Intro to Aeron Part 1
Some introductory notes on Aeron from a great video in a top down and clear style; the video that is, not my notes ;-)
Transport
Operates at Layer 4 of the OSI.
Features of both UDP and TCP.
Unicast and multicast - point to point, or one to many (replicated via network infra).
Message oriented - framed messages.
Connection oriented - a relationship between sender and receiver.
Reliable - lost messages are nak-ed and re-delivered.
Ordered - messages are sequenced/ordered.
Flow control - prevent fast publishers killing slow receivers, policies for applying backpressure based on whether or not all subscribers need to get all messages i.e. keep up only with the fastest subscriber or keep up with the slowest.
Congestion control - prevent fast publisher killing a congested network e.g. publishing across WANS, publishing to cloud, cross region.
Archive
From reliable messaging to durable messaging.
Record, replay and replicate streams of messages.
Passively watch messages and record them - no central broker.
Cluster
Container for fault tolerant services using a RAFT style infra. Implement logic in replicated state machines.
Aeron Transport Architecture
P2P Style system without a central broker
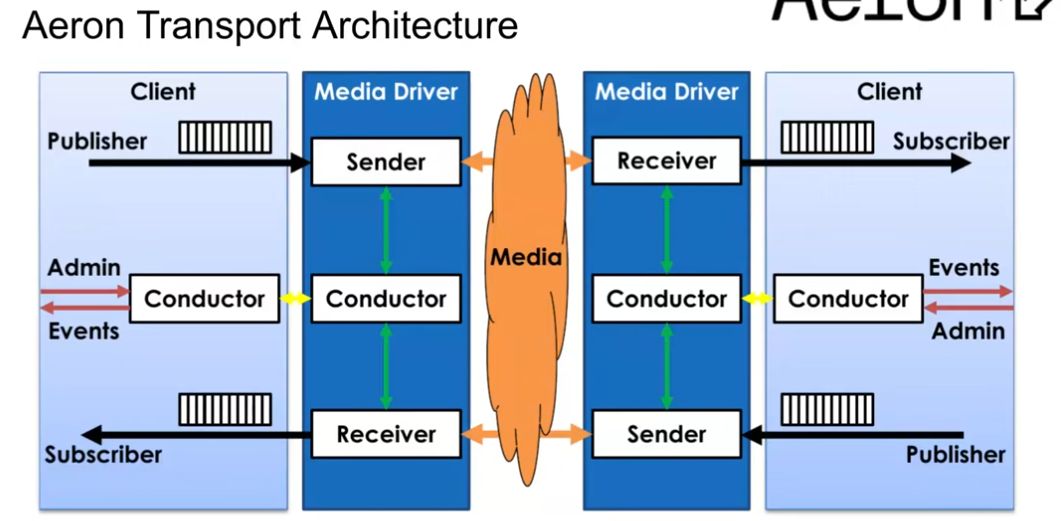
Client and driver communicate via IPC.
