Retrieval Augmented Generation
Notes on retrieval augmented generation (RAG) from Anthropic's course on Claude.

Retrieval Augmented Generation
Breaking down large documents which need to be passed to the LLM into chunks so we only send the most relevant pieces. Reduces traffic, latency and costs. Augment the generation of some text with a (pre-generation) retrieval process.
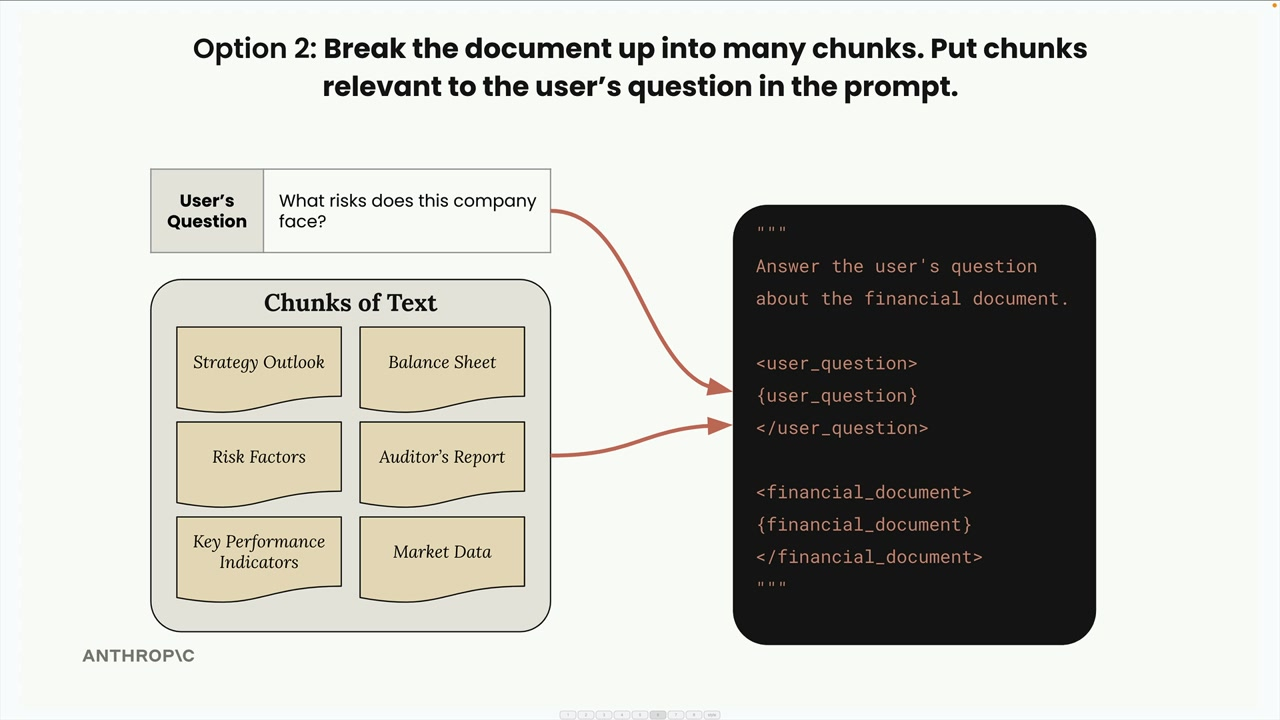
The LLM can then focus on the most relevant content and handle large documents at scale, as well as multiple docs.
