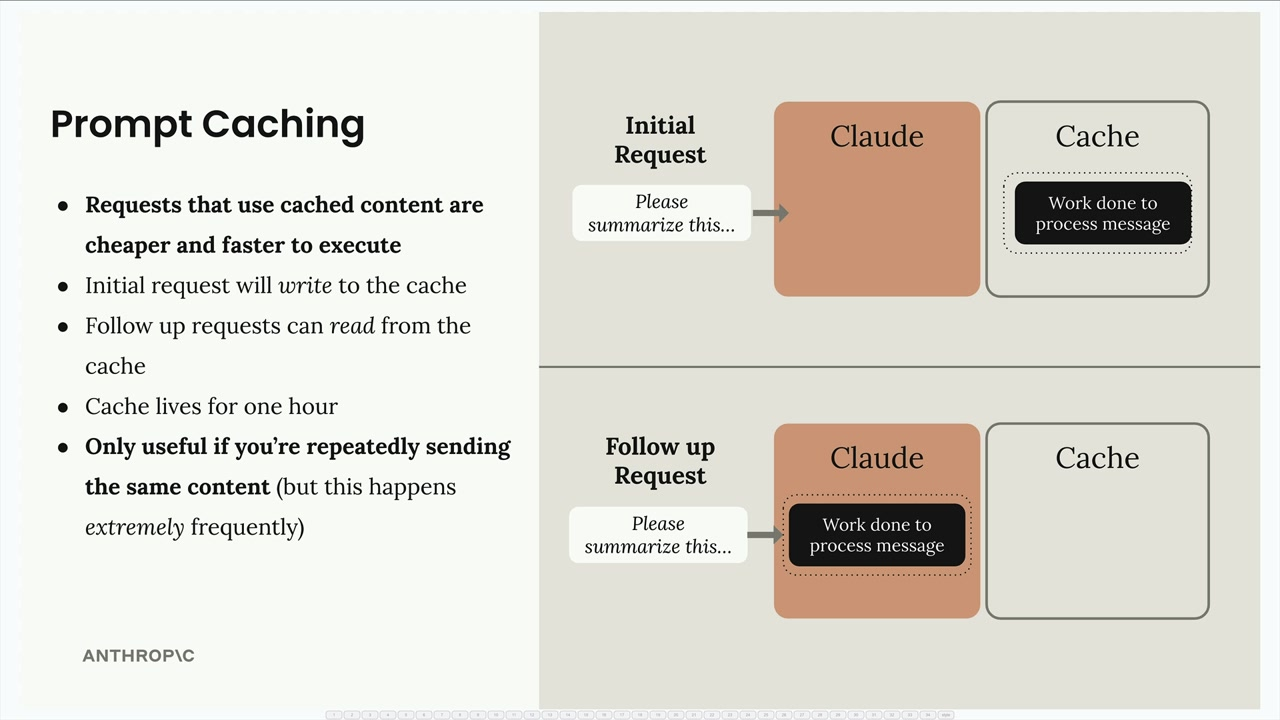
Enable the reuse of computational work from previous requests. With a standard response, a lot of data and work is effectively trash after the LLM sends the response:
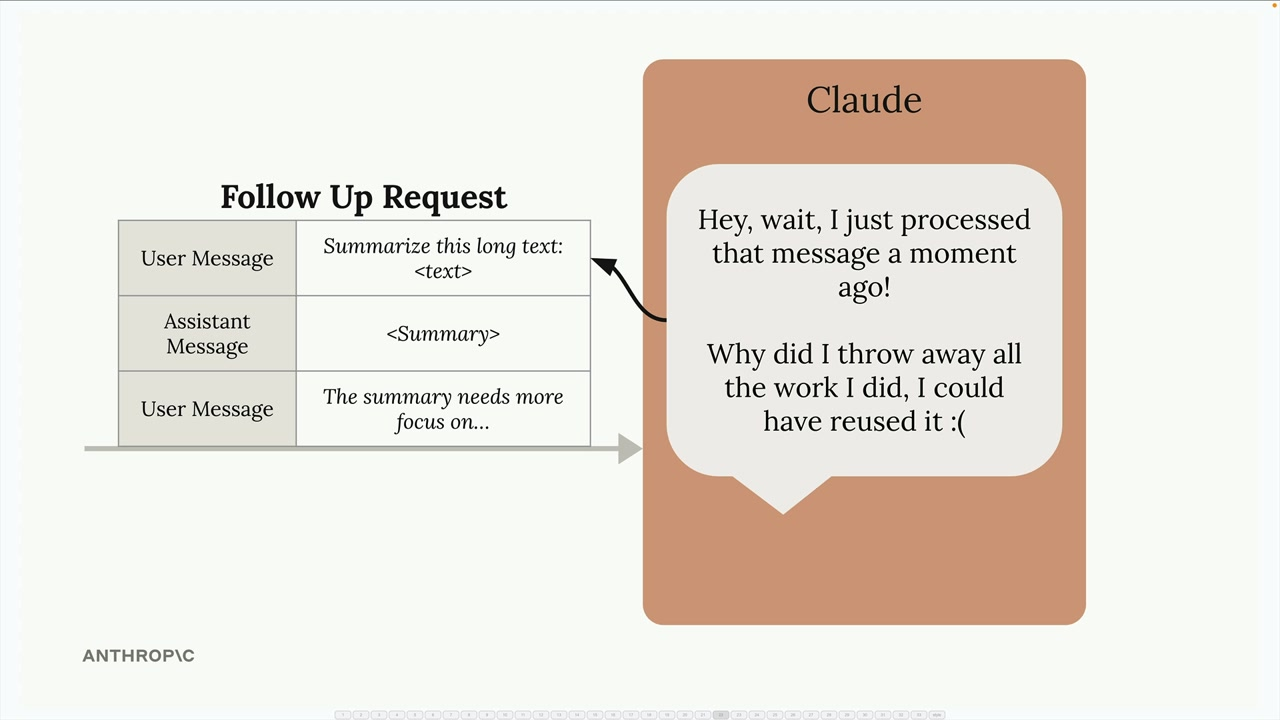
When we then send follow up requests, the same work needs to be repeated:
With caching, the results are stored:
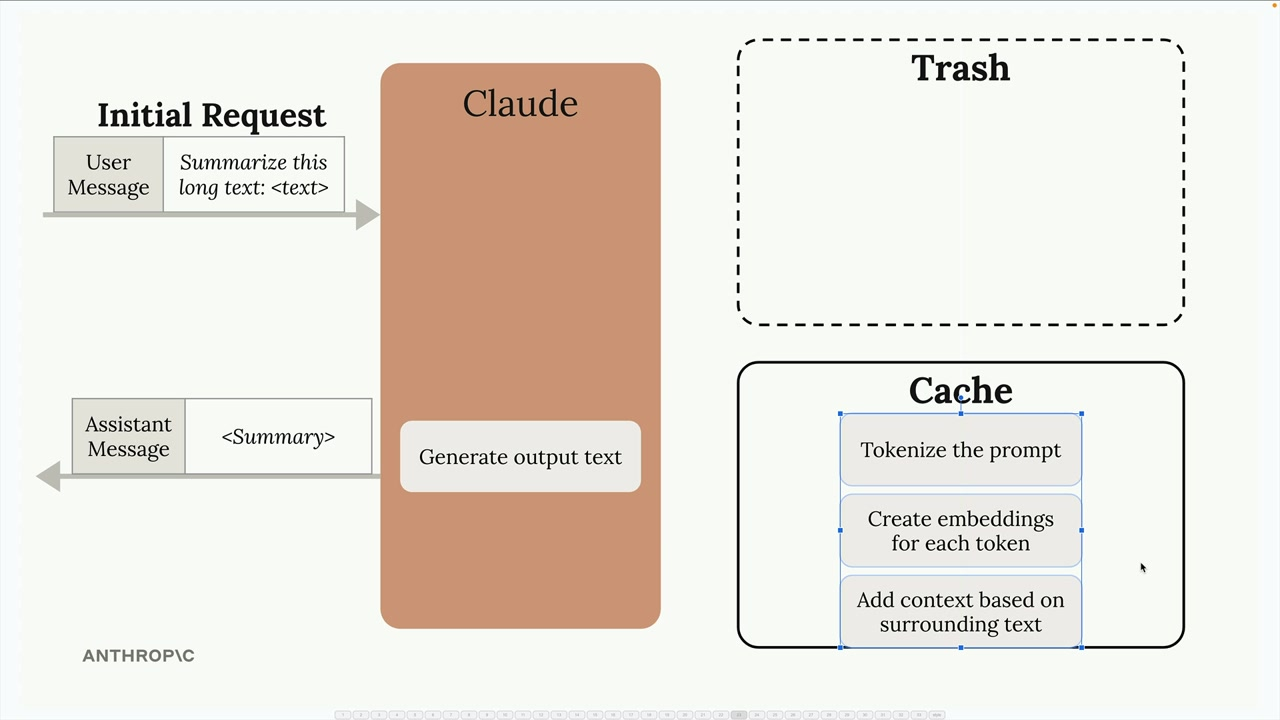

Requests that use cached content are therefore cheaper and faster to execute.