Media Driver
3 threads:
- Sender - send user generated messages
- Receiver - rec messages and make them available to a user (polling)
- Conductor - slow path operations, name resolution, socket construction and binding to cores with info shared between the conductor and the 2 other threads (sender and receiver) via queues
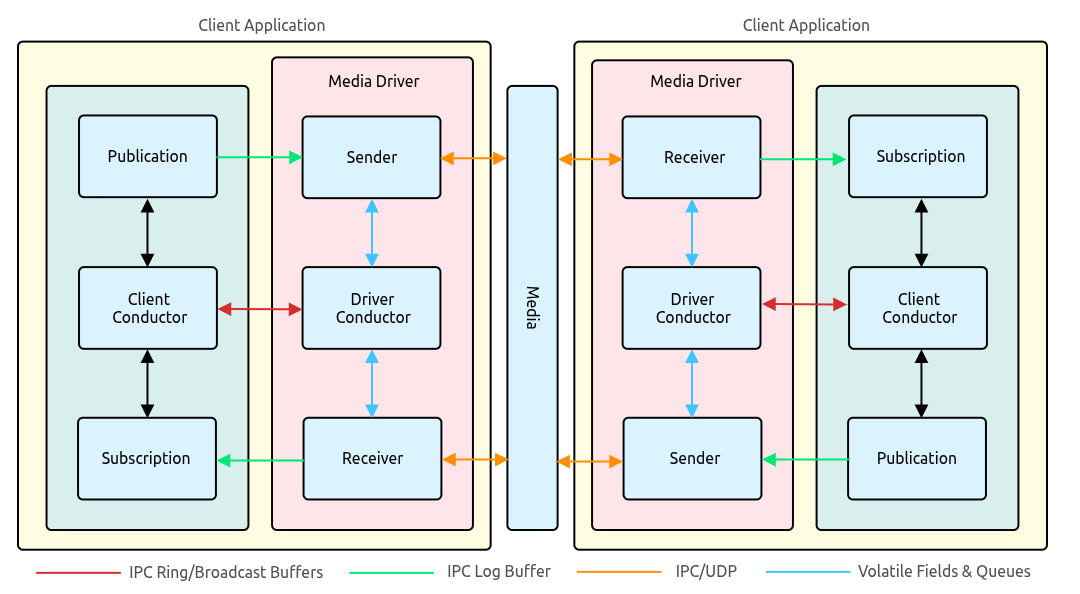
The publisher (your user code) writes to a term buffer via a Publication object. The publication offers() to the buffer (dev/shm), enabling the message to be picked up by the sender (as part of it's duty cycle) which can now handle actually sending the message to the network.
The receiver handles getting messages from the network - these messages are added into a term buffer which gets wrapped by a Subscription object (in the user's code) - your code uses the Subscription in order to poll for the message (passing down the FragmentHandler impl to handle messages). The Subscription is an aggregation of Images.
User applications interact with the conductor in order to do core operations like add or remove subscriptions/publisher - operations to setup communication (admin actions).
Between the media driver and client we use a shared mem transport - the media driver can then run in or out of process with user code.
With an out of process media driver, the user app can then GC, block/stall whilst the media driver continues it's operations. More deterministic behaviour, prevent packet loss from slow consumers.
The media driver can also then be written in other languages like C in order to use things like DPDK.
Virtualized network stacks can decrease performance - use host based networking with containers. You can also run the media driver on the native OS with client's running on containers (with access to /dev/shm)
API Basics
Please note that the video is a few years old, so Iam not 100% sure how up to date these samples from the video are, but I think they're probably pretty illustrative for the purpose of these notes.
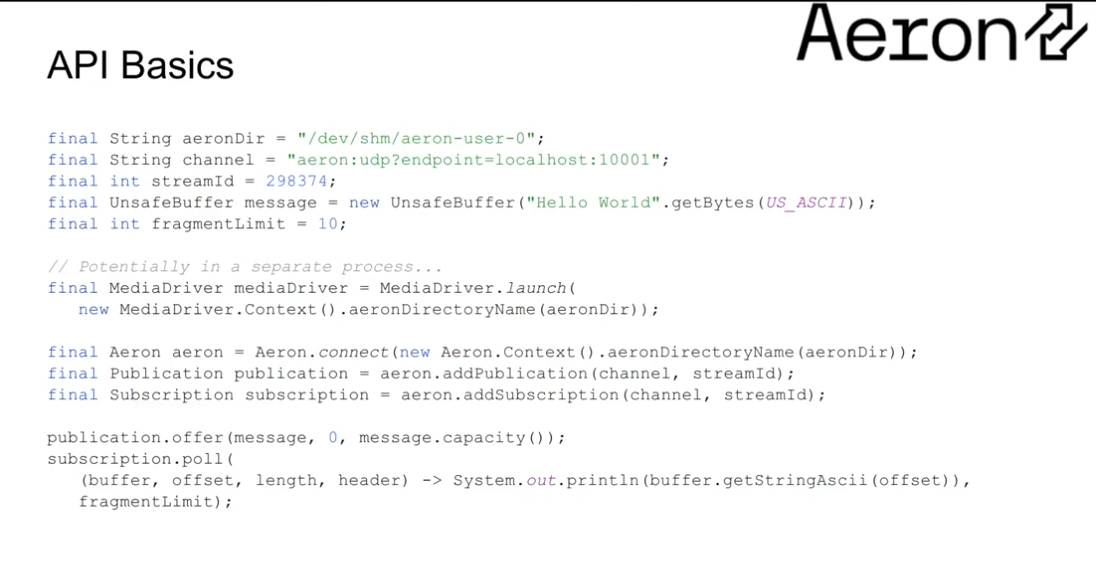
The file system path creates the link between the client and the driver. When we launch, we specify the context with the directory for both the media driver and the Aeron instance.
