Basics of CPU Caches
Some notes on the basics of CPU caches - covers locality, write policies, hierarchy and inclusion policies.

I was dusting off the old Patterson and Hennessey when I found some great Youtube videos from BitLemon.
CPU Caches TLDR
Let's say we've written something like a game or a trading system which has entities which encapsulate state. This state is in main memory or RAM.
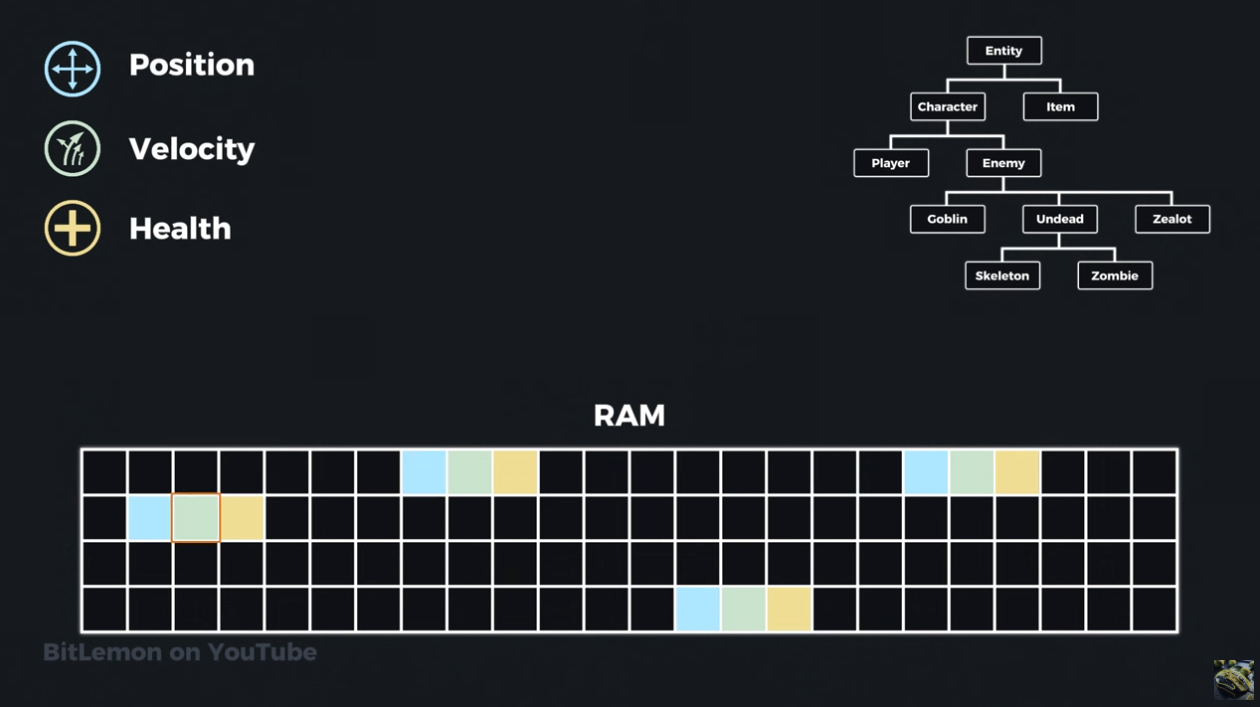
When we want to access a particular element of the state, say the position, across all entities, we end up with a very choppy style of read access which is not mechanically sympathetic to the way the CPU and cache work.
This is because of a common optimization technique called pre-fetching which relies on spatial locality and sequential access - there is an assumption that we will be accessing nearby memory locations (or we will be accessing memory in a sequential manner) so those are pre-fetched into the CPU's cache e.g. we access address 1 and pre-fetch addresses 2,3,4,5,6 and 7 in the hope that they'll be accessed next by the program being run - we want to keep them close to the CPU in cache to reduce access time and therefore offer better performance.
When this doesn't occur and instead we want to access say address 128 then we get a cache miss because the value at that address is not in the cache.
Why Spatial Locality and Sequential Access?
The reason CPUs operate on the assumption of spatial locality and sequential access is because it is kind of the only assumption that's reasonable to make in order to increase performance via the concepts of caching and "pre-emptive/speculative work".
This is why we ideally write our code to be mechanically sympathetic - the CPU and things like hardware based pre-fetchers can not adapt their logic or architecture dynamically (until someone teams deep learning with FPGAs perhaps, but then what about the FPGA's pre-fetcher?!) to accommodate the way you want to write code, so we instead try to write code and design systems in a way which leverages the way the hardware operates.
Temporal Locality
By keeping the data close to the CPU in a fast cache we also better exploit temporal locality (we tend to access the same bit of memory repeatedly, there is high serial correlation in the access pattern).