Challenges with RAG:
- Requires preprocessing to chunk docs
- Need a search mechanism to find relevant chunks
- You may miss relevant chunks
- Chunking strategy policy
Chunking Strategies
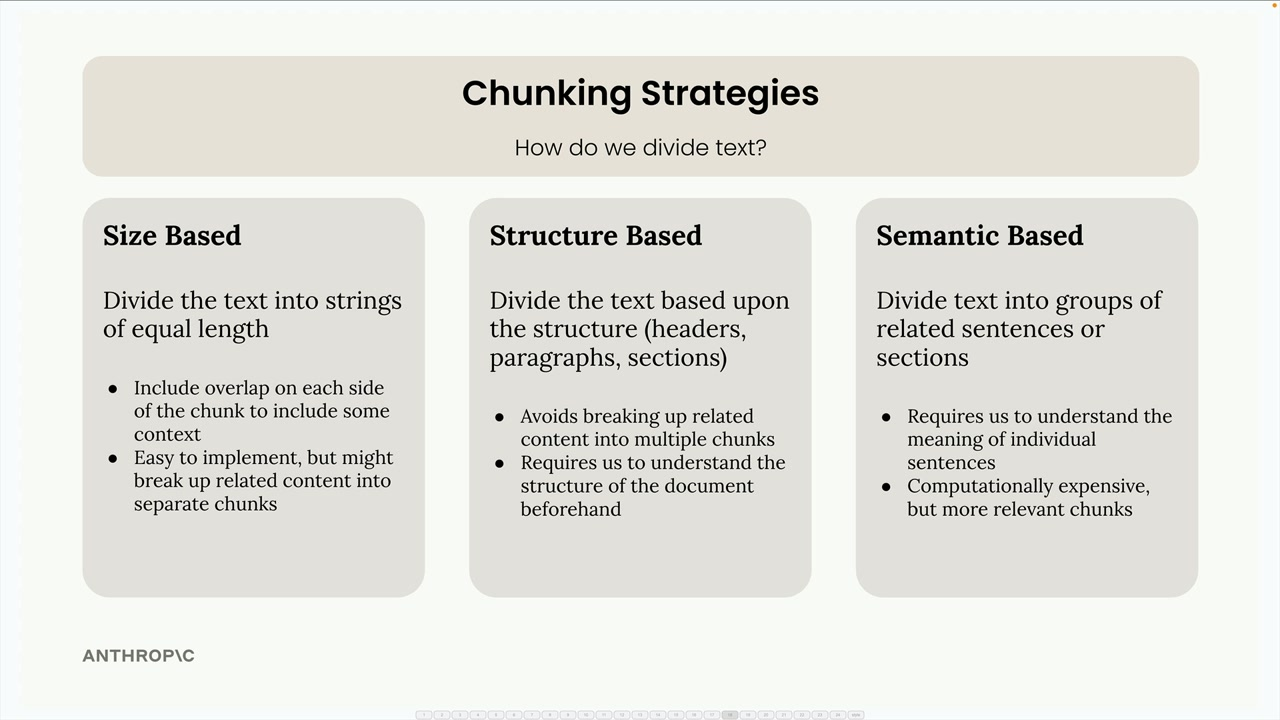
Sized Based
Downsides:
- Cutoff text mid sente...
- Lack of context in each chunk
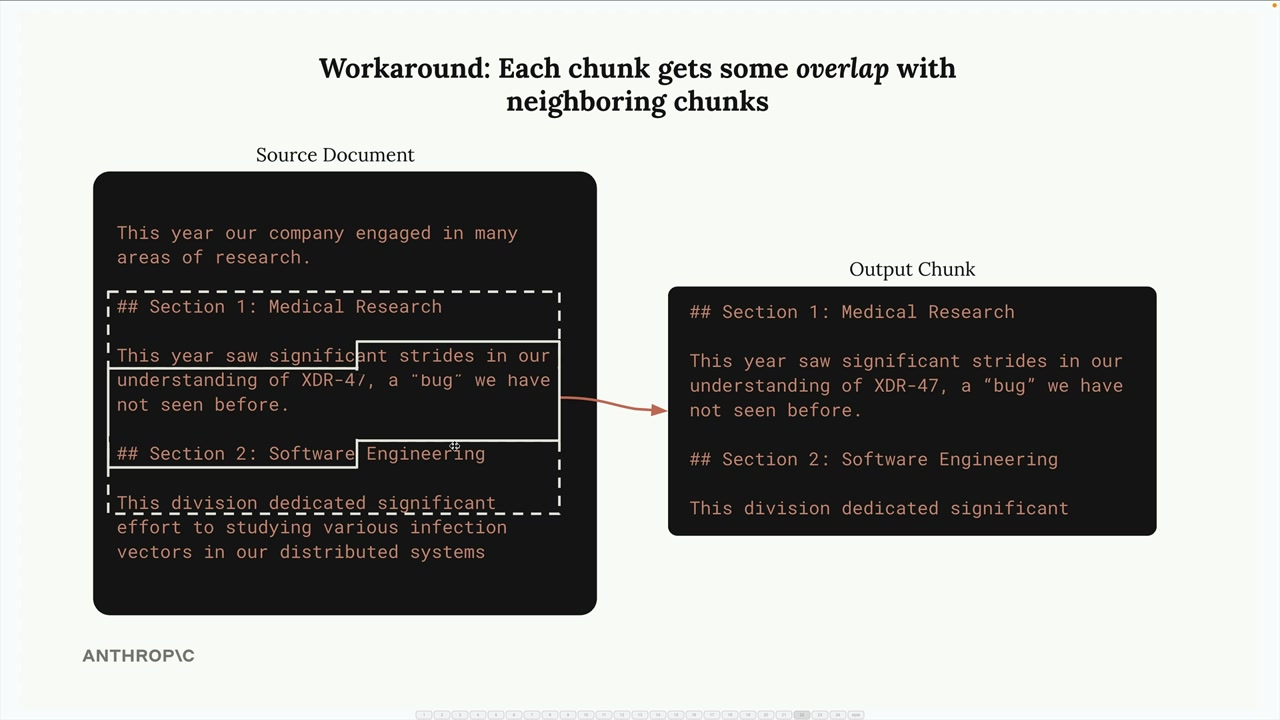
Can overlap chunks:
Structure Based
Using document structure like headers, paragraphs and sections. Good for well formatted documents like markdown (maybe not mine).