Channel and stream - we create unidirectional Publication and Subscriptions using the channel details. The streamId allows for multiple streams on the same channel - reduce the number of ports used by multiplexing streams on the same URI.
We can further identify a publisher using a SessionId which is different to the Channel or the Stream - we can have multiple publishers on a particular stream and still differentiate between them using the SessionId.
We publish messages by offering() to the Publication instance - non blocking, returns an error code when there is backpressure or errors.
We get messages by calling poll() - non blocking, returns the number of fragments processed.
URI Structure
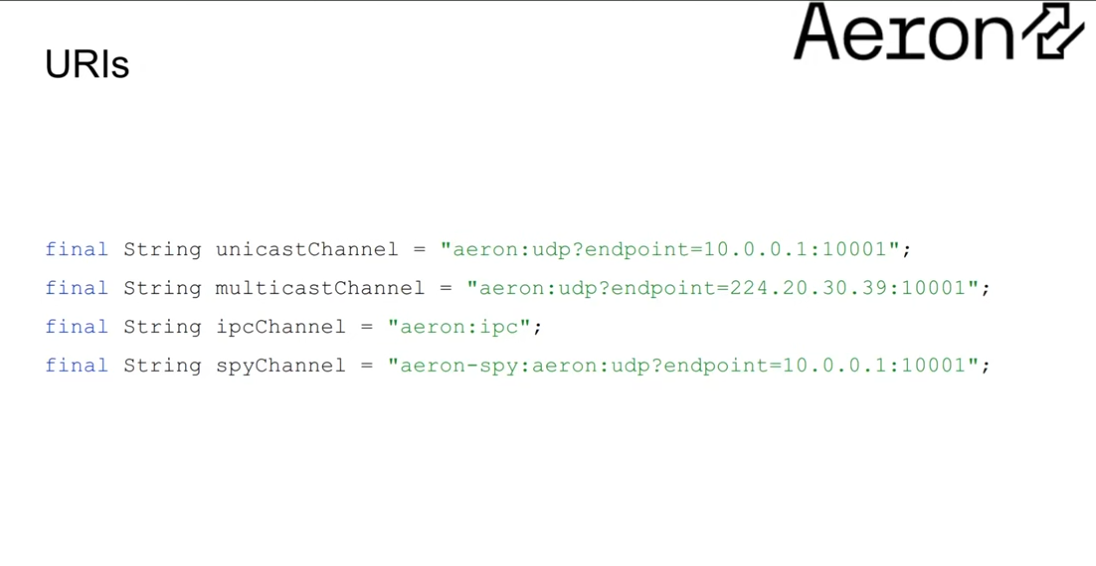
Decouple the channel details from the usage of Publications and Subscriptions.
The IPC mode creates a single shared term buffer between the Publication and Subscription, rather than a seperate term buffer for each direction.
The spy mode creates a term buffer shared between the spy and the Publication. Used by Archive for transparent recording pre-network send.
