Memory Barriers and Fencing
Notes on memory barriers and fencing.

The CPU and compiler can perform whatever optimizations they see fit as long as it achieves the same result. Reordering of memory operations is a key technique used by CPUs to improve performance.
Memory barriers prevent reordering of memory operations both at compile time and at runtime.
Store ~ store to memory
Load ~ load from memory
This allows for loads and stores to occur in a well defined order (the program order is consistent when viewed from the perspective of different CPUs), and makes the use of memory barriers a key technique for lock free programming.
Barriers also ensure data is propagated to the cache sub-system, which is what makes the memory/state visible across CPUs.
Runtime Reordering
Let's say we write to 2 vars, a and b. They get written to the CPU cache, not main memory.

In the above image we see that whilst a was written to the CPU cache before b, when it comes to writing to main memory it was b that was written before a.
There is a difference between the program order and the observed order.
Load and Store Buffering
When we load or store something, there are are a set of buffers that are written or read from, before that data makes it's way to the cache subsystem.
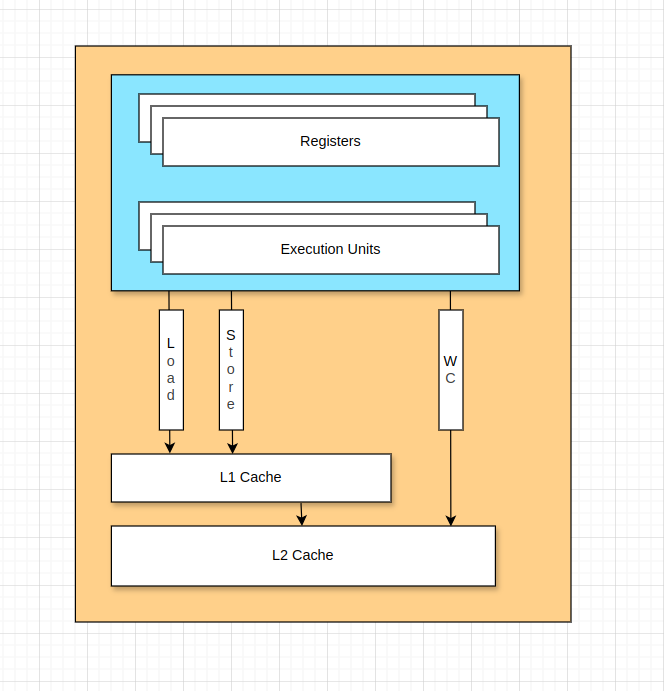
These buffers are a type of queue with fast lookup - this mean the CPU can also read from these buffers as opposed to the cache subsystem (if the data is in the store buffer and not yet in the cache subsystem) in order to improve performance.
These buffers are also an integral component of the async nature of cache coherency protocols.
SFence
The sfence instruction is how a store barrier is implemented.
All stores prior (in program order) to the sfence instruction are globally visible before any stores that come after (in program order) the sfence.
All stores prior to the sfence instruction must be written from the store buffer to the L1 cache. This ensures visibility of state to other CPUs.
"The use of weakly-ordered memory types can be important under certain data sharing relationships (such as a producer-consumer relationship). Using weakly-ordered memory can make assembling the data more efficient, but care must be taken to ensure that the consumer obtains the data that the producer intended to see." - Intel architecture optimization manual.
LFence
The lfence instruction is how a load barrier is implemented.
All loads prior (in program order) to the lfence instruction occur before any load instructions that come after the lfence instruction.
We ensure global visibility of loads that come before the lfence occur before global visibility of loads that come after the lfence.
Makes sure that state updates from other CPUs is visible to the current CPU before continuing by ensuring the load buffer is drained before continuing execution.
MFence
An mfence or full barrier is a combination of a load and store barrier.
Acquire and Release Barriers
No Barriers
Reads and writes can be reordered however the CPU wants.