Semantic Chunking
Divide text into sentences, using NLP to determine sentence relevancy with one another. Chunks are built up using groups of related sentences.
Sentence Chunking
Split out sentences, add overlap if needed.
Selection Strategy
- Structure based - when you control the document formatting
- Sentence based - middle ground for text docs
- Size based - most reliable, simple for prod use
Text Embeddings
We need to find the most relevant chunks for the user's question. This is typicall done using semantic search:
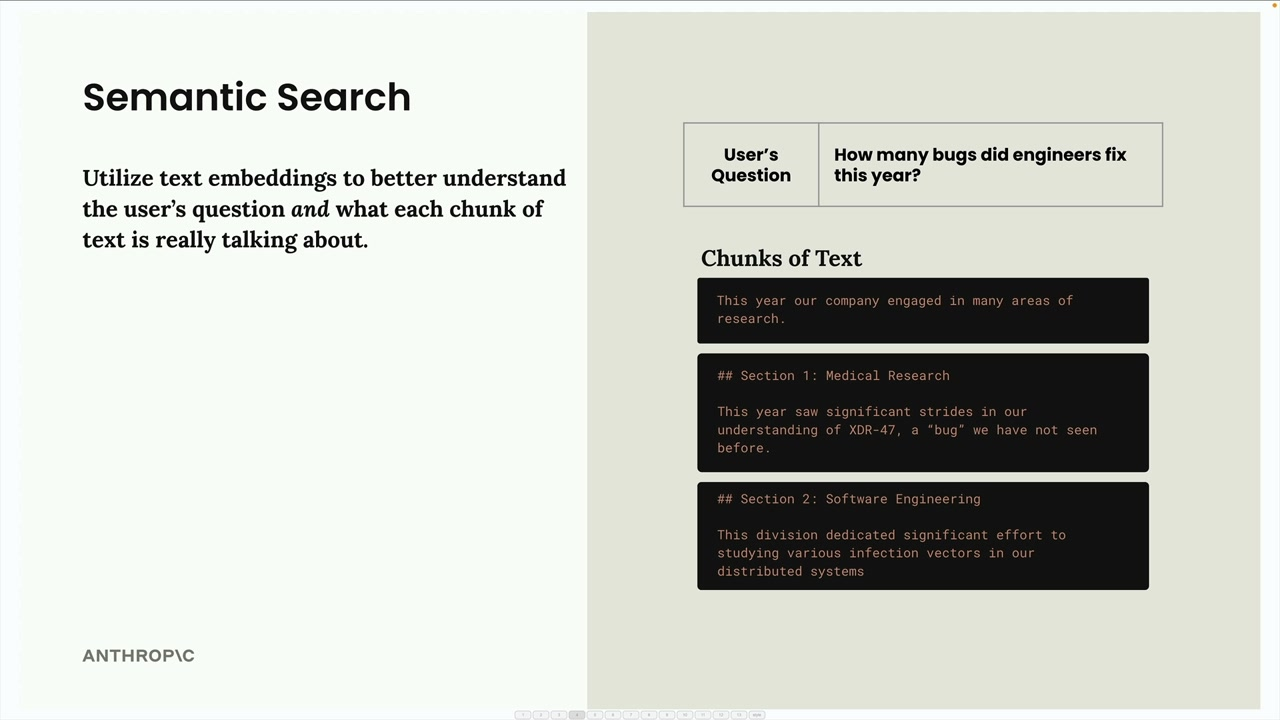
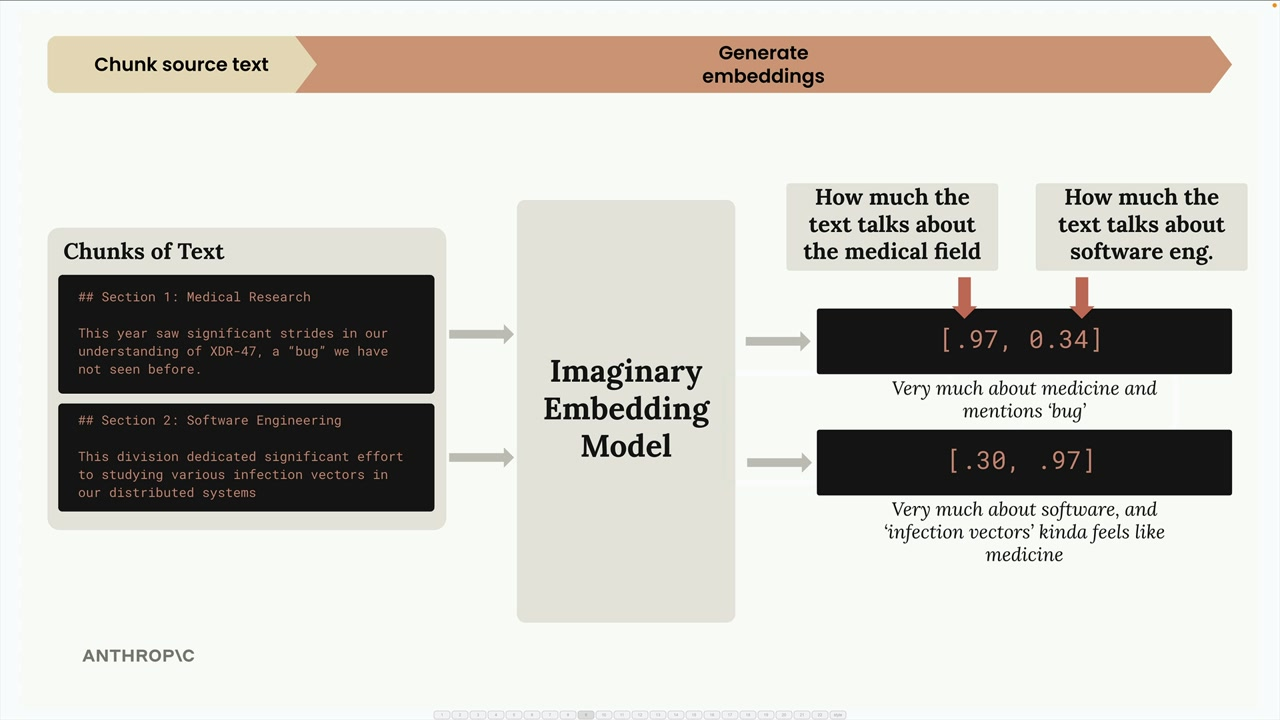
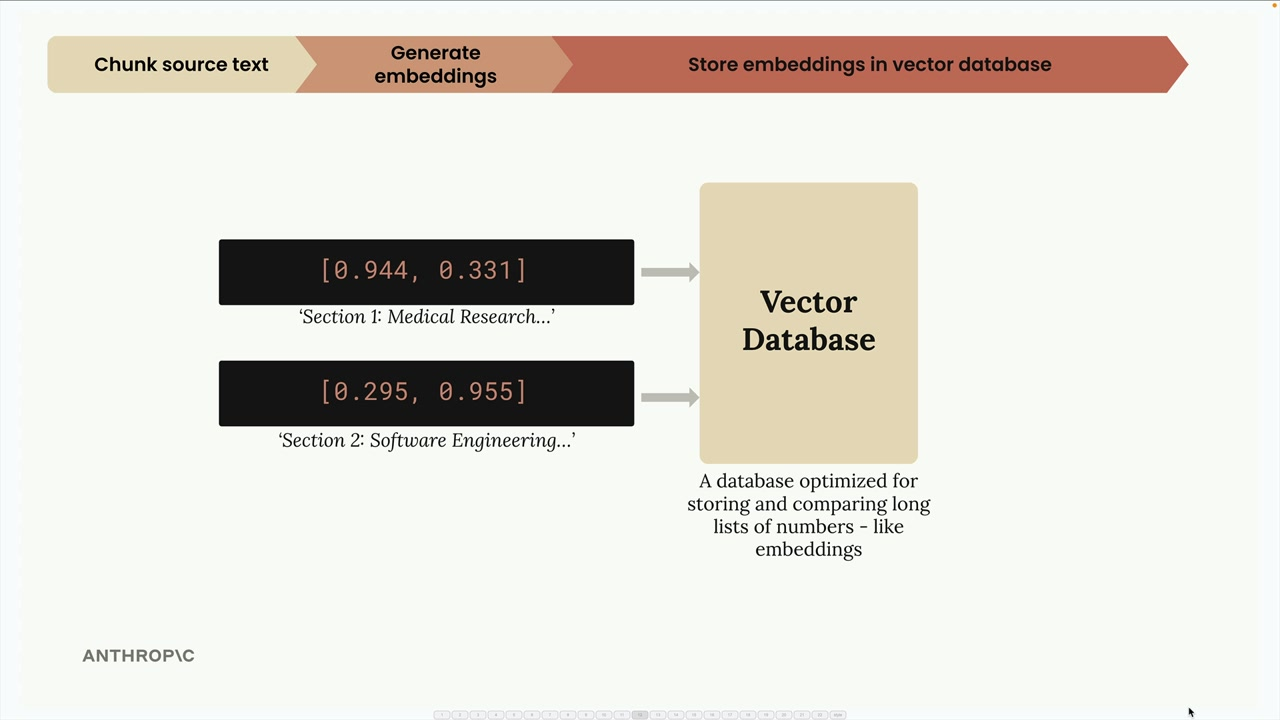
Once we generate these embeddings (for each chunk), they get stored in a vector database.