Data Oriented Approaches
An alternative is to use a data-oriented approach where we try and store similarly accessed elements close by to one another:
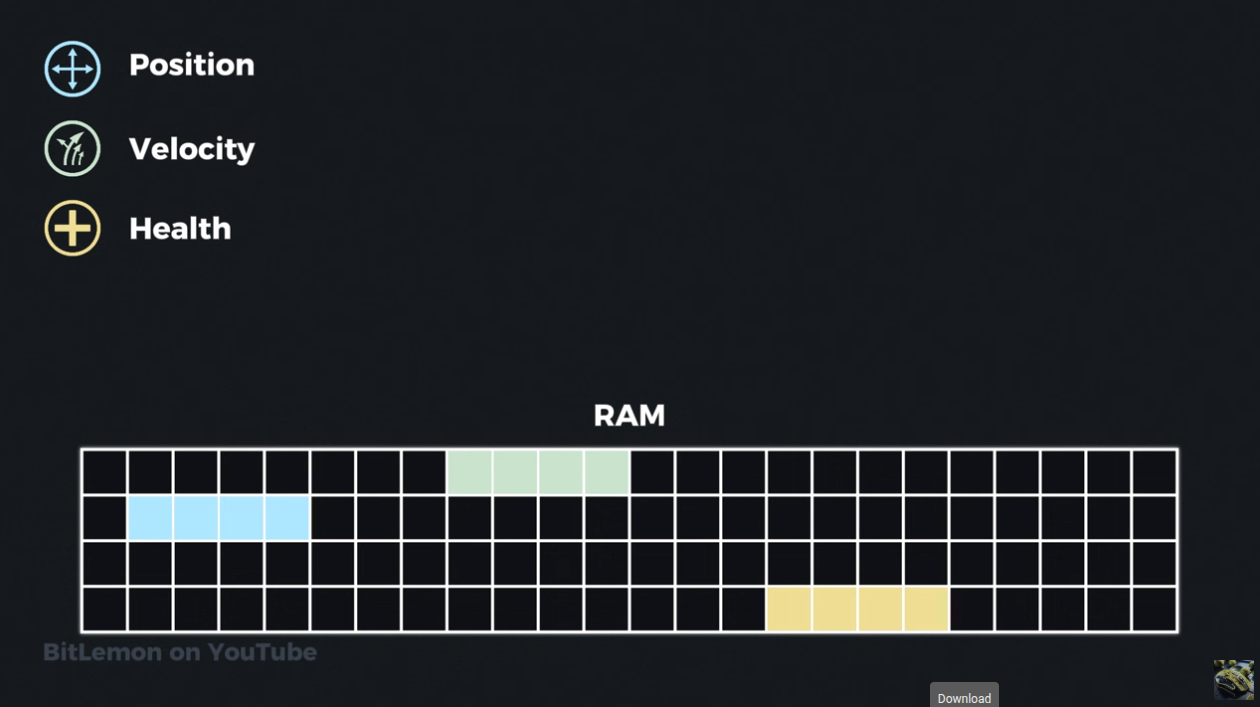
This allows for more efficiently updating similar elements of state.
A data oriented approach increases the amount of cache hits (the data is already in the cache) if your access patterns match.
Cache Lines and Structure
Caches are divided into chunks of memory called a cache line (64 bytes in most architectures). Each line is stored with a tag which is the "rough" address from main memory/RAM from which the cache line originated.
You can think of a cache as a Map structure from which the CPU can do a lookup.
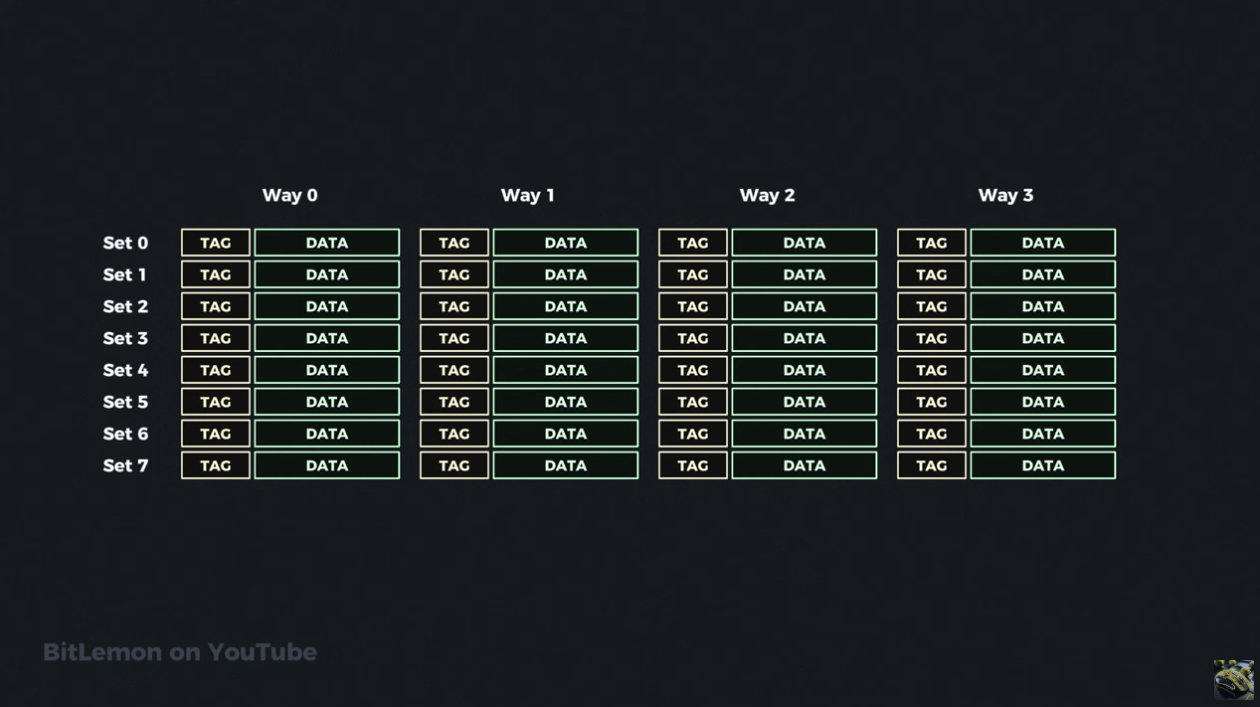 N-Way Set Associative Cache
N-Way Set Associative Cache
The sets is the number of "buckets" we have in our map - say we have 8 sets as in the above example, then we're doing something like hashcode(address in RAM)%8 to determine which set a particular cache line should belong too.
The "ways" or level of associativity tells us how many items or cache lines we can store in each set of the cache (the size of the cache is limited so we can't just use a List or a Tree structure like we would in code).
Once we know the set a line belong to (based on the memory address) we need to put the cache line into it's cache set. Each item you put into a cache set takes up the next available location - this is linear probing (a collision resolution technique).