- Faster responses: Requests using cached content execute more quickly
- Lower costs: You pay less for the cached portions of your requests
- Automatic optimization: The initial request writes to the cache, follow-up requests read from it
Most useful for when you're analysing documents, or iterative editing on the same item.
Cache Control
Using cache breakpoints we control the caching policy. Work done before the breakpoint will be cached.
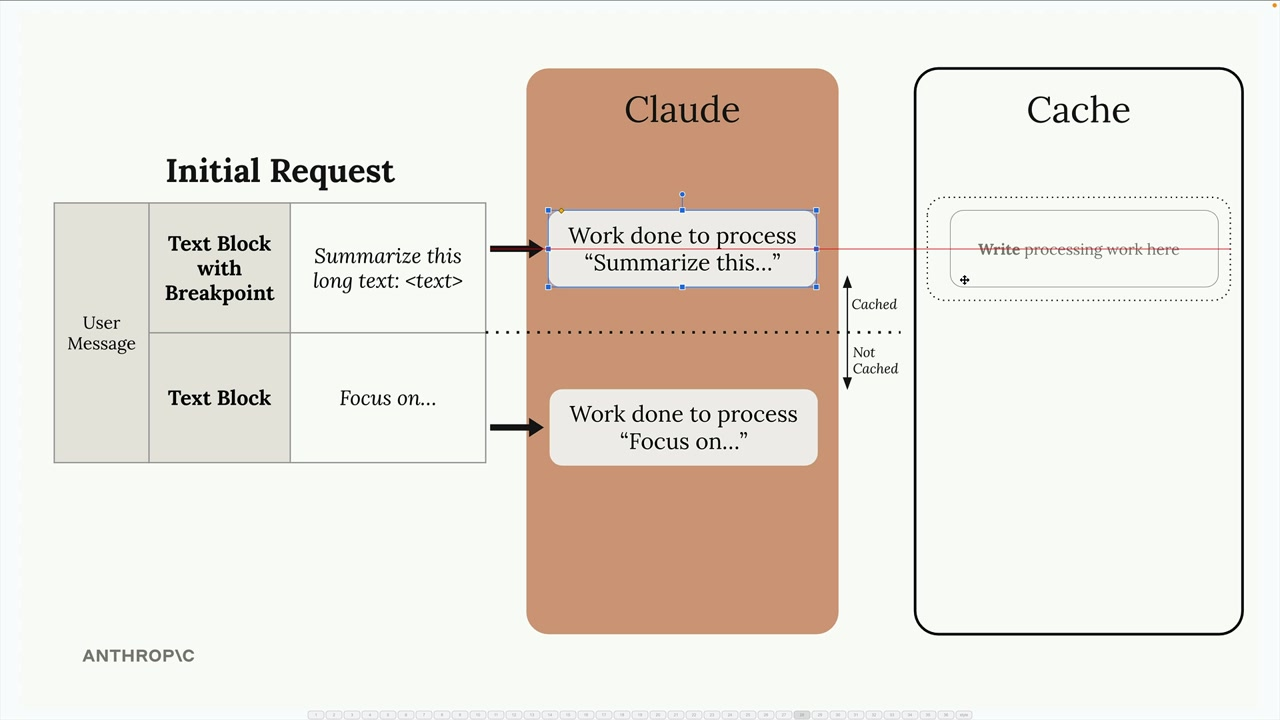
An example of enabling cache control (using the full format of the message):

You can add cache breakpoints too:
- System prompts
- Tool definitions
- Image blocks
- Tool use and tool result blocks

"System prompts and tool definitions are excellent candidates for caching since they rarely change between requests. This is often where you'll get the most benefit from prompt caching."
