Dynamo, Amazon's KV Store
What is Dynamo? Notes from the classic 2007 paper from Amazon's engineering team.
What is Dynamo?
A schemaless, eventually consistent key value store that favours availability over consistency, built for use at Amazon and for use cases where state management becomes the driving factor behind a system's reliability and scalability.
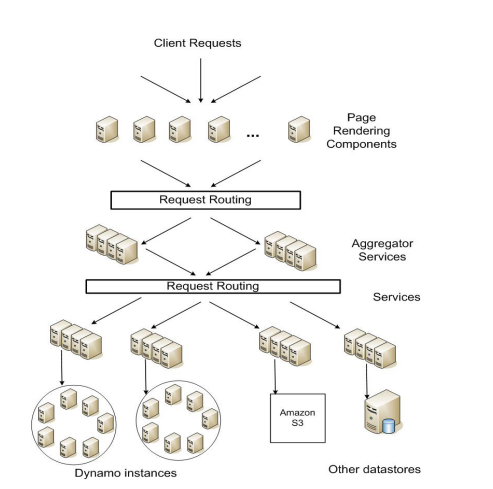
Amazon's Decentralized Service Oriented Architecture
A number of services act as aggregator services - these exploit caching techniques whilst taking results from other services and aggregating them before sending them back out (in memory join style).
In the design of Dynamo, the Amazon engineers were looking to target at SLA at 99.9% to give all users a better experience - they were less concerned about the median, more concerned about outliers.
The engineers wanted to minimise routing through multiple nodes as multi-hop routing causes more variability in the higher percentiles of a latency distro.
-
Failure handling is considered a normal case.
-
Data is partitioned and replicated using consistent hashing - virtual nodes are used to provide an abstraction of a node's ownership of the hash space.
-
Consistency via object versioning - requires semantic reconciliation on failures or partitions due to multiple live versions.
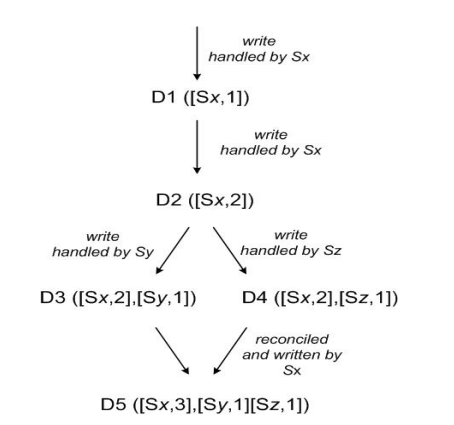
Versioning with Vector Clocks
-
Consistency via gossip based quorum.
-
Operations are designed to span only single rows.
Design Considerations
A high level of consistency is achieved using synchronous replica coordination. You sacrifice availability for consistency.
Availability can be increased via optimistic replication - async replication, which can lead to conflicts.
Conflicts are resolved on read operations - this is because the engineers were targetting an always writeable data store for better CX, so the complexity of conflict resolution gets pushed to the read operations.
The responsibility of conflict resolution can be handled at the data store level using a "last write wins" approach, or can be handled by the application (and an application or domain specific resolution policy used).
Designed to be incrementally scalable by adding nodes which are symmetrical in their functionality though not homogenous in their underlying hardware - therefore work has to be distributed according to the capacity of the particular node.
Client Node Selection
There are two strategies that a client can use to select a node: (1)
route its request through a generic load balancer that will select a
node based on load information, or (2) use a partition-aware client
library that routes requests directly to the appropriate coordinator
nodes.
The node handling a read or write is called the co-ordinator.
Sloppy Quorum
all read and
write operations are performed on the first N healthy nodes from
the preference list, which may not always be the first N nodes
encountered while walking the consistent hashing ring.
Hinted Handoff and Replicas
If a write operation fails on a node, then it gets routed to another node with a flag set in it's metadata that that tells the backup node who the original recipient was. SO when the original node (the intended original recipient) comes back up, the backup node can send that data across too it. These hinted replicas are kept in a separate local DB and processed on a timer.
Objects get replicated across datacenters using the preference list for a key providing DC redundancy.
Replica Synchronization
This is for non-transient failures. To detect replica inconsistencies, Merkle trees are used. Each node (or virtual node) maintains a Merkle tree for each key range. The root of the tree for common key ranges between 2 nodes are compared - tree traversal algos are used to detect where any difference may be.
This works because in a Merkle tree parent nodes are hashes of their children - the leaves are hashes of the key values (lower memory requirements).
For instance, if the hash values of
the root of two trees are equal, then the values of the leaf nodes in
the tree are equal and the nodes require no synchronization. If not,
it implies that the values of some replicas are different. In such
cases, the nodes may exchange the hash values of children and the
process continues until it reaches the leaves of the trees, at which
point the hosts can identify the keys that are “out of sync”.
Key ranges change when a node joins or leaves the cluster.
Ensuring Uniform Load
Dynamo’s design assumes that even where there is a
significant skew in the access distribution there are enough keys
in the popular end of the distribution so that the load of handling
popular keys can be spread across the nodes uniformly through
partitioning.
-
Strategy 1 - Random token allocation per node.
-
Strategy 2 - Equal sized partitions based on the hash space.
-
Strategy 3 - Equal sized partitions based on the hash space distributed equally among all nodes.
Links and References
"Dynamo: Amazon’s Highly Available Key-value Store, 2007" - Giuseppe DeCandia, Deniz Hastorun, Madan Jampani, Gunavardhan Kakulapati, Avinash Lakshman, Alex Pilchin, Swaminathan Sivasubramanian, Peter Vosshall and Werner Vogels