LLM Gateways - TensorZero
Notes on the TensorZero LLM gateway. Covers templates, schemas, feedback, retries, evals, DICL, MIPRO, model-prompt-inference optimization.
LLM Gateways
LLM gateways are designed to increase workflow capabilities and handle concerns of an industrial grade LLM system. One of the best open source ones is TensorZero, (which whilst being written in Rust is neither a command line utility nor Solana).
TensorZero provides:
- A unified API interface to model providers
- Schema based inference
- Inference time optimization
- Observability and telemetry
- Routing, retries and A-B testing
- Evals for specific inferences or end to end workflows
- Facilitates enterprise grade prompt engineering
Prompt Templates and Schemas
Prompt templates are used to enable iteration, experimentation and optimization of prompts - facilitate the prompt engineering process.
They also decouple the calling application code from the prompt, allow you to collect a more structured dataset which remains useful as the prompt changes as well as implement model specific prompts.
Templates are written in the MiniJinja template language. Templates are typically stored in their own *.minijinja file which then gets references from core config. If the prompt has an input, then we need to define a schema:
Example prompt:
Write a haiku about: {{ topic }}
We have an input of topic in the above prompt.
We need to also define a schema, which will allows for providing a consistent interface to a prompt and also handle input validation pre-inference. Templates are defined in JSON Schema format:
For example, our haiku_schema.json:
{
"$schema": "http://json-schema.org/draft-07/schema#",
"type": "object",
"properties": {
"topic": {
"type": "string"
}
},
"required": ["topic"],
"additionalProperties": false
}
The schema can be a superset of types that are used in the prompt template.
When we now want to use our prompt, we call the /inference/ endpoint, passing the function name and params expected from the schema we've defined:
curl -X POST http://localhost:3000/inference \
-H "Content-Type: application/json" \
-d '{
"function_name": "generate_haiku_with_topic",
"input": {
"messages": [
{
"role": "user",
"content": [
{
"type": "text",
"arguments": {
"topic": "artificial intelligence"
}
}
]
}
]
}
}'
We define a bunch of functions, each of which can have a schema - the function is what the prompt should be doing. We need to be able to have multiple prompts for a given function.
If you have multiple prompt templates for a single function, and the inputs vary, then your schema must have all the types and fields you're using across all the templates for that function.
Here's an example TensorZero config:
[functions.generate_haiku_with_topic]
type = "chat"
user_schema = "functions/generate_haiku_with_topic/user_schema.json"
# system_schema = "..."
# assistant_schema = "..."
[functions.generate_haiku_with_topic.variants.gpt_4o_mini]
type = "chat_completion"
model = "openai::gpt-4o-mini"
user_template = "functions/generate_haiku_with_topic/gpt_4o_mini/user_template.minijinja"
# system_template = "..."
# assistant_template = "..."
You can specify different user_template for variants - the above example simply shows one of their quickstart examples where the first or base function doesn't include a user template but instead the whole text of the prompt is generated user side before being sent to the gateway.
You can see that we can also specify a system_template and an assistant_template at the level of specific functions.
Note the naming convention of functions:
[functions.generate_haiku_with_topic]
[functions.generate_haiku_with_topic.variants.gpt4]
[functions.generate_haiku_with_topic.variants.gpt4_4o_mini]
Filesystem Conventions and Structure
Here is the recommended filesystem structure from TensorZero:
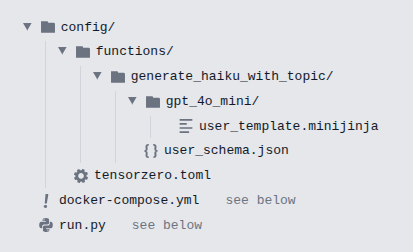
Episodes
You can tag a set of inferences with an episode_id which allows you to track, collect and analyze specific conversations or combinations of user interactions with your system/LLM. This id allows you to track interactions which may occur across multiple functions to achieve a bigger overall task.
Used as part of the experimentation and optimization workflow features.
Metrics and Feedback
You can assign feedback at the inference and episode level - used as part of the experimentation and optimization workflow features.
Feedback can be:
- Boolean - thumbs up or down
- Float - star rating
- Comment - textual feedback from users
- Demonstration - edited drafts, labels, human generated content/tagging
Metrics are defined in your tensorzero.toml config.
