Lessons and Questions from Designing a Distributed Cache
Got Cache<K,V>?

Patterns of Data Usage and Creation
Your patterns of data usage and creation should be identified and used to drive the choices behind your distributed cache.
Patterns of data access and usage can vary drastically even for something that achieves the same outcome.
For example: an AI bulk training workload vs incremental training vs periodic analytics - these can all be used to tackle the same problem, but each will have different patterns of data access and usage.
Bulk AI Training Workload
Largely read dominant, may suit batch read semantics. Turning unstructured data into structured data from potentially disparate sources.
Incremental Training
Involves a write of an entity or some data, followed by a read. Unknown input rate of data. May normalize or snapshot the data periodically instead e.g. add to the model every 1 minute.
You may be conducting training on an initial dataset (that has been structured, cleansed and normalized in advance) and then incrementally training on data that is being sourced by a different pipeline that involves multiple data sources with realtime cleansing and normalization. Something like CDC with Kafka.
Periodic Analytics Report
Largely read dominant, on a known periodic timer. Similar complexities to a real time incremental training data pipeline in terms of needing to get data from multiple, potentially disparate sources.
If your existing patterns are not clear, then it is better to add sufficient telemetry and tracking in order to collect this data.
Where Should Data Live?
One of the best reasons to use a distributed cache is to exploit data locality for speed. In the same way CPUs and modern hardware exploit data locality, distributed caches can take advantage of keeping data in different locations for speed of access - this can be geographical locality (e.g. you have a 1 node for each of Asia, Europe and the Americas) and locality within a node (e.g. you can store data on disk or in memory).
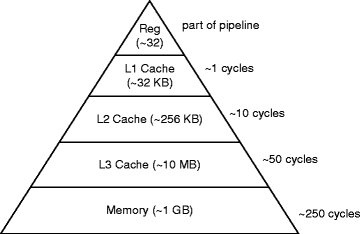
Source: Pingali, K. (2011). Locality of Reference and Parallel Processing. In: Padua, D. (eds) Encyclopedia of Parallel Computing. Springer, Boston, MA. https://doi.org/10.1007/978-0-387-09766-4_206
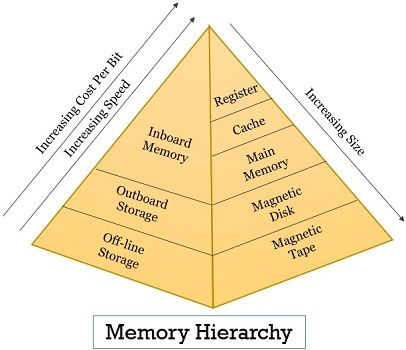
Source: BinaryTerms
Geographical Locality and Latency
Keeping data geographically colocated offers significant speed advantage. We don't need to look at dark fibre latency matrices, we can even see from a simple latency heatmap of ping times between cloud providers (AWS and Google) how much latency is saved by keeping data local:
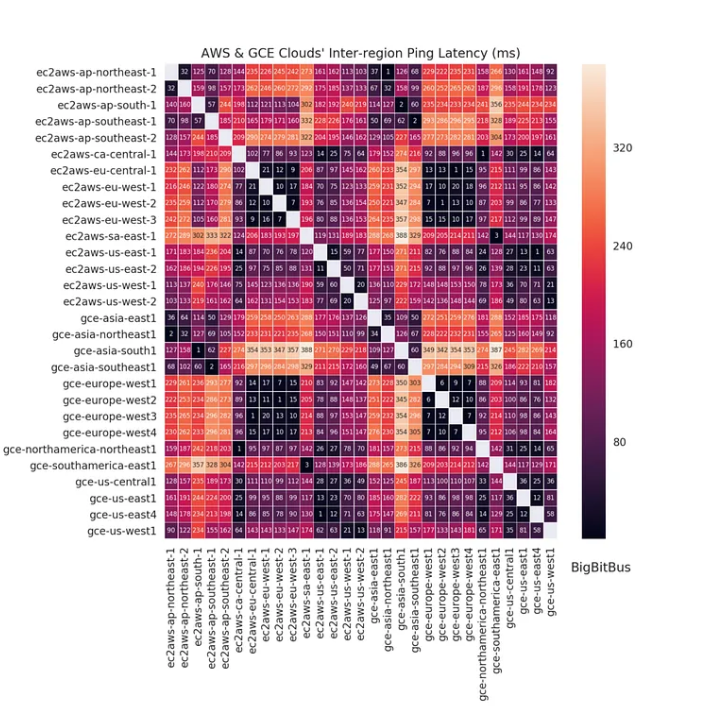
Source: Sachin Agarwal/BigBitBus, Medium
The main way we can decide where a piece of data lives is using the key.