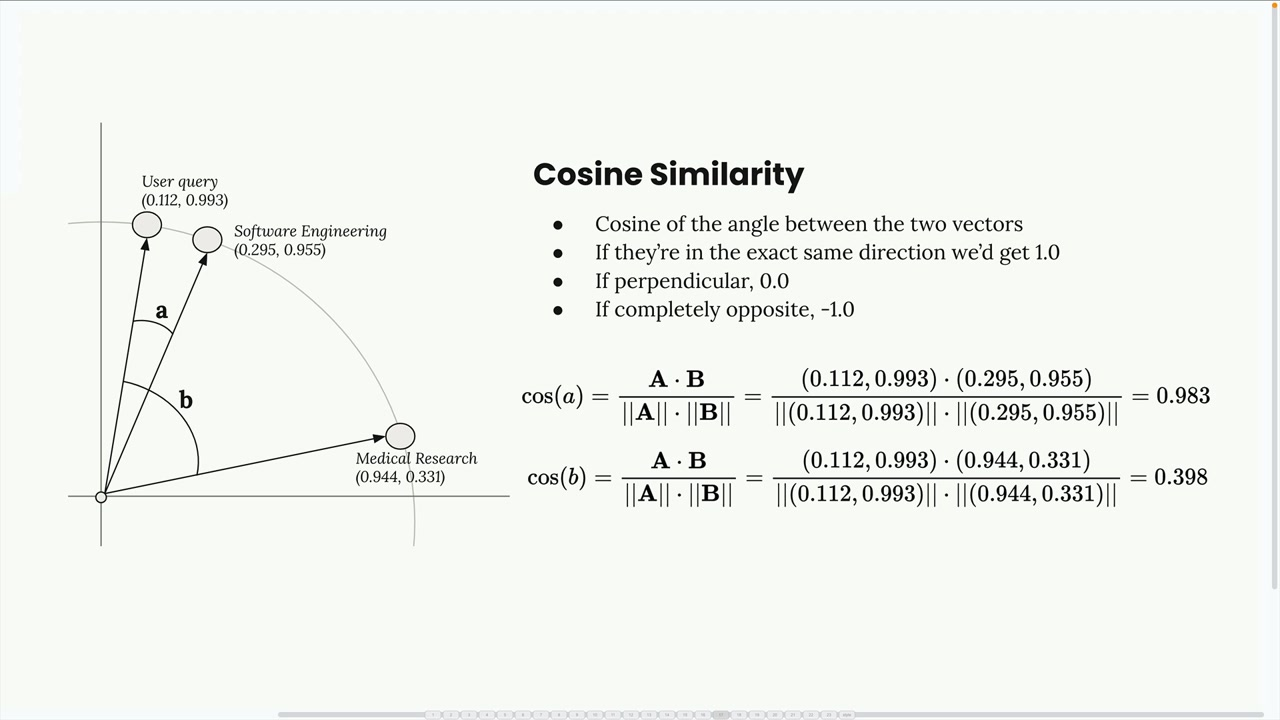
When we get a user query, we generate it's embedding values using the same model as we did for the chunks. We then use cosine similarity/cosine distance to compare the embeddings of the query with those in the vector db (for each of the chunks), in order to find the most similar chunks.
