False Sharing and Padding
Some notes on false sharing and cache line padding.

False Sharing
Let's say we have a line from main memory cached on both CPU1 and CPU2's L1 cache. When CPU1 writes to that line, it needs to be kept coherent with the copy on CPU2.
This occurs via cache coherence protocols which transition a cache line across three states: dirty, invalidated and refreshed, based on a series of async messages/events which are typically communicated across L2 cache.
Writes to the line are what cause this.
Let's say we have a cache line with 2 variables - the first variable is written too by CPU1 and the second variable is written too by CPU2. The CPUs are not sharing any variables, but they do each have the same cache line (by virtue of how the variables are stored in physical memory they can end up being in the same cache line).
You can see that this would cause the line in both CPUs to repeatedly go through this cycle of dirty-invalidated-refreshed in order to maintain consistency. Basically, we end up with a lot of cache coherency overhead. You can see this if you profile the cache behavior using perf.
Even though the two CPUs are not actually sharing any data/variables, they are sharing the same cache line, and in order to maintain consistency, we must utilize cache coherency and accept the associated overhead and latency.
This is false sharing. The solution is to ensure that frequently accessed data elements are in separate cache lines - we can achieve this by adding padding.
This is particularly important for variables which are frequently used or written too like a sequence number, or elements of certain concurrent data structures.
Annotation Based Padding in Java
We can add padding using the @Contended annotation (jdk.internal.vm.annotation.Contended) at the field level to prevent a specific field being in the same cache line as any others from that class:
public class Example {
@Contended
public volatile long globalSequence;
public volatile long localSequence;
}
You can also apply this at the class level to prevent any of the fields being in the same cache line:
@Contended
public class Example {
public volatile long globalSequence;
public volatile long localSequence;
}
You can also apply groups to make sure fields are kept close together and possibly in the same cache line:
public class Example {
@Contended("reader")
public volatile long readerSequence;
@Contended("writer")
public volatile long writerSequence;
@Contended("writer")
public volatile long bytesWritten;
}
In the above example the we have a group called "reader" which is now not in the same cache line as any of the fields from the "writer" group.
The fields from the "writer" group are grouped close in main memory, possibly in the same cache line - useful if we know those vars are used by the same thread.
The size of the padding needed is architecture dependent (based on the cache line size). We can specify the size of the padding using a JVM arg, for example: -XX:ContendedPaddingWidth=64
The @Contended annotation impacts the memory layout of the object by adding an "alignment/padding gap".
Manual/Explicit Padding in Java
There is a manual or explicit style of padding which is used in the wild in the LMAX Disruptor and Aeron codebases.
To ensure a field is correctly padded, there must be a known amount of padding bytes around it. Because the JDK can reorder fields (to optimise for alignment on 8 byte boundaries) as it sees fit, this constraint can fail if we have manually added fields around it ourselves e.g. we want 7 fields followed by the field we want to pad, followed by another 7 fields but the compiler reorders all of our padding fields to occur at the end in memory layout.
Using a class hierarchy enforces that padding bytes can only be re-ordered within a class, not across them:
class LhsPadding
{
protected long p1, p2, p3, p4, p5, p6, p7;
}
class Value extends LhsPadding
{
protected volatile long value;
}
class RhsPadding extends Value
{
protected long p9, p10, p11, p12, p13, p14, p15;
}
public class Sequence extends RhsPadding
Michael Barker explains this much better than me:
"By placing the padding in an inheritance heirachy this prevents the compiler
from reordering the fields across class boundaries. Therefore we could see:
p1, p7, p4, p5, p6, p2, p3
value
p9, p11, p12, p10, p13, p14, p15
But won't see:
p1,
value
p7, p4, p5, p6, p2, p3, p9, p11, p12, p10, p13, p14, p15
Laid out in memory, but there should always be 7 padded
values either side of the real value.
Mike."