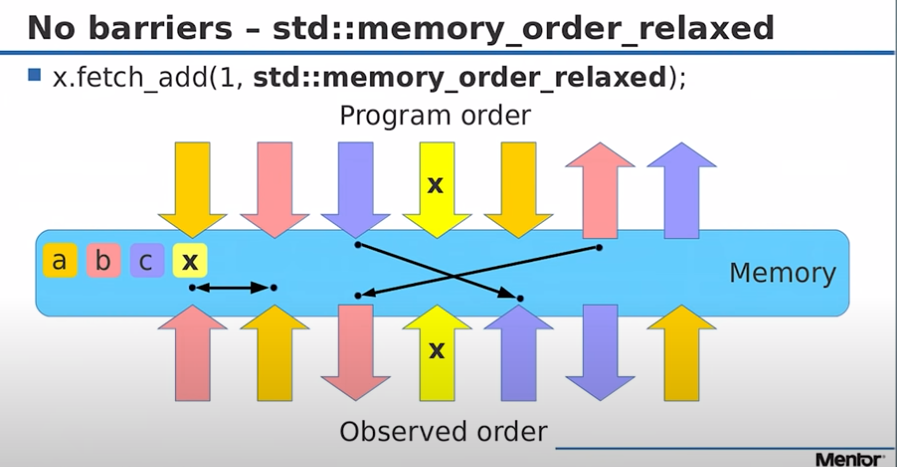
This diagram is taken from a presentation by Fedor Pikus (a Technical Fellow at Siemens Digital Industries) about C++ atomics, the yellow arrows marked with X indicates an atomic variable he is adding 1 to.
The colour coded a,b,c,x boxes indicate the variables he is discussing and writing too or reading from.
The top part (above the blue memory box) is the program order.
The bit below blue memory box is the observed order.
The black arrows indicate memory reordering operations.
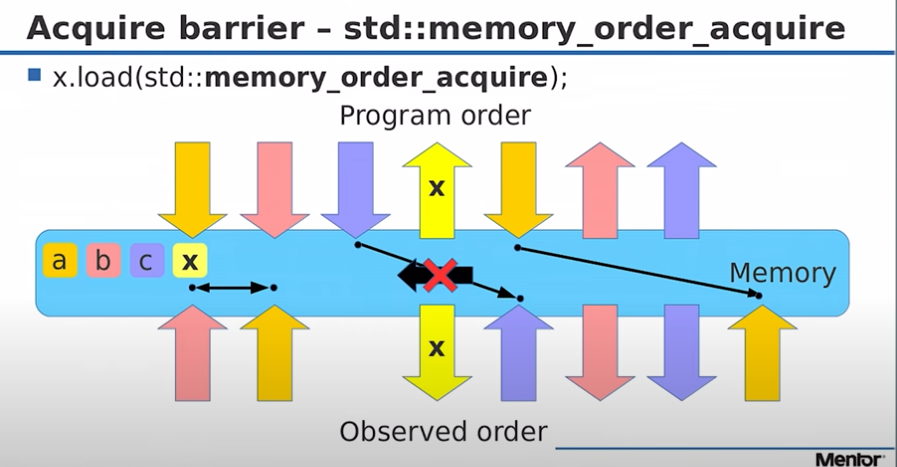
Acquire Barrier
Memory operations that occur after the barrier in program order become visible after the barrier. This means we can't reorder memory operations that occur after the barrier to now come before the barrier.
Anything before the barrier at x can be re-ordered to be after the barrier at x.
Anything after the barrier at x can not be re-ordered to be before the barrier at x.
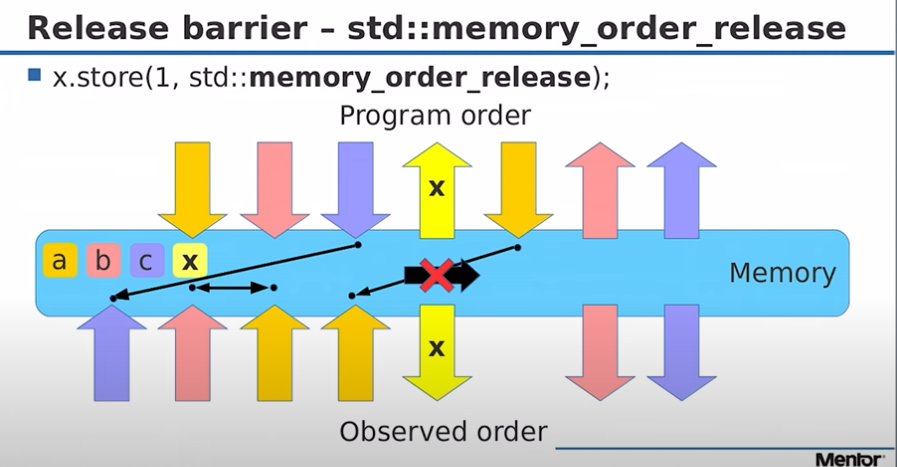
Release Barrier
Memory operations that occur before the barrier in program order become visible before the barrier. This means we can't reorder memory operations that occur before the barrier to now come after the barrier.