Advantageous for:
- Large system prompts (like a 6K token coding assistant prompt)
- Complex tool schemas (around 1.7K tokens for multiple tools)
- Repeated message content
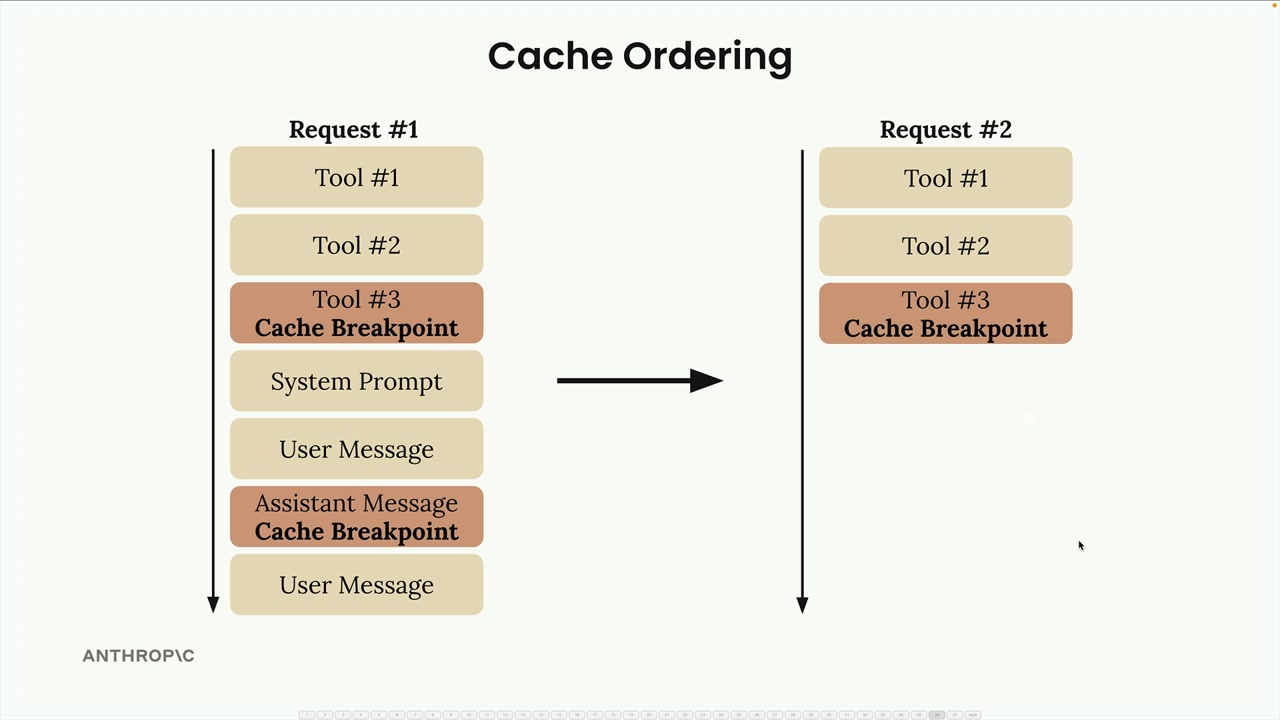
Cache Ordering
You can add up to 4 cache breakpoints. The content length must be at least 1024 tokens long in order for the request to be cached.