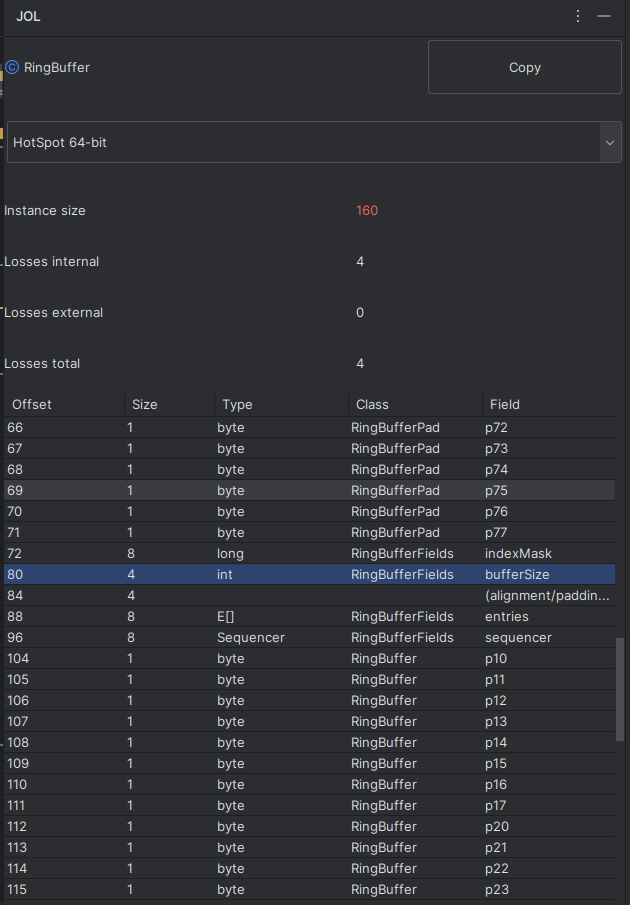
Something else I found useful when trying to understand the actual amount of padding being added:
LMAX Disruptor
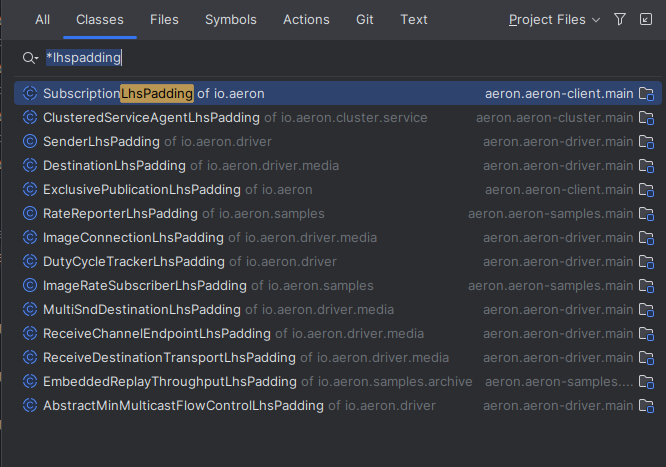
Aeron
Places where padding is used:
Links and Resources
https://mechanical-sympathy.blogspot.com/2011/07/false-sharing.html - Martin Thompson, Mechanical Sympathy, "False Sharing"
https://mechanical-sympathy.blogspot.com/2011/08/false-sharing-java-7.html - Martin Thompson, Mechanical Sympathy, "False Sharing Java 7"
https://www.youtube.com/watch?v=FygXDrRsaU8 - Notes by Nick, Coffee Before Arch, "False Sharing"
https://www.youtube.com/watch?v=h58X-PaEGng - Vadim Karpusenko (Colfax International), "Elimination of False Cache Line Sharing"
https://groups.google.com/g/lmax-disruptor/c/n1i3_7VOSE0 - Google Groups, "why padding on sequence?"
https://www.youtube.com/watch?v=h58X-PaEGng - Jakob Jenkov, "False Sharing in Java"