There are various other probing techniques which can be used to determine the location of an item/cache line within a set - their success and selections depends on the level of entropy we see in the relevant portion of the key (the memory address in our case) and access patterns.
Writing and Reading from CPU Cache
At a high level, when we put something into the cache or want to get something out, we are making those requests using a memory address.
If we represent that memory address in binary, then we can break down different ranges of those bits to be:
- Our tag (used for equality checks when we do a lookup)
- Our set index/identifier (the bits we will use to determine the set)
- An offset (used for reads - once the cache line is provided the offset is used to determine the offset within the cache line of the data we are looking for).
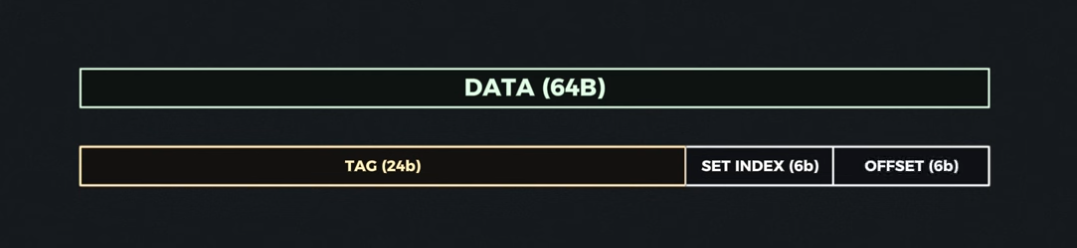 Source: BitLemon, YouTube
Source: BitLemon, YouTube
Dimensions of Cache Types
Fully Associated Cache - has only 1 set, lots of "ways" or locations
Direct Mapped Cache - has lots of sets, only 1 "way" or location per set
Cache Replacement Policies
When we want to put something into the cache but it is full, we need to decide what data to evict in order to do so.