We now have the chunks effectively ordered by relevancy and can combine them into a prompt.
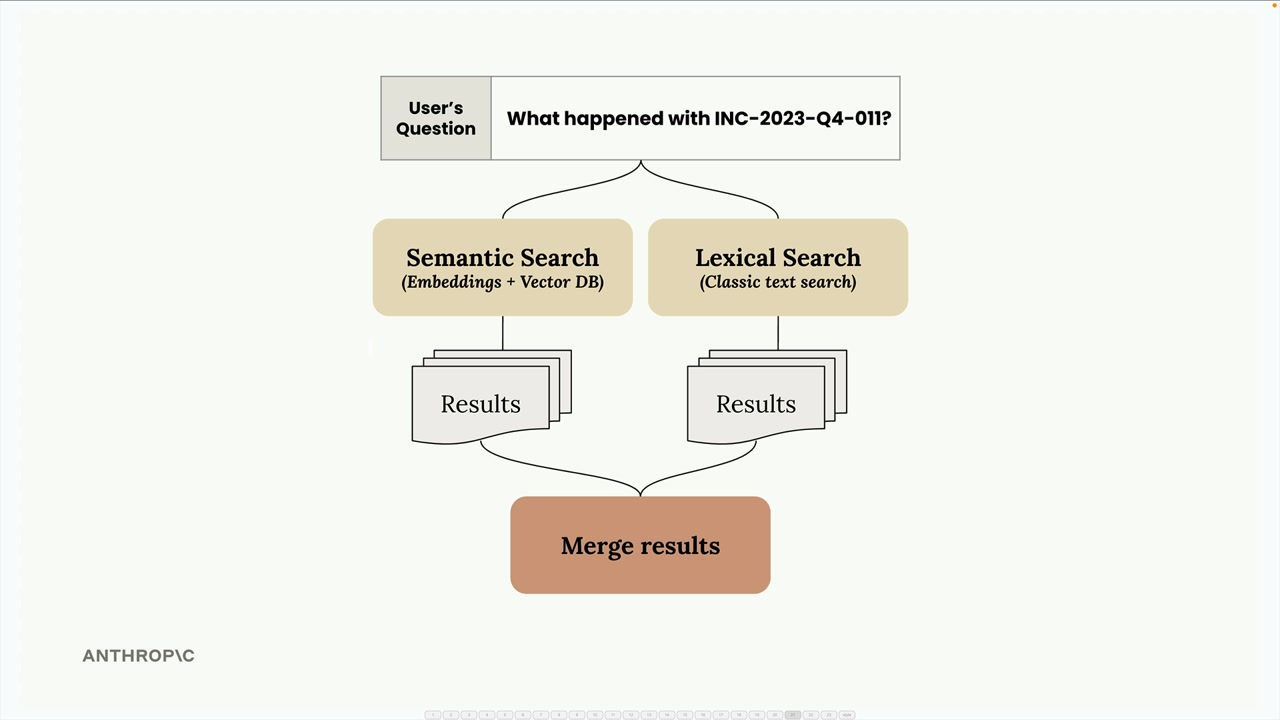
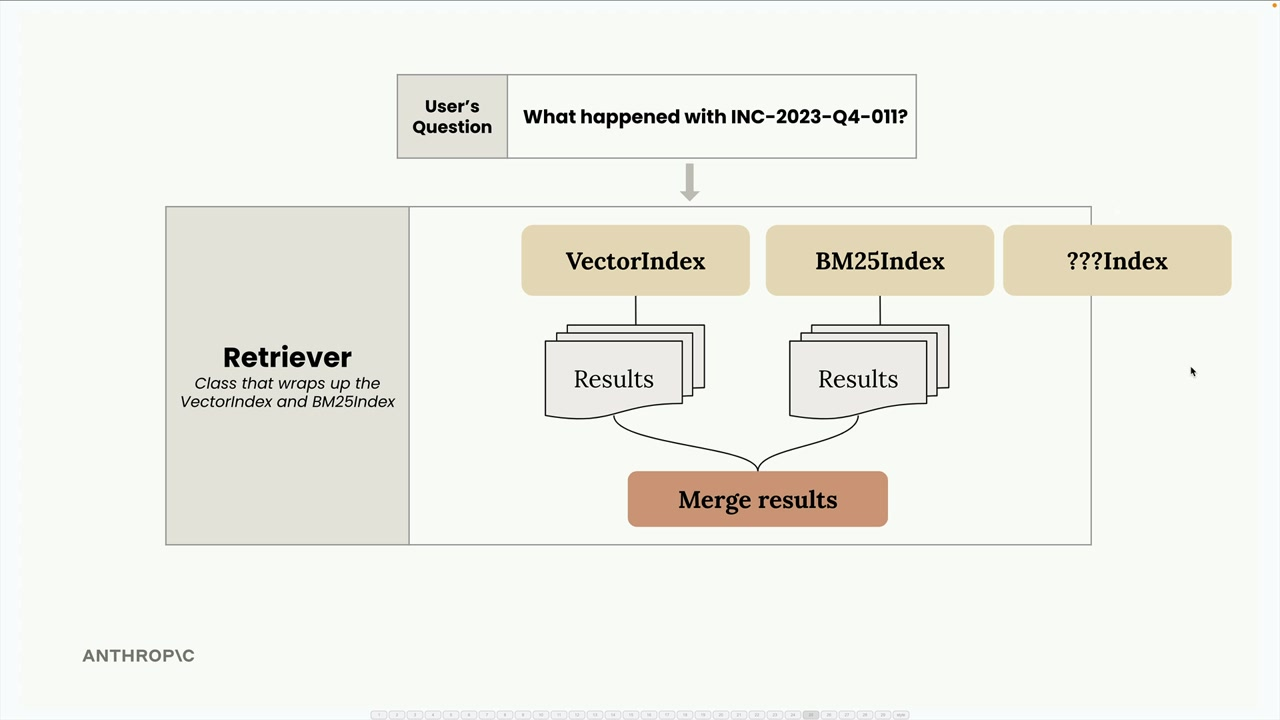
BM25 Lexical Search
WE can combine semantic with lexical search using BM25. We may want to do this because the semantic search is not returning the exact term we are using and so now need to use lexical search.