The Key
We can use the bit pattern of the key to decide where a particular value lives.
An important question to ask is, what part of the key should I use for the hash? This plus the details of our hash calculation are critical tools in utilising locality.
We can use custom hash calculations to make items live together in the same place (the output of a mapping function places items in the same location) or make them uniformally distributed (the output of the mapping function distributes items evenly across all available locations).
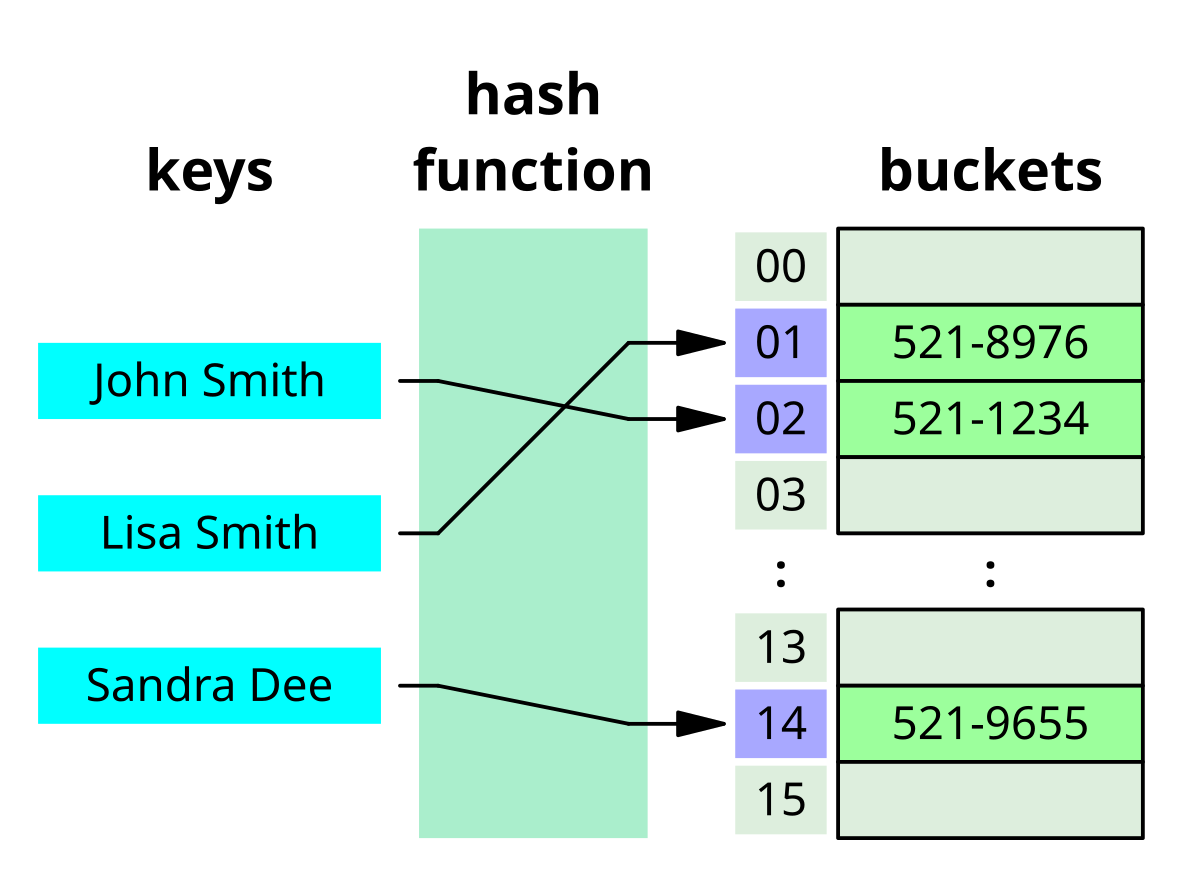
Source: WikiPedia
Fundamentally, we're trying to exploit varying levels of entropy within the the bitset that represents the key.
Broadly speaking, if we want particular bits of data to cluster together then the way their hashcode maps to location depends on having an area of the key's bitset that is common (low entropy, low randomness, not uniformly distributed).
Example:
Key = LN_1
Key = LN_2
Key = NY_1
Key = NY_2
We can see that the first 2 characters offers us a way of collocating data items.
If we want particular bits of data to be evenly distributed then the way their hashcode maps to location depends on having an area of the key's bitset that displays high entropy i.e. high randomness or uniform distribution.