There are a number of policies:
- LRU - Least recently used
- LFU - Least frequently used
- RAND - Random replacement
- FIFO - First in, First Out
Cache Write Policies
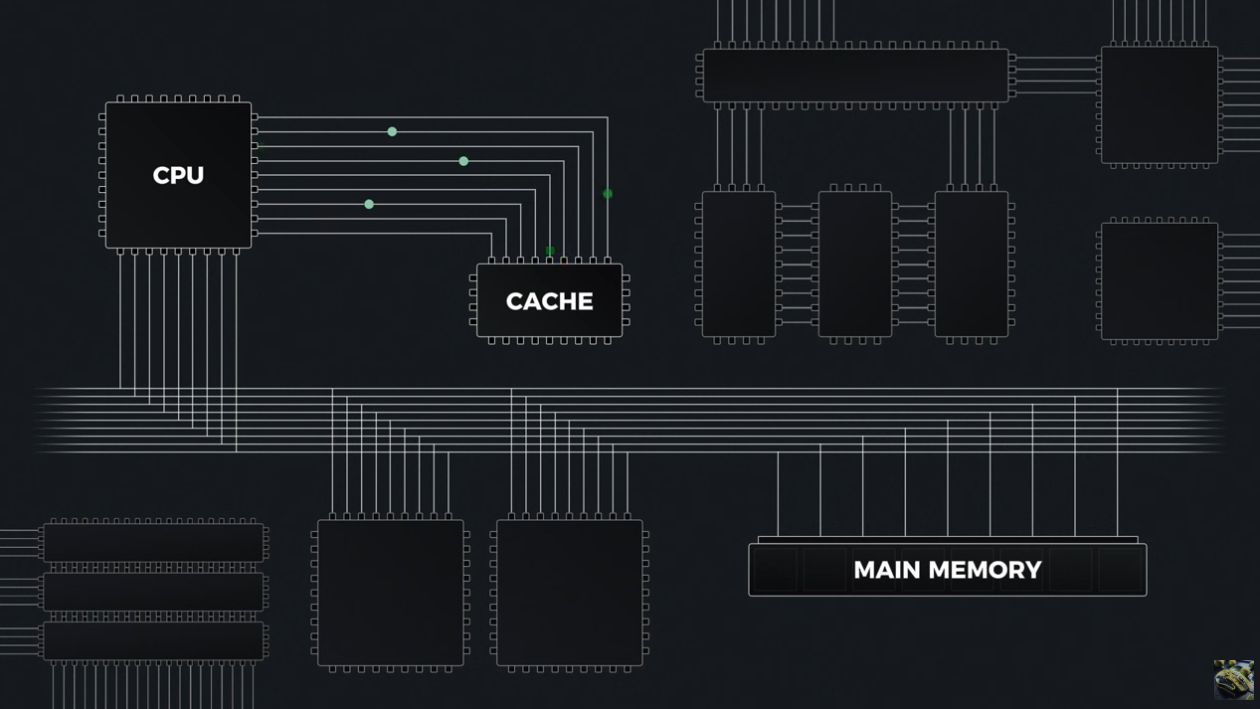 Source: BitLemon, YouTube
Source: BitLemon, YouTube
When we write to the cache, the main memory may still have outdated information which is accessible by other CPU's which leads to incorrect results and inconsistency.
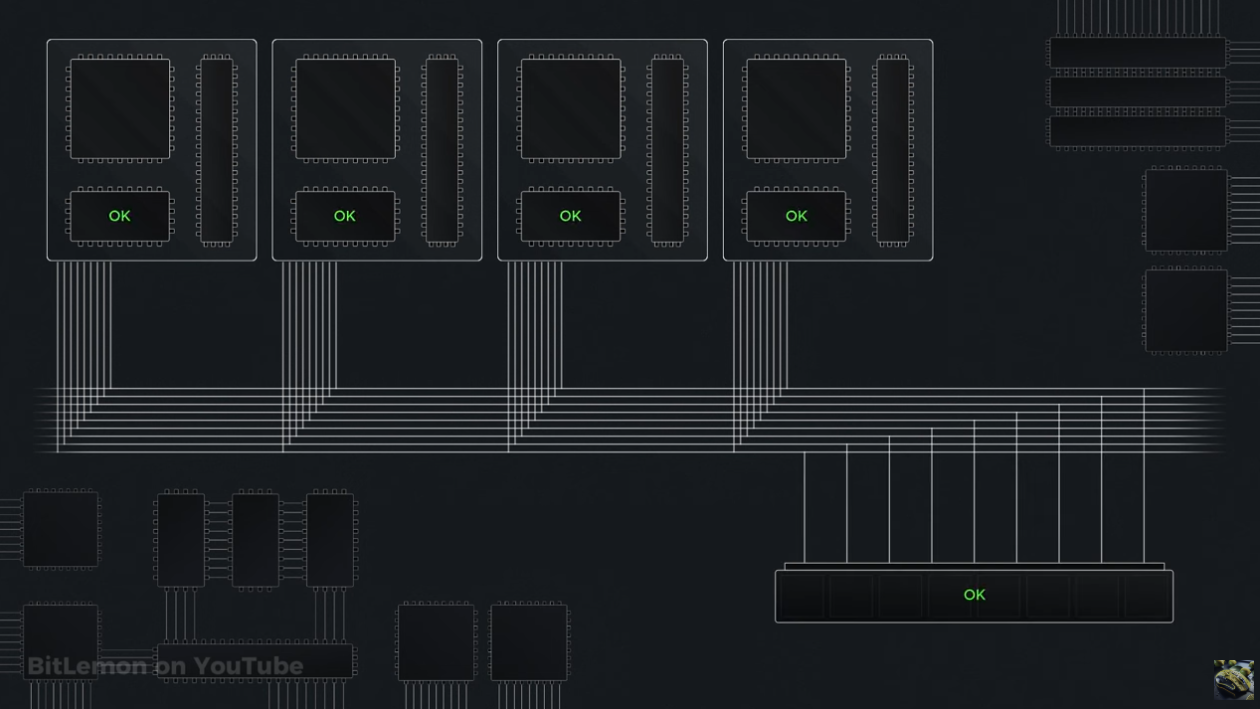 Source: BitLemon, YouTube
Source: BitLemon, YouTube
This is further complicated in multi-CPU/multi-core systems where one CPU can write to it's own cache, leaving the copies in other CPU's outdated and stale (as well as the value in main memory).