Reminds me a bit of inverse doc frequency:
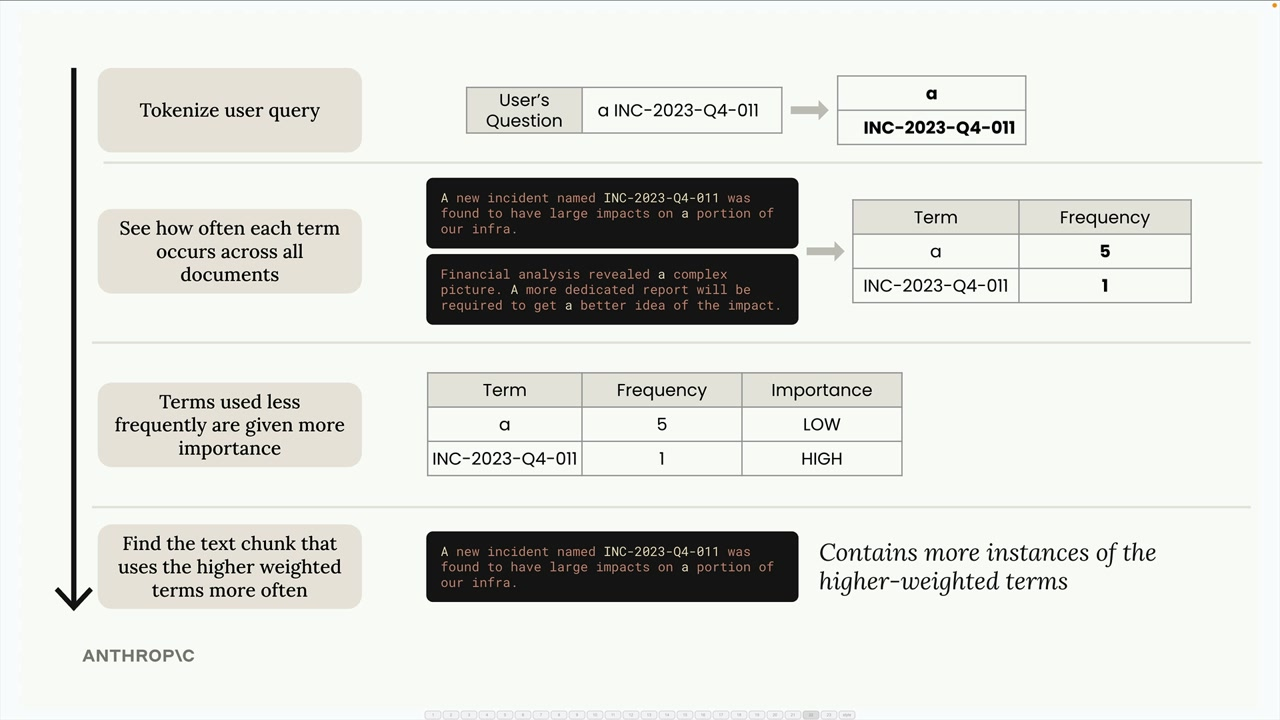
- Gives higher weight to rare, specific terms
- Ignores common words that don't add search value
- Focuses on term frequency rather than semantic meaning
- Works especially well for technical terms, IDs, and specific phrases
However, the scoring mechanism for semantic and lexical search are both different, so we need to handle this. However, this allows us to integrate and normalise other unknown search and ranking methodologies.
Reciprocal Rank Fusion
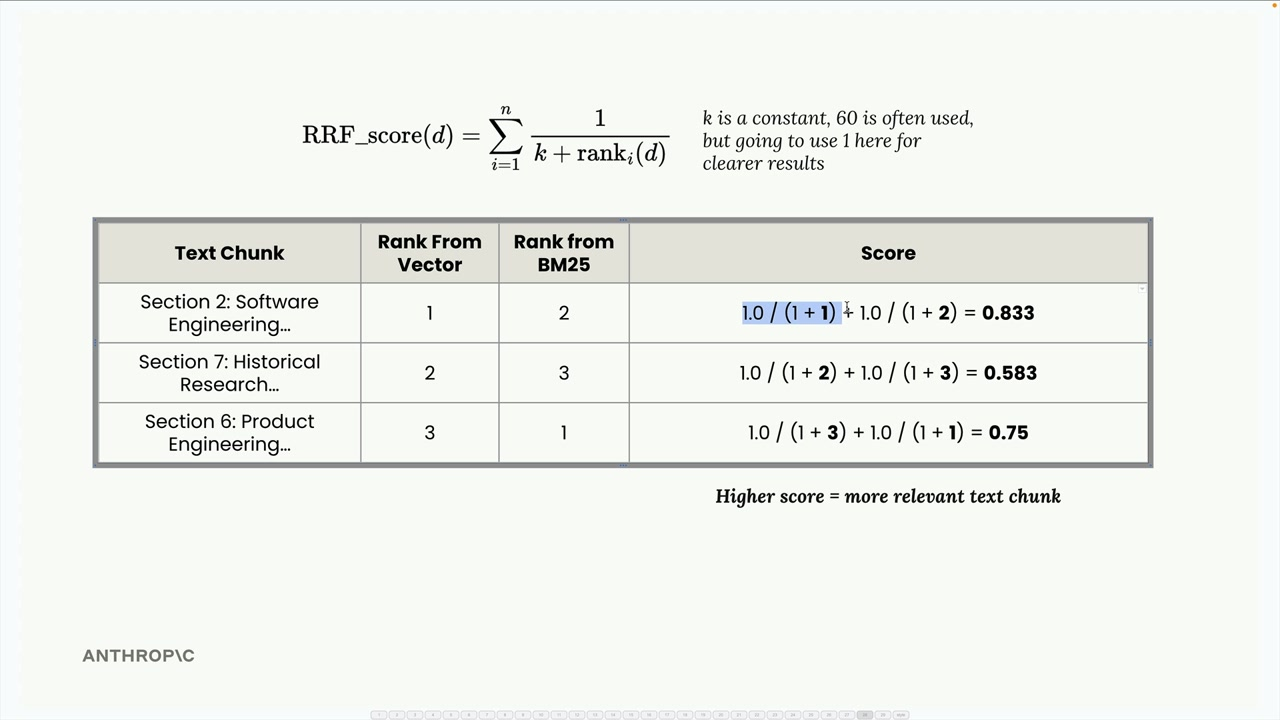
The score is the sum of the reciprocal of each rank for each of the ranking methodologies.