Anything after the barrier at x can be reordered to occur before the barrier at x.
Anything that was before the barrier at x can not be reordered to occur after the barrier at x.
Using Acquire-Release Barriers
A common pattern of usage for acquire and release barriers is when we have a producing (thread 1) and a consuming thread (thread 2).
Thread 1 writes then issues a release barrier - all writes before the barrier become visible to other threads after the barrier.
Thread 2 reads with an acquire barrier in order to sync with the published data.
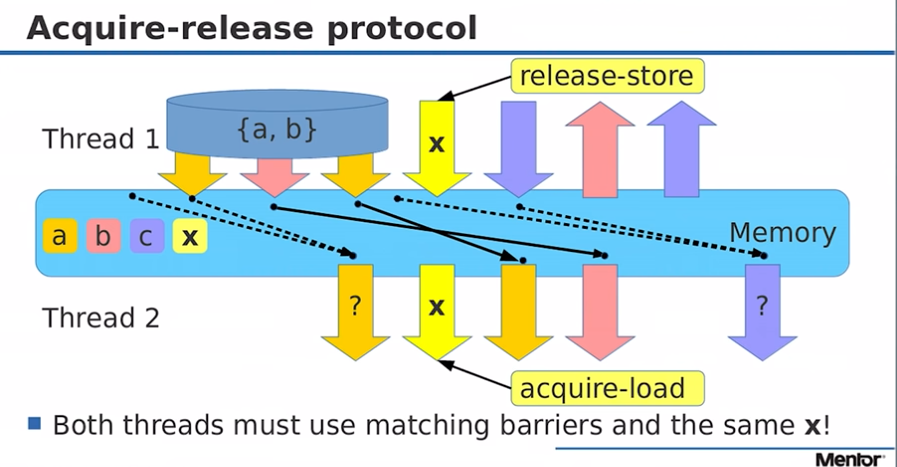
In the above diagram, there is some non-atomic variables (a and b) which are written too before the release-store fence issued by thread 1.
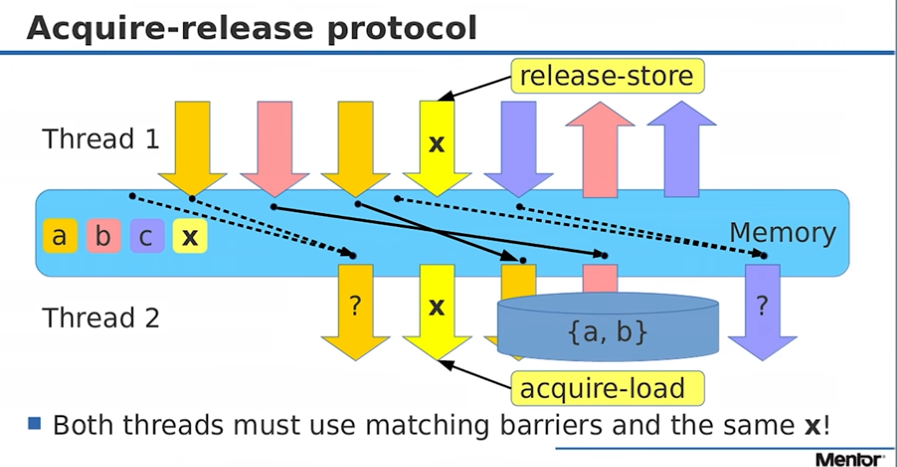
The reading thread (thread 2) issues an acquire-load and reads variables a and b after the acquire load (in program order).