For example:
[functions.generate_haiku]
type = "chat"
[functions.generate_haiku.variants.gpt_4o_mini]
type = "chat_completion"
model = "openai::gpt_4o_mini"
[metrics.haiku_rating]
type = "boolean"
optimize = "max"
level = "inference"
Here we are creating a metric for our function which is at the specific inference level and we're saying that we want to maximize the boolean rating.
Here's an example of how you call the /feedback/ endpoint to apply feedback using a metric on a specific inference:

There are also 2 metrics available by default.
Demonstrations
Provide the ideal output for an inference. Not assignable to episodes.

Comments
Natural language feedback assignable to an inference or episode.

Retries and Fallbacks
TensorZero provides the ability to:
- Use multiple model providers - same model but one from say OpenAI and one from Azure (model provider fallback)
[models.gpt_4o_mini]
# Try the following providers in order:
# 1. `models.gpt_4o_mini.providers.openai`
# 2. `models.gpt_4o_mini.providers.azure`
routing = ["openai", "azure"]
- Specify retry logic at the function variant level (variant retries)
[functions.extract_data.variants.claude_3_5_haiku]
type = "chat_completion"
model = "anthropic::claude-3-5-haiku-20241022"
retries = { num_retries = 4, max_delay_s = 10 }
- Route based on weights of variants (variant fallback)
There is no concept built in of API key based load balancing, but they recommend the following pattern:
[functions.extract_data.variants.gpt_4o_mini_api_key_A]
type = "chat_completion"
model = "openai::gpt-4o-mini-2024-07-18"
weight = 0.5
[functions.extract_data.variants.gpt_4o_mini_api_key_B]
type = "chat_completion"
model = "openai::gpt-4o-mini-2024-07-18"
weight = 0.5
You basically have multiple variants using the same model with a variant name that indicates the intent and a weight that is set appropriately. You also then have to configure the model and routing:
[models.gpt_4o_mini_api_key_A]
routing = ["openai"]
[models.gpt_4o_mini_api_key_A.providers.openai]
type = "openai"
model_name = "gpt-4o-mini-2024-07-18"
api_key_location = "env:OPENAI_API_KEY_A"
[models.gpt_4o_mini_api_key_B]
routing = ["openai"]
[models.gpt_4o_mini_api_key_B.providers.openai]
type = "openai"
model_name = "gpt-4o-mini-2024-07-18"
api_key_location = "env:OPENAI_API_KEY_B"
A-B Testing
When we define multiple variants of a function, the gateway samples them using their weights which allows us to do A-B testing on things like changing the underlying model or changing the prompt.
If no weights are set at the variant level, all variants are sampled uniformly.
For multi-step LLM workflows, we can use the episode_id field to make sure the same variant is selected for each step in the episode - this ensures consistency.
You can also pin inferences to a specific variants by specifying a variant_name field in the request.
Here's an example of setting weights on function variants:
[functions.draft_email]
type = "chat"
[functions.draft_email.variants.gpt_4o_mini]
type = "chat_completion"
model = "openai::gpt-4o-mini"
weight = 0.9
[functions.draft_email.variants.claude_3_5_haiku]
type = "chat_completion"
model = "anthropic::claude-3.5-haiku"
weight = 0.1
Inference Optimization
TensorZero provides a bunch of features for inference time optimization.
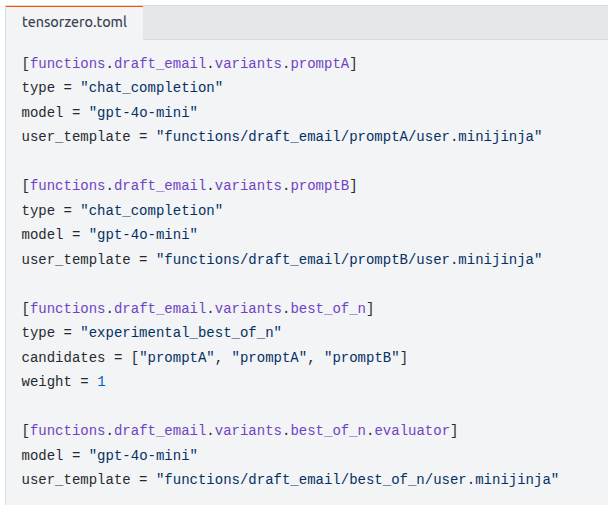
Best of N Sampling
Use an evaluator LLM to determine the best response to use from different variants. The evaluator prompt must be written as if it were solving the problem itself, not written to directly evaluate the prompt - TensorZero modifies the evaluator prompt to make it more suitable for evaluating the variants.