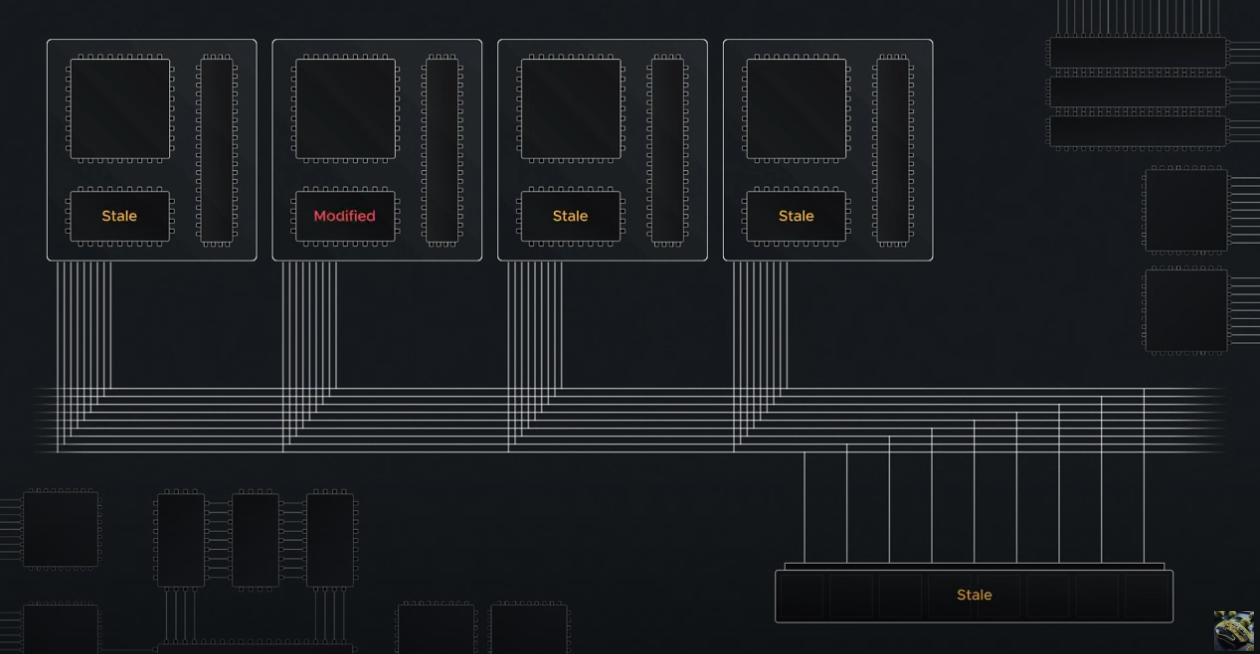 Source: BitLemon, YouTube
Source: BitLemon, YouTube
Write Hits
Write hits occur when we are writing to something which is already in the cache.
Write Through
We update the backing memory at the same as the value in our cache. Slower cache writes, more memory bus traffic.
Write Back
We delay writing to the backing memory until some other time and only update the value in our cache. The write occurs on certain events like cache eviction or the request of a cache flush.
Multiple writes to a single cache line can be combined into a single write to main memory. Faster cache write operations and less memory bus traffic.
More complex cache management logic - data loss possible whilst the data has not been written back to main memory.
Dirty Bit
A bit in the cache line to indicate whether it's been modified since it was loaded from main memory.
If the cache line has not been modified, then it is eligible for eviction if needed as the value in cache is the same as in memory.
If the dirty bit is 1 then it needs to be written back to main memory before it can be eligible for eviction.
Write Misses
Write misses occur when we are writing to something which is not already in the cache.
Write Allocate
We write the data into the cache. If we use write-through then the data is also immediately written to main memory. If we use write-back then the dirty bit is set to 1 - this then relies on cache eviction or cache flush to ensure the data is written to main memory.
Potentially can cause cache eviction of items which are more frequently used than the one being written - cache pollution.
No Write Allocate
We write directly to main memory, skipping the cache entirely.
Avoids the eviction and loading of data into the cache that we can see with write-allocate. Prevents infrequently accessed items from being in the cache.