Performance
Comparing high pctiles between Aeron variants and gRPC variants:
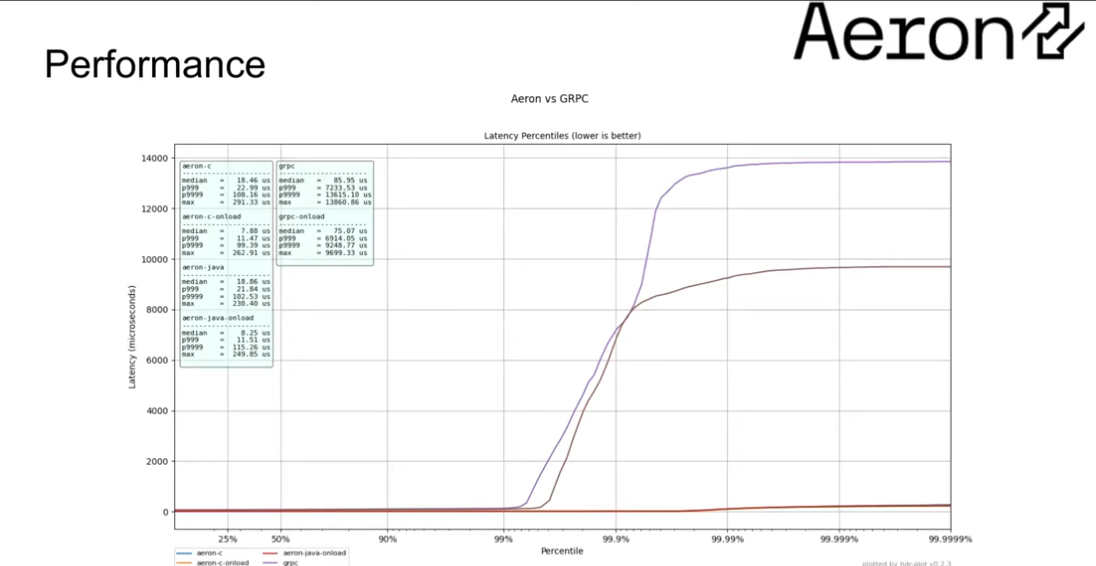
The team at Adaptive/Aeron were not able to saturate the network using gRPC in the above test - they could only hit about 25k msgs/sec with gRPC!
Design Principles
Build for speed from the start.
- GC free in steady state
- Smart batching when sending/recieving messages
- Lock free, CAS
- Non-blocking IO
- No exceptional cases in the message path - keep the hot path hot
- Single writer principle
- Prefer unshared state - message passing over data sharing
- Avoid unnecessary copies
Term Buffers
Have to be able to support multiple writers to a publication. Term buffers are a file in shm. It has a tail. We increment the tail and add the message in.
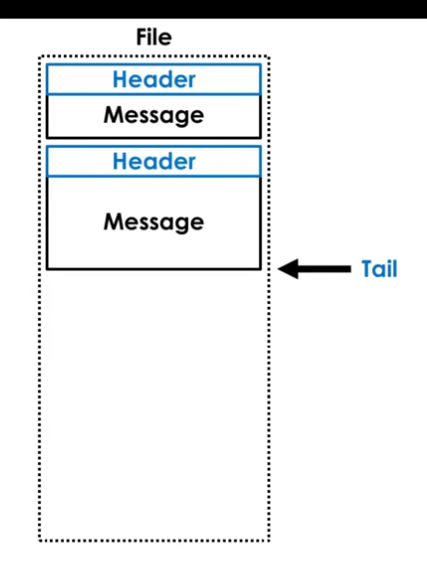
A reading thread scans through the file, waiting for the header length to become non-zero (indicating the message has been fully written).
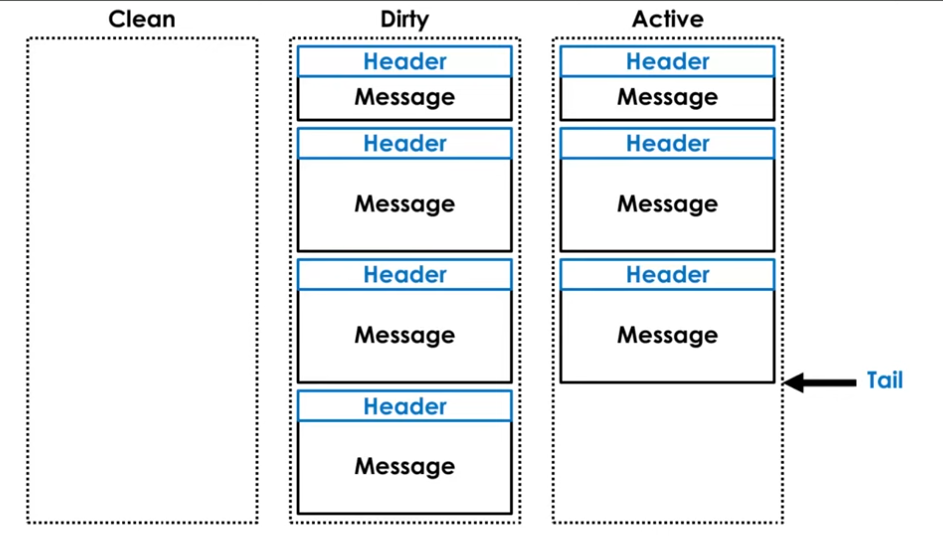
The term buffer is split into 3 sections - clean, dirty and active.