"The cache is extremely sensitive - changing even a single character in your tools or system prompt invalidates the entire cache for that component."
The order Claude runs things:
- Tools (if provided)
- System prompt (if provided)
- Messages
This means if you change the system prompt, but not tools, you'll see a partial cache read for tools and a cache write for the system prompt - granularity in caching.
Code Execution and Files API
Files API
The files API lets you upload files ahead of time and reference them later using a returned metadata ID rather than sending the file in base64 each time.

Code Execution
Allows you to executed Python code in a Docker container which is isolated - no network access for external API calls.
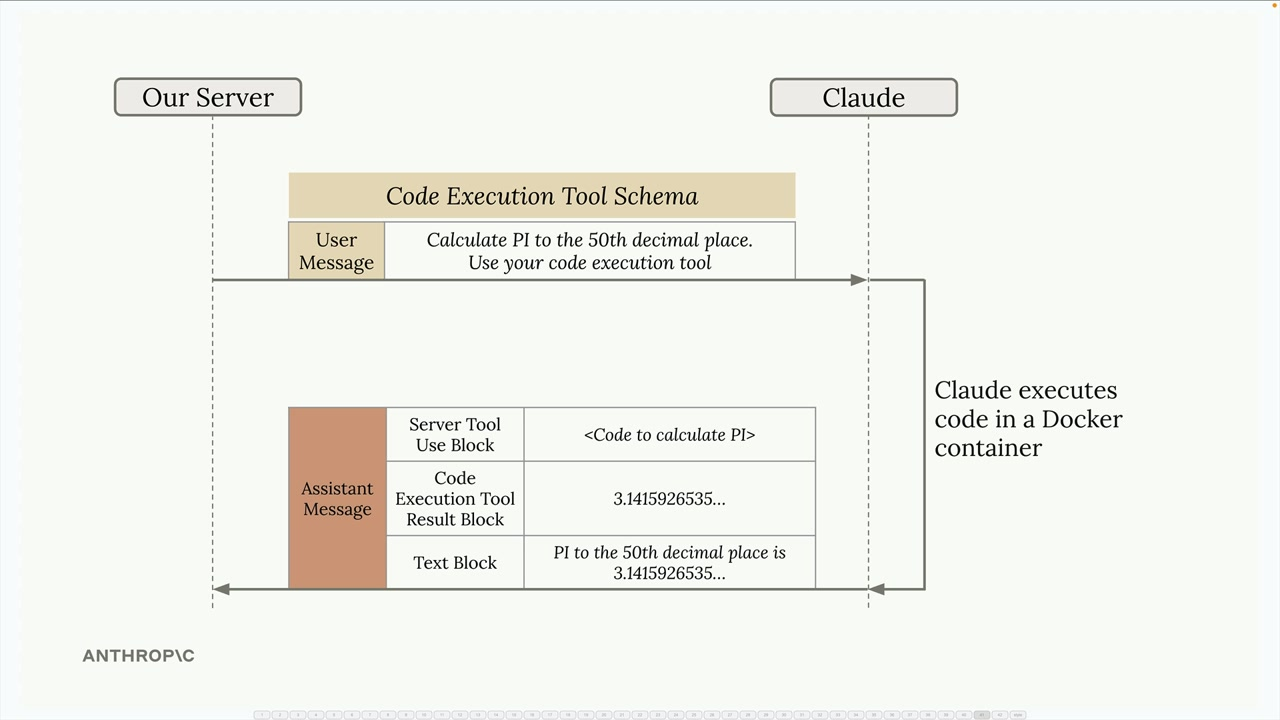
In order to get data out, we typically use the files API. A typical workflow:
- Upload your data file (like a CSV) using the Files API
- Include a container upload block in your message with the file ID
- Ask Claude to analyze the data
- Claude writes and executes code to process your file
- Claude can generate outputs (like plots and reports) that you can download