Good for scenarios where data is written once and then not frequently read.
Bad for scenarios where data is both written and read as will cause cache misses.
Write Back and Write Allocate
Write to cache on write misses and update backing memory async on write hits.
This combination is optimised for cache utilisation and minimise memory bus traffic e.g. L1 CPU cache with frequent read and write operations.
Write Through and No Write Allocate
Write to backing memory and cache on write hits and only to backing memory on write misses.
This combination is optimised for data consistency - useful for logging systems, data is written once but not likely to be accessed soon, so caching is less useful.
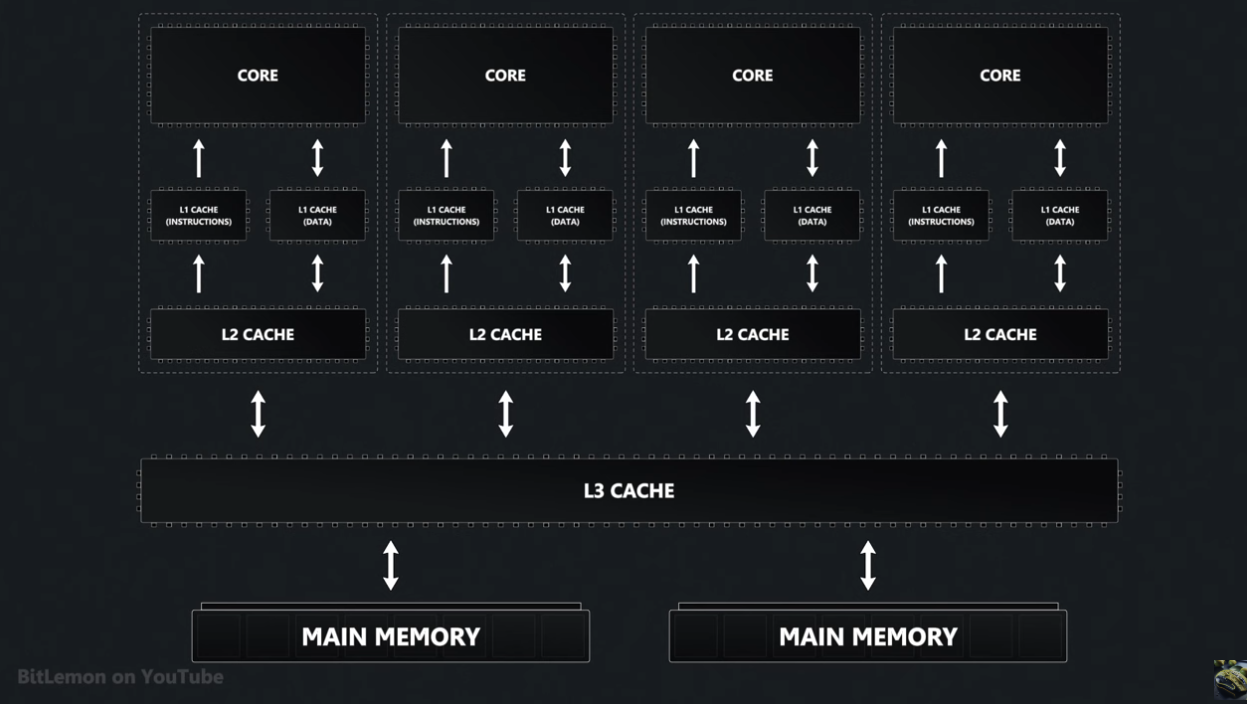
Cache Hierarchy
CPU's employ a hierarchical cache system where caches closer to the CPU are smaller and faster than those further away:
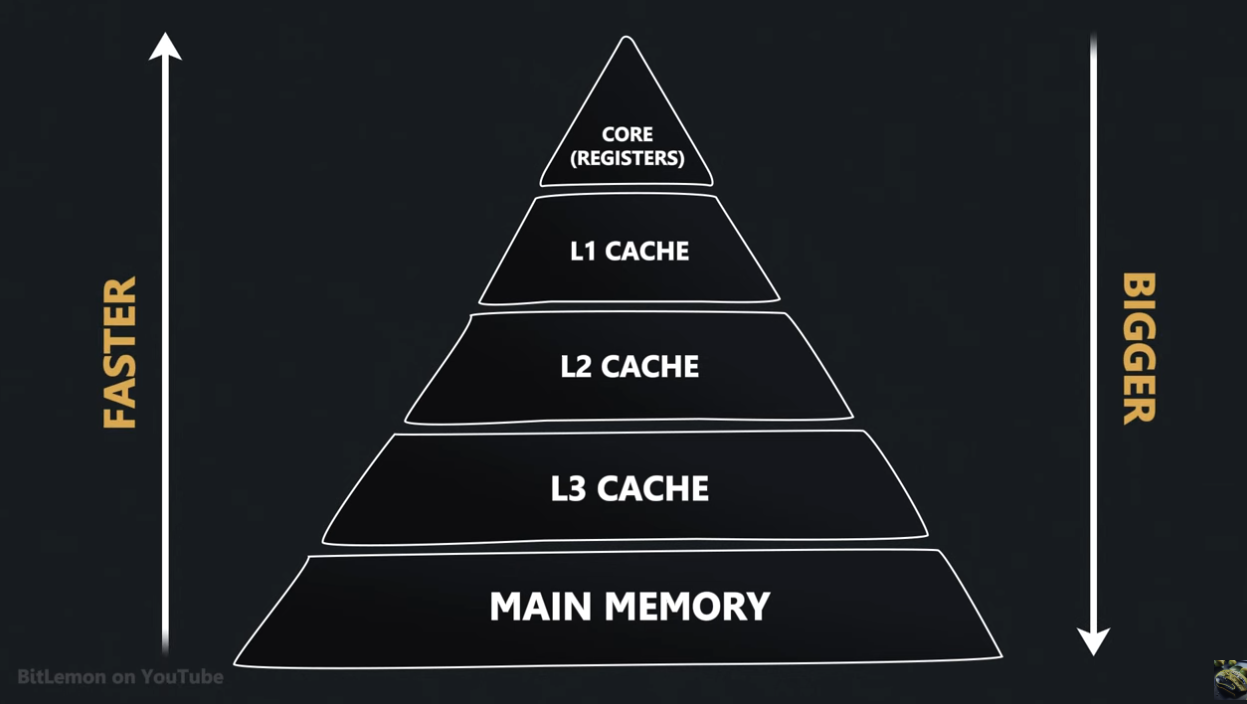 Source: BitLemon, YouTube
Source: BitLemon, YouTube
The L1 cache is divided into a data cache and one for instructions.
L2 is unified - it contains both data and instructions, dedicated to a single core.
L3 allows sharing across cores.
 Source: BitLemon, YouTube
Source: BitLemon, YouTube
As we go from L1 to L3, the size and associativity increases - so does the latency.
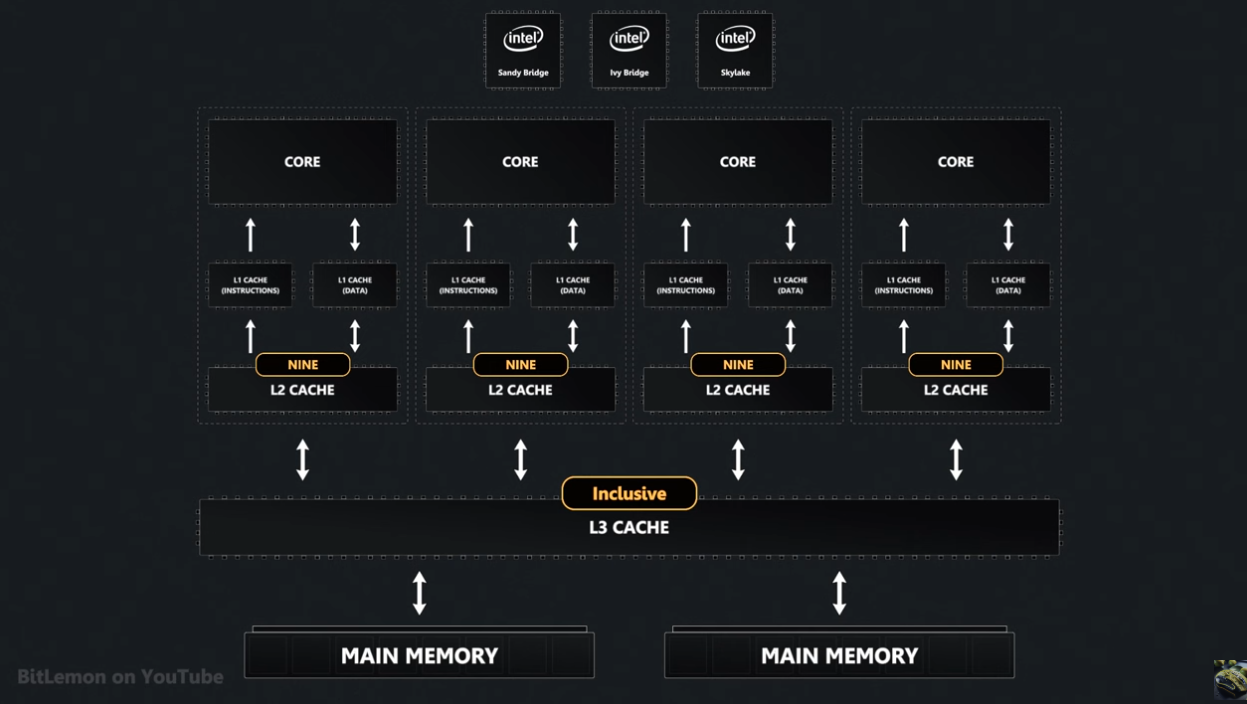
Inclusion Policies
How we define whether data is stored in a single level or across multiple levels.