- Clean - the buffer we've cleaned
- Dirty - the one we need to clean
- Active - the one we're using right now
End of Term Buffer Considerations
Let's say we're really close to the end of te current active term and there are 2 messages from 2 different threads waiting to be written.
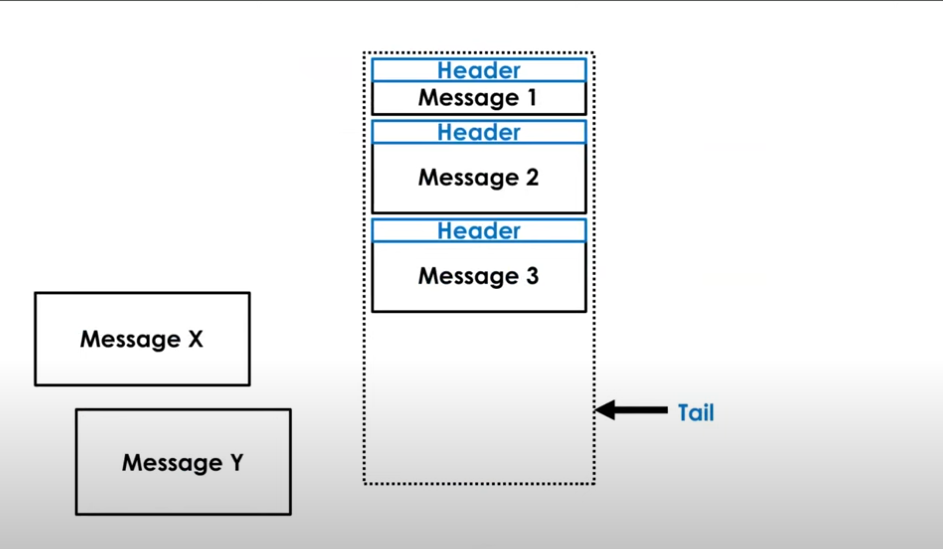
We don't have enough space in the current active term, so the tail is beyond the buffer, and only a single message can be written:
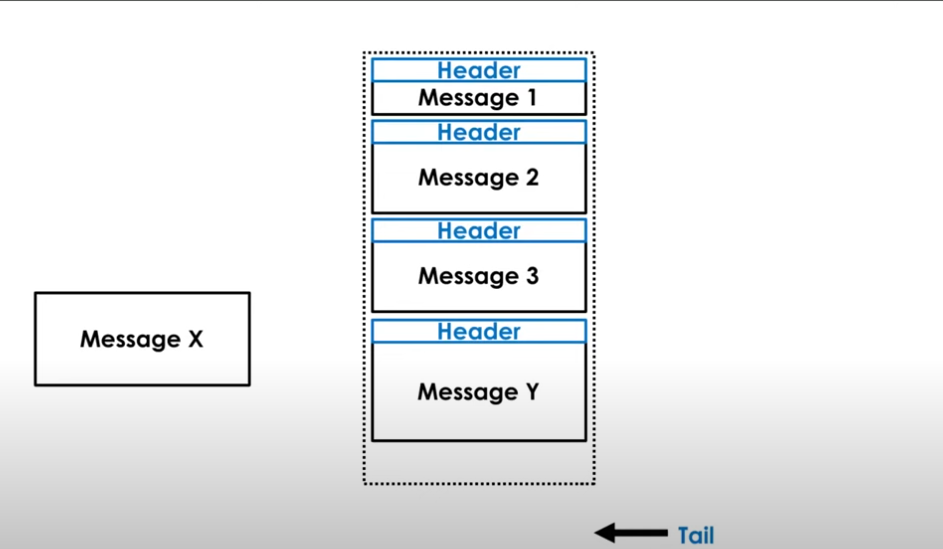