The score is inversely proportionate to the rank - high ranks are bad, low ranks are good.
Re-ranking
Once we have a list of relevant chunks, we use an LLM to rank them again according to relevancy

We trade increased accuracy vs latency and extra API calls.
Contextual Retrieval
When we chunk a document, each piece now lacks context of it's place int he document and how it relates to the document. Retrieval accuracy can go down as context is removed.

We use an LLM to write a snippet which "situates" the chunk into the overall document. This generated context is combined with the original chunk to create a "contextualized chunk", which is used in the vector and BM25 indices.
Large Documents
Provide a reduced set of contexts.
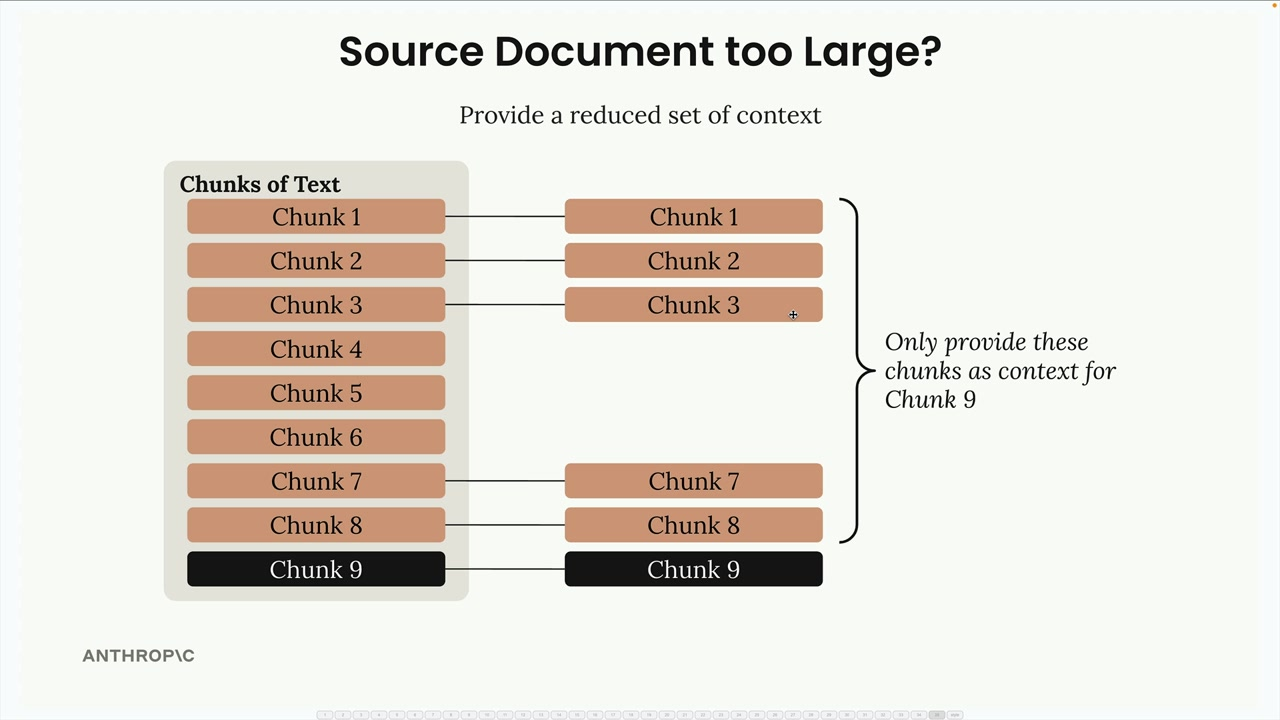
- Some from the start
- Chunks before the chunk you're contextualizing
- Skip chunks in the middle
For example, a contextualized chunk might start with: "This chunk is Section 2
of an Annual Interdisciplinary Research Review, detailing software
engineering efforts to resolve stability issues in Project Phoenix..."
followed by the original chunk text.
This technique is especially valuable for complex documents
where individual sections have many interconnections and
references to other parts of the document. The added
context helps ensure that relevant chunks are retrieved
even when the search query doesn't exactly match
the chunk's original text.