Examples of Memory Barrier Use
These are Java examples of how memory barriers are used in practice.
Volatile Fields in Java
When we do a write to a volatile variable, we start with an sfence to ensure the store buffers are flushed and state is being propagated. The variable is then written too/stored too. This is followed by a full barrier - the store buffer is flushed and the load buffer is drained.
A full barrier is required to ensure the drain of the load buffer (cache coherency protocol messages?) not just the flushing of the store buffer to L1 cache.
The LMAX Disruptor Sequence Impl
This is how the get() is implemented:
public long get()
{
long value = this.value;
VarHandle.acquireFence();
return value;
}
Remember that with an acquire barrier: "Memory operations that occur after the barrier in program order become visible after the barrier. This means we can't reorder memory operations that occur after the barrier to now come before the barrier."
This is how the set() method is implemented:
public void set(final long value)
{
VarHandle.releaseFence();
this.value = value;
}
Remember that with a release barrier: "Memory operations that occur before the barrier in program order become visible before the barrier. This means we can't reorder memory operations that occur before the barrier to now come after the barrier."
We see that the Sequence implementation uses the acquire-release protocol described above to ensure cross thread visibility and ordering.
Aeron Frame Writing Algorithm
From the Aeron Transport Protocol Specification:
-
Write the length of the frame header atomically with a negative value so that space can be padded later on failure.
-
Readers check for a value greater than zero for if the frame is ready to read.
-
Insert a memory ordering store fence, aka release fence
-
Write the remainder of the header fields.
-
Copy in the frame body.
-
Insert a memory ordering store fence, aka release fence.
-
Atomically write the length field with its positive value so readers know the frame is available.
This occurs over a number of classes (Iam not so hot on that codebase), but below we can see an example of the use of store fences in HeaderWriter:
public void write(final UnsafeBuffer termBuffer....)
{
termBuffer.putLongOrdered(offset + FRAME_LENGTH_FIELD_OFFSET, versionFlagsType | ((-length) & 0xFFFF_FFFFL));
VarHandle.storeStoreFence();
termBuffer.putLong(offset + TERM_OFFSET_FIELD_OFFSET, sessionId | offset);
termBuffer.putLong(offset + STREAM_ID_FIELD_OFFSET, (((long)termId) << 32) | streamId);
}
Java Fences
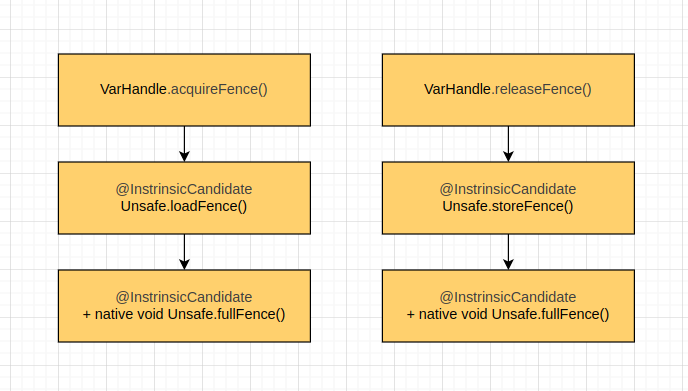
Acquire and release fences are delegated to load and store fence operations in Unsafe.
Links and Resources
https://www.youtube.com/watch?v=qlkMbxUbKfw - Code Blacksmith, Memory Barriers
https://www.youtube.com/watch?v=ZQFzMfHIxng - Fedor Pikus (Mentor Graphics), "C++ Atomics, from basic to advanced. What do they really do?"
https://mechanical-sympathy.blogspot.com/2011/07/memory-barriersfences.html - Martin Thompson, "Memory Barriers/Fences"
https://c9x.me/x86/html/file_module_x86_id_155.html - x86 Instruction set reference
https://www.intel.com/content/www/us/en/content-details/671488/intel-64-and-ia-32-architectures-optimization-reference-manual-volume-1.html - Intel® 64 and IA-32 Architectures Optimization Reference Manual Volume 1
https://www.alibabacloud.com/blog/memory-model-and-synchronization-primitive---part-1-memory-barrier_597460 - Jeffle Xu, Alibaba Cloud blog