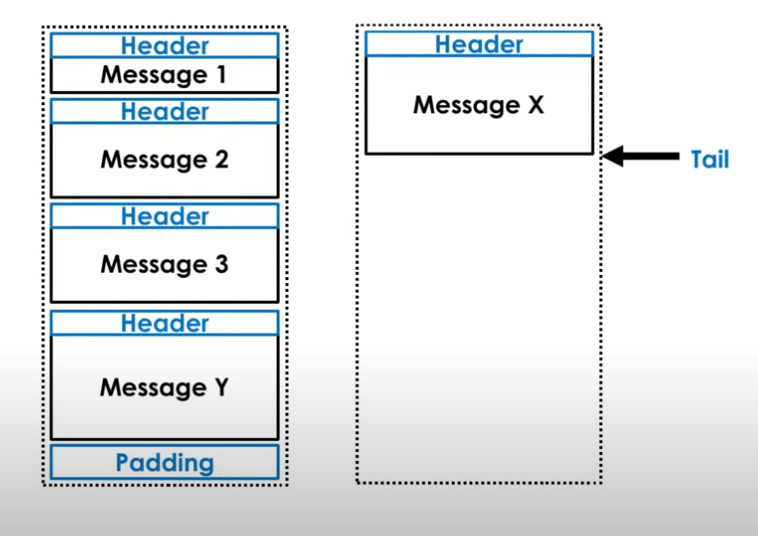
We can however detect that writing message x would create overflow. This results in term rotation occuring, with padding being added to the existing term and the message being written to the next term.
Smart Batching/Data Copies
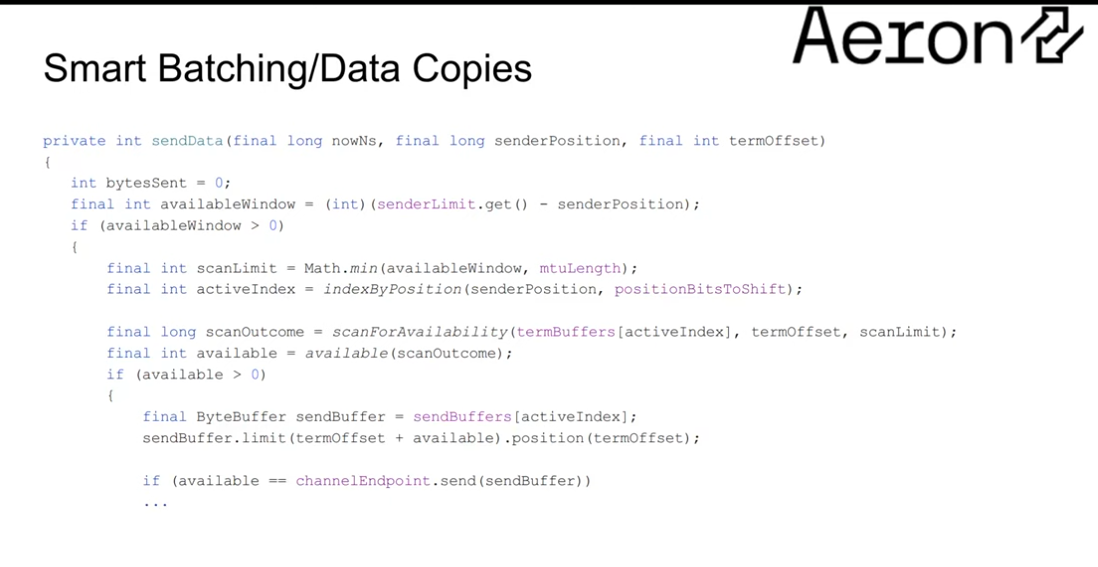
- senderPos - absolute across all buffers
- termOffset - the offset within the term
- availableWindow - max amount of data we can send. Where we are in the term buffer (tail) vs the sender limit.
