Tensorflow - NLP
Some notes on NLP and Tensorflow.

Tokenize
Tensorflow has a tokenizer:
from tensorflow.keras.preprocessing.text import Tokenizer
You can also specify a num_words param when instantiating the tokenizer.
word_index - the full list of words to token values
Unknown Words
When we create the tokenizer, can specify an Out of Value (or Out Of Vocab) token - when a sequencer requests the token value of a token unknown to the tokenizer, return the OOV token. This maintains some structure and also keeps the length of the training sentence the same length as the input sentence.
Sequences
Convert samples to sequences of numbers based on the results of tokenization.
Variable Length Inputs
Ragged Tensors
Ragged tensors are used for variable length inputs.
Padding
Pre or post pad all samples (with 0) to match the length of the longest sentence in the corpus.
Can also specify a maxlen for padding with a truncating param.
from tensorflow.keras.preprocessing.sequence import pad_sequences
sequences = tokenizer.texts_to_sequences(sentences)
padded = pad_sequences(sequences)

Recurrent Neural Networks
Takes the sequence of data into account when learning e.g. in a sentence. The traditional sentiment approach only takes into account the product of the word vectors, not the order of the words.
Consider the Fibonnaci sequence:

As a computation graph:

We pass the 2nd parameter of the first computation (which is the number 2) onto the next stage with the result (the result being 3)
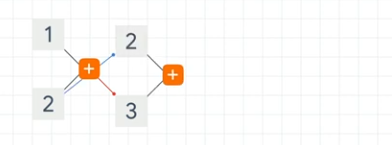
This continues with the result of the previous computation being fed forward
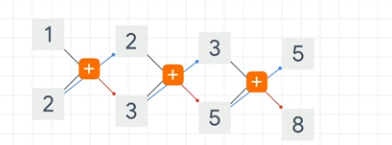
This means that all elements in the series are part of the current value.
Recurrent Neurons
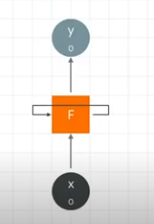
A function that gets an input, x and produces an output, y. It also outputs a feed forward value, F.
They can be grouped together as so:
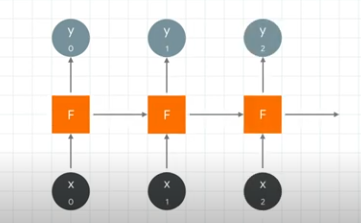
When we pass in x0, it outputs y0 and also outputs a value to be fed into the next neuron.
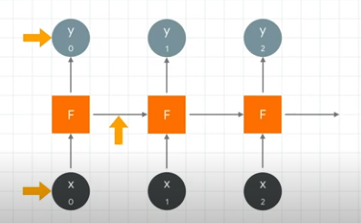
The next neuron gets the output from the previous neuron and also gets x1 which it then uses to calculate y1. It also outputs a feed forward value.
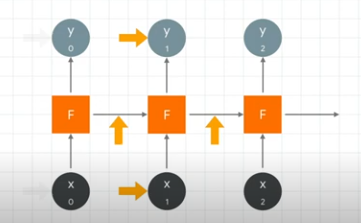
Thus sequence is encoded into the output.
The number at position 1 has an impact on the number at position 100, even if it's smaller than the impact from the input at 99.
LSTMs
LSTM - Long Short Term Memory
Over a long distance, context becomes diluted. The LSTM architecture introduces a cell state which is bidirectional context across neurons.
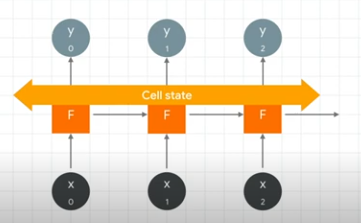
The bidirectionally allows for more recent words to provide context for words at the start.
To do this in Keras, we introduce a bidirectional LSTM layer:
tf.keras.layers.Bidirectional(tf.keras.layers.LSTM(64))
The 64 represents the number of hidden nodes in that layer and also the shape of the output from the LSTM layer.
You can also stack LSTM layers:
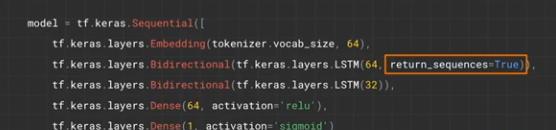
Note we've had to add return_sequences=true for all but the final LSTM layer.