- Inclusive - data stored in L1 is also in L2 and maybe L3 also.
- Exclusive - data is only in 1 level at a time.
- NINE - data may or may not exist across multiple hierarchies
Architectures can combine these policies:
 Source: BitLemon, YouTube
Source: BitLemon, YouTube
For Intel's Sandy Bridge, Ivy Bridge and Skylake we have an inclusive L3 cache - if it's in L2 it's also in L3.
Inclusive Read
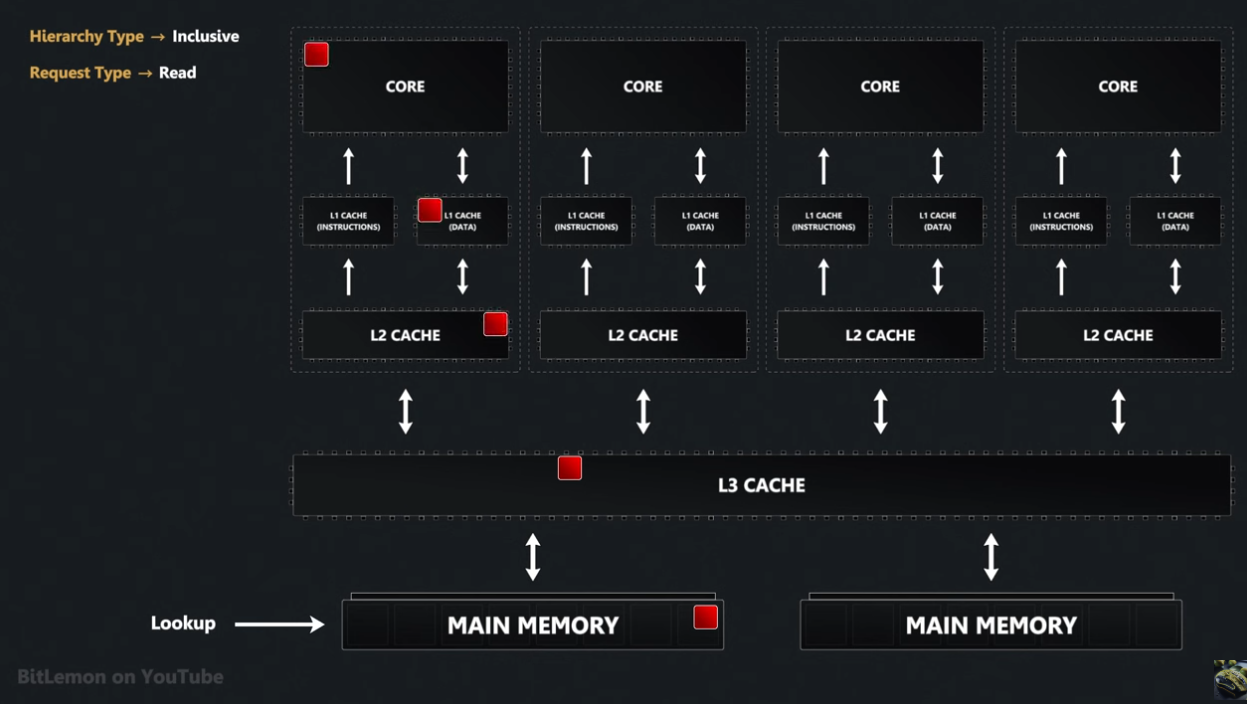
We keep doing lookups on each level of our hierarchy up until we find the element or we hit main memory. The element/memory is copied into each level of the hierarchy above where it's found, until it reaches the CPU core.
Inclusive Write
With write through (we want to write to the backing memory) we immediately propagate data written to L1 to lower layers and finally to main memory.
With write back (we write back to the memory layer) the cache line in L1 is simply marked as dirty and written back (to main memory) later. When we write back the dirty line upon eviction of L1, the line is written to L2 and also marked as dirty - it is the marking of it as dirty in L2 which makes it eligible to be written to L3 at some other time.
Inclusive Write with Write Miss
With write allocate, we bring the data into each level of the cache hierarchy on a write miss.
With no-write allocate, the data is written to the next level down - if each layer is configured for no-write allocate then the data is written directly to main memory.
Links and Resources
https://www.youtube.com/watch?v=zF4VMombo7U - BitLemon, "How Cache Works Inside a CPU"
https://www.youtube.com/watch?v=wfVy85Dqiyc - BitLemon, "CPU Cache Write Policies"
https://www.youtube.com/watch?v=7yrK_9PderQ - BitLemon, "Cache Hierarchy"