- senderLimit - how much we can send without impacting downstream subscribers, without causing backpressure.
Therefore the available window is effectively how much data we can still send without causing backpressure.
We compare the available window to the network MTU. We want to pack messages up to the MTU size in an ideal world - in order to minimise total number of network API calls.
- scanLimit - the minimum of the availableWindow and the MTU length. In order to handle cases where the availableWindow is greater than a single network MTU.
We scan across the current term in scanForAvailability(). This returns the maximum amount of data we actually can send - consider when the term buffer is getting "full", then the actual amount of data we can send is going to be less than the scanLimit.
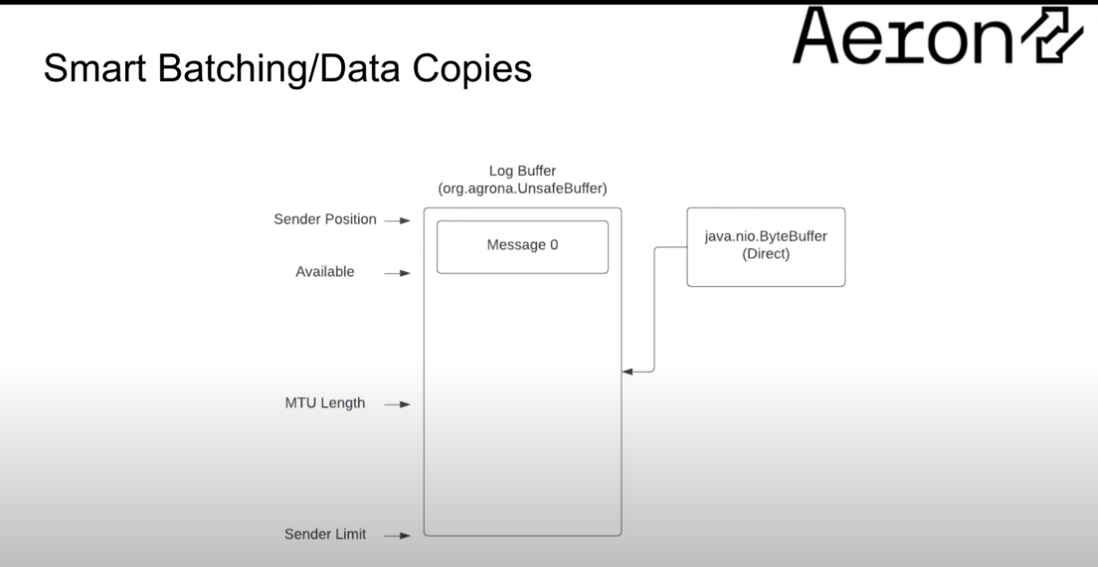
Here we only have one message which is less than the MTU length. The sender hasn't sent anything yet. So we send message 0 to the network.
In the interim whilst we've made the call to send message 0 to the network, more messages have arrived:
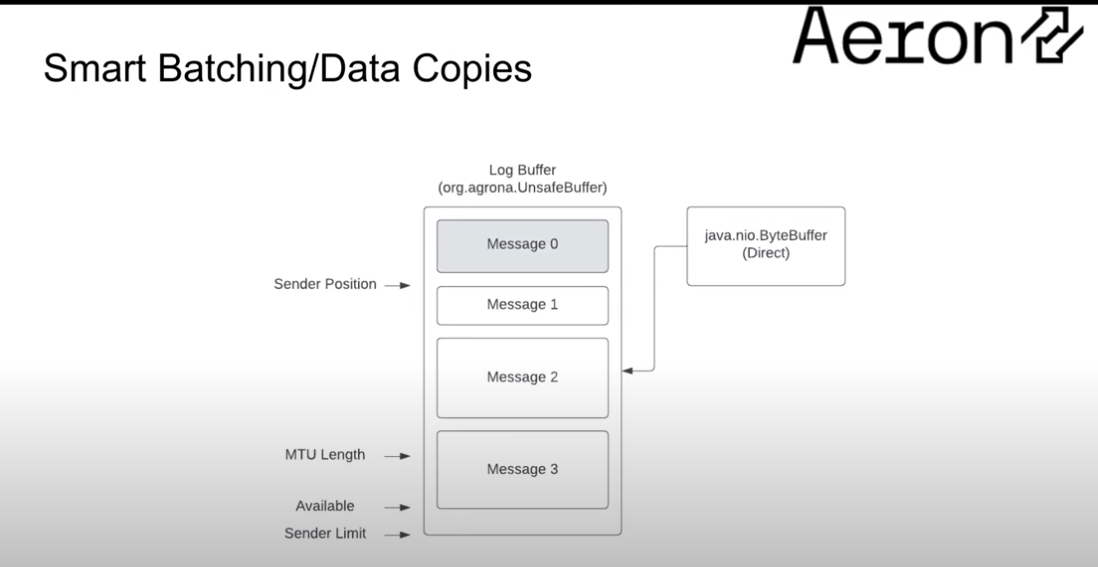
The sender pos has moved forward to the beginning of message 1 as message 0 has been sent.
