How is Bigtable Implemented?
How is Big Table implemented?

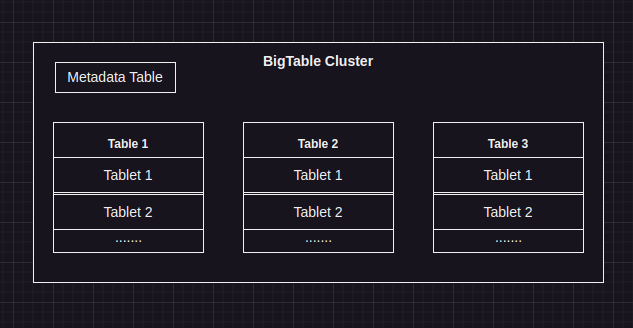
Main Components

There can be multiple client libraries connecting to a single master server. The master server assigns tablets (groups of rows) to specific tablet servers. The master is also responsible for handling cluster like features like the addition or removal of tablet servers, load balancing across tablet servers, schema changes and any necessary garbage collection from GFS.
Tablet Location
Tablet servers are responsible for managing sets of tablets (rows). Each tablet server handles read and write requests for it's set of tablets (rows). The tablet server is also responsible for splitting up large tablets. Clients communicate directly with tablet servers rather than with the single master.
Each table in a cluster is made up of multiple tablets.
class TabletLocationKey {
T tableId;
int endRow;
}
The metadata table stores the location of tablets using the table identifier and the end row for that tablet. The client library uses caching for the location of tablets, with fallback being a lookup.
Tablet Assignment
The master is responsible for tablet assignment and managing unassigned tablets - if a tablet is unassigned, once a tablet server with sufficient capacity becomes available, the tablet is assigned too it.
The master uses Chubby to aquire locks for a tablet server using the file based namespace under a servers directory. The master also uses this directory for service discovery of new tablet servers. To make sure tablet servers are up and working, the master polls them for the status of their lock. For the case where the tablet server has lost it's lock, but still replies to the master's requests (no partition), the master will go and try and get that lock from Chubby.
This caters for the scenario where the tablet server has lost it's connectivity to Chubby or is down. The master then deletes that faulty tablet server's lock file, and it's assigned tablets become unassigned (which the master is also subsequently responsible for assigning).
Master startup
- Get the master lock from Chubby
- Scan the servers folder for tablet servers
- Ask each tablet server found what subset of tablets they're responsible for
- Load the metadata table to find the universe of tablets
Tablet Splits
The tablet server decides to do a split, updates the metadata table then notifies the master of the split.
Tablet Serving
The most recent commit is stored in memory in a sorted buffer, with GFS backing persisted tablet state - older updates are stored in sequenced SSTables. There is also a commit log with redo records (write ops go into the commit log before the in memory buffer).
There is a mapping of tablets to SSTables in the metadata table, which allows for tablets to be restored from SSTables. The system uses redo-points from which recovery can occur i.e. load snapshot state from the redo point and then replay.
Reads may involve a combo of the in memory buffer and the sequenced SSTables in order to get all rows needed.
Compaction
When the in memory buffer reaches a certain threshold, compaction occurs - it gets converted to an SSTable and then written out on GFS. A merging compaction is one that combines the memory buffer with existing groups of SSTables.
Major compaction - re-write all SSTables into a single SSTable, so that there is no deletion info or deleted items. Occurs periodically.
Refinements
- Columns are grouped into locality groups of the same type.
- Locality groups can be compressed.
- Bloom filters are used - store the hash of the object in memory for faster checks of whether the data might exist ("might" due to collision risk - two unequal objects can produce the same hashcode).
- Use of a single, co-mingled commit log.