Example:
Key = LN_1456
Key = LN_2387
Key = NY_5689
Key = NY_1209
We can see that the last 4 characters may offer us a way of distributing data items evenly.
Column vs Row Format
When Should I Use a Row Store?
-
Row if your consuming system uses all the elements of the rows, or consumes materialized views.
-
Row if the operations being done are all row dependent e.g. qty x price
-
Row for horizontal sharding.
When Should I Use a Column Store?
-
Column if you are projection heavy or need to consume a subset of the available columns.
-
Column if you are doing operations based on past values of the same column or a sliding window calculation e.g. rolling average.
-
Column for vertical sharding.
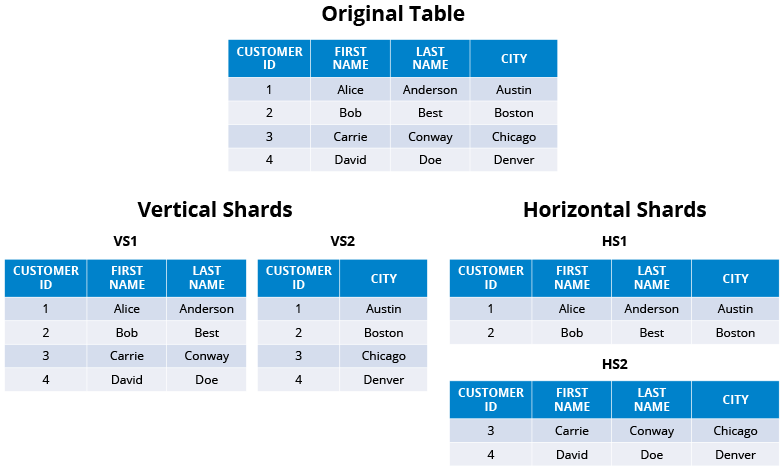
Horizontal vs Vertical Sharding - Source: Hazlecast
You can shard by column or row and place those items most accessed together in the same place to exploit locality.
Other Common Issues to Consider
Transport layer - TCP vs UDP
Ownership and dynamic number of owners
Cluster late joiners
Level of consistency and high availability
Distributed vs replicated
Changing Strategy with Time
Can we vary the strategy over time to optimise for our workload?
We can abstract the storage and access strategy (so a user doesn't even know) through a common access layer which is effectively a public API.
Change the key calculation strategy and change the way data is stored. Portions of the data can be stored in row format and other subsets in column format.
interface KeyStrategy<T> {
int getKey(T o);
}
enum StorageOrientation{
ROW,
COLUMN
}
class KeyingOrientationStrategySnapshot<T> {
final KeyStrategy<T> keyStrategy;
final StorageOrientation orientation;
final long startSequence;
final long endSequence;
}
If a particular subset of the data is being accessed in a projection heavy manner with the same fields then that portion of the data (rows and specific columns) can be materialized for the user.
Determining the turning points for performance benefit - when does it become more advantageous for us to shift strategy so as to achieve a positive expected benefit?
Automation Challenges
How to stop ownership and strategy from changing too much - overhead of reoptimisation.
How frequently should you optimise and redistribute data if needed? Or, what heuristics should drive any reoptimisation process?
Storing the correct access strategy for different periods of time and verifying data integrity under varying access and storage strategies.
Determining Factors for Comparing GraphQL vs RDMS vs NoSQL
-
Structured vs unstructured data - the less structured your data the more useful a document store can be.
-
The level of PATCH, whether you need projections (SELECT) etc.
-
The more materialized your view, then document store (faster but higher baseline memory usage) or relational (slower but much lower baseline memory usage).
-
The less materialized and the more dependent upon projections or joins, then maybe GraphQL.
-
The more you follow a microservice pattern like a database per service, the more useful something like GraphQL can be.
Using AI to Optimise and Classify Cache Behaviour
Feature Engineering for AI
Feature engineering for AI based optimisation on caches
- For data distribution (using AI to determine optimal hashing strategy and therefore the locality of the data)
- For deciding when to optimise (prediction)
- For outlier or anomaly detection (tracking and prediction)
- For classifying data access patterns (possibly community driven)
Challenges of Using AI
-
Non persistent and changing patterns of data access: consider what should happen when you get a period of bursty behaviour or a period of very heavy usage followed by a return to "normality".
-
Large data sets which due to their size may not ever show a positive expected gain from optimisation: only a portion of the dataset may benefit from optimisation, namely the most frequently accessed.