We see the MTU length puts us into the middle of message 3, it's smaller than the available length because we've had quite a few messages arrive.
So now we're in a scenario where we can batch the sending of message 1 and 2, but not send message 3 as we're only handling full messages (framed).
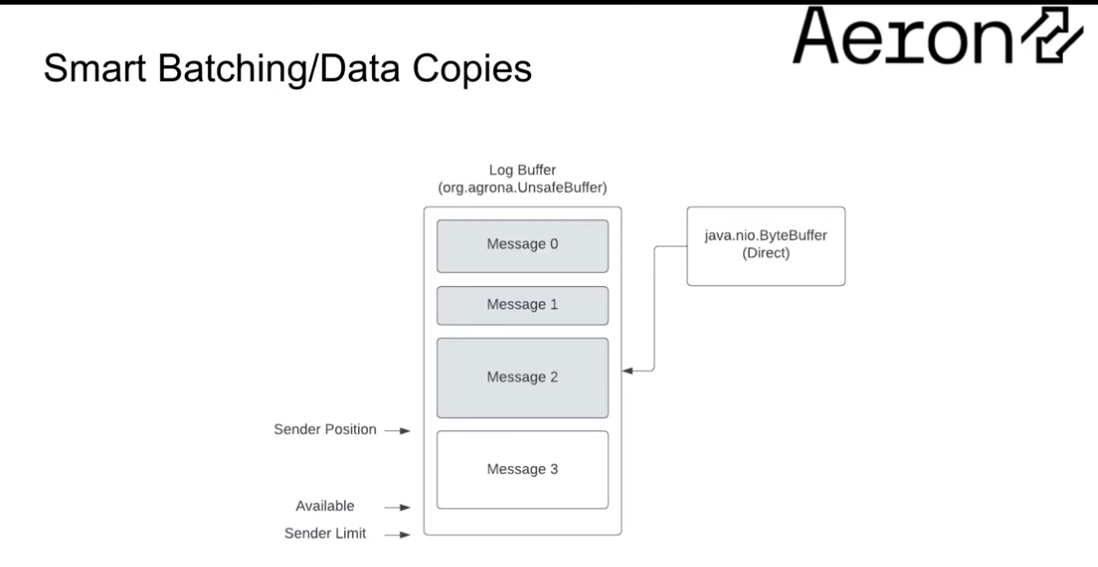
We return from sending messages 1 and 2, and can now send message 3.
Smart batching is also used in Archive to write blocks of data more efficiently.
Common Data Layer
A common data layer across publication term buffers, network and disk allows for minimal data copies. This is based on the Agrona buffers. Positions, lengths, limits are encapsulated into the Agrona buffers which are also backed by a NIO buffer which allows for the actual Java+system calls to be made. You are essentially only changing and passing down references through to native APIs, not copying between say a "publish buffer" and a "network buffer".
TODO: Agrona DirectBuffer writeup.
Links and References
https://www.youtube.com/watch?v=Xa4OlkjFzXc - Diving into Aeron Messaging.
https://aeron.io/docs/aeron/overview/ - source of architecture diagram.
https://www.youtube.com/@weareadaptive/videos - Adaptive's YouTube channel.