LLM Caching
I never write about caches and caching, so I thought I'd cover some basics on LLM caching. Covers inference and prompt caching.

LLM Caching
Inference Caching
One of the cool features of TensorZero is inference caching. This means if you make identical model requests, they'll be served from the cache vs going to the model provider again.
You can specify a max age for reads and the data is stored in the same DB they use for everything else (ClickHouse).
For batched model requests, the results are written to cache but not served from the cache.
In a general sense this requires strict equality checks on strings of undetermined length. Punctuation also matters for context.
 Capitalization also matters ;-)
Capitalization also matters ;-)
It may be possible to also add the ability to return results of semantically similar requests (using embeddings). This does make A-B testing a bit harder, you would also need to configure it correctly (turn it off) for an incremental prompt engineering process.
Prompt Caching
Prefixes - A portion of a prompt.
Prompt caching allows you to cache repeated prefixes between requests, allowing the model to skip recomputing those matching prefixes.
This is useful for long form prompts, where we may need to have detailed instructions and lots of shots, or where we have a long system prompt. Also for things like documents or a text you want to ask questions about.
It means internal model state does not need to be repeatedly recalculated if the prefix is cached - you can precompute and reuse the attention states of the model. This saves you on input token costs.
There are also specific techniques based on whether you're using a transformer model (caching of pre-computed key value states), or just an attention based model.
Prompt caching is supported by Anthropic, OpenAI, AWS Bedrock and Google Vertex for models that support caching.
Checkpoints/Breakpoints
Prompt prefixes (contiguous subsections of the prompt) can be defined using cache checkpoints or breakpoints via provider APIs. These subsections that are defined by checkpoints should be static between requests, otherwise you get a cache miss.
Caching typically requires a minimum prompt length of 1024 tokens and has a max number of tokens also. There is also usually a maximum number of checkpoints/breakpoints in a request.
There is a hierarchy to a typical prompt which aids in adding checkpoints/breakpoints to a prompt:
- Tools
- System
- Messages (includes tool use, images and docs)
This hierarchy also defines an invalidation order - changes to the system prefix results in cache invalidation of the system and messages cache, but not the tools.
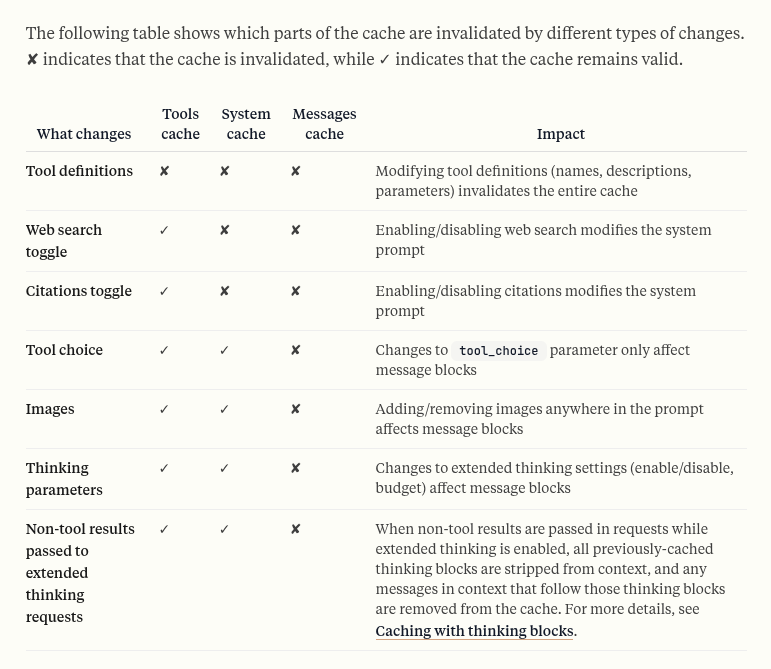 Source: Anthropic
Source: Anthropic
A number of providers offer the ability to get details on your cache usage - there is typically a usage shape which will tell the user their cache_creation_input_tokens (tokens written to cache), cache_read_input_tokens (tokens read from cache) and input_tokens (input tokens not read from cache or used to create a cached entry).
Cache Ownership and API Keys
For most providers the cache seems to be linked to your organization or your API key. Google offers the ability to specifically create caches, offering the user more fine grained control than other providers.
Links and Resources
https://www.tensorzero.com/docs/gateway/guides/inference-caching/ - Inference caching, TensorZero
https://aws.amazon.com/bedrock/prompt-caching/ - Prompt Caching, Amazon Bedrock
https://docs.aws.amazon.com/bedrock/latest/userguide/prompt-caching.html - Prompt Caching, Amazon Bedrock
https://platform.openai.com/docs/guides/prompt-caching - Prompt Caching, OpenAI
https://docs.anthropic.com/en/docs/build-with-claude/prompt-caching - Prompt Caching, Anthropic
https://ai.google.dev/gemini-api/docs/caching?lang=python - Caching in Gemini, Google
https://ai.google.dev/api/caching - Caching, Google AI API
https://towardsdatascience.com/prompt-caching-in-llms-intuition-5cfc151c4420/ - Prompt Caching in LLMs, Towards Data Science
https://aclanthology.org/2023.nlposs-1.24.pdf - GPTCache: An Open-Source Semantic Cache for LLM Applications Enabling Faster Answers and Cost Savings, Bang Fu, Di Feng, Zilliz Inc
https://arxiv.org/pdf/2311.04934 - Prompt Cache: Modular Attention Reuse for Low Latency Inference, (Gim, Chen, Lee, Sarda, Khandelwal, Zhong), Yale