Here's an example of how we can configure the best of n sampling:
Chain of Thought
You can set the experimental_chain_of_thought field on a variant to enable chain of thought/thinking/extended thinking for non-streaming requests.
Tensorzero recommend that for CoT with chat functions you simply use a reasoning model (one which already implies CoT).
Reasoning is stored in the DB for observability and optimization.
Dynamic In Context Learning (DICL)
Augment input with relevant historical data, contextually similar examples, highly rated responses etc. You create an embedding from the input in order to find similar historical example inputs which have highly rated responses. Using these examples, the prompt is reconstructed to provide additional context.
Mixture of N
We generate multiple responses (an ensemble) from variants and use a fuser function to combine them into a final response. Can reduce the impact of outlier bad generations.
Just like the evaluator for best of N sampling, the fusor function should be written as though it's solving the actual problem, not written specifically to join multiple outputs - TensorZero modifies the prompt you provide to optimise it to combine candidate outputs.
Included Optimization Recipes
Optimize functions by generating new variants based on historical inference and feedback data.
Provides facilities to optimise at the inference, model or prompt level.
Inference-Time Optimisations
See above section on DICL, Mixture of N and Best of N.
Prompt Optimisations
You can use prompt optimisation techniques from things like DSPy or MIPRO.
MIPRO can be used to optimise prompts across multi-step or multi-llm pipelines using a bayesian approach to find which instructions and shots actually improvde the end to end performance.
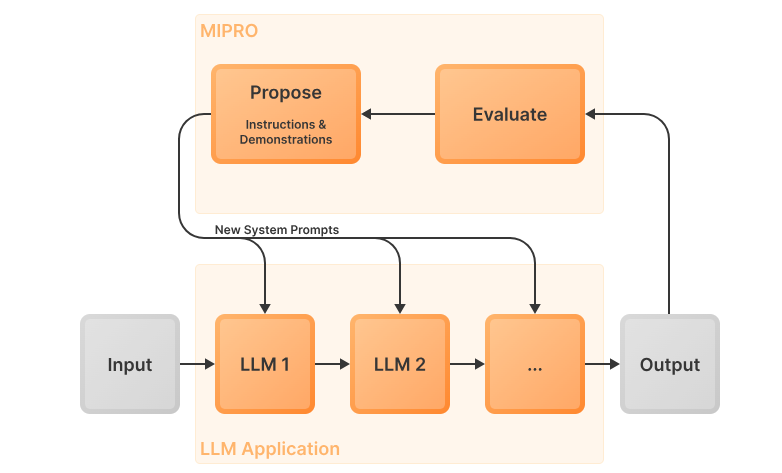 Source: TensorZero
Source: TensorZero
Model Optimisations
Support for:
-
Supervised tuning - using the historical dataset to find good examples to fine tune the model.
-
Preference fine tuning - create preference pairs from your dataset and use those to fine tune the model. These are pairs of preferred and non-preferred responses to specific prompts.
Evaluations
TensorZero provides static and dynamic evaluation capabilities.
Static Evals
Used to evaluate individual functions by providing an evaluator function which is typically an LLM based judge - you can also have variants of LLM judges, only one of which can be active. These static evals can be run from the CLI or web UI.
See for more details.
Dynamic Evals
There is a recipe for creating dynamic evaluation pipelines which operate at the episode level.
You are basically adding feedback to an episode using a metric called task_success who's value is a function of the final output generated (scored however you as a user wants).
You can see this is different to how evaluation occurs or prompts are written for fusors and best-of-n evaluators, as our evaluation function now has to be written as though it actually is doing the evaluation, not conducting the task at hand.
See for more details.
Challenges in Gateways and Unified APIs
- Batching impl and rate limits differ by provider
- System prompts placement, reuse or lack of with state (OpenAI and their stateful offering) can differ
- API key management
- Handling of thinking and chain of thought requirements for completions, chat and tool use across model providers, explicit summary requests and storage in DB.
Links and Resources
https://www.tensorzero.com/docs/ - TensorZero docs
https://www.tensorzero.com/docs/recipes/
https://docs.rs/minijinja/latest/minijinja/syntax/index.html - Minijinja docs