OpenAI APIs
Comparisons of the OpenAI service offering with that of Anthropic. Includes context window, rate limits and model optimization.
OpenAI API
Rate Limits
The rate limits are different when compared to Anthropic's but are also based on paid for usage tiers (cumulative billables):
- RPM - Requests per minute
- RPD - Requests per day
- TPM - Tokens per minute
- TPD - Tokens per day
We see that there is no difference between input and output tokens for rate limiting, but now we have a daily limit alongside a per minute limit.
Rate limits also vary by model (and can be shared by model family). There are also different limits for long context requests.
Flex Processing
For lower priority tasks - lower costs for requests vs. slower response time and resource unavailability.
You can enable this by setting service_tier="flex" in the request.
Structured Output
The OpenAI API provides support for a more structured output via a text_format field on the request (or response_format if you're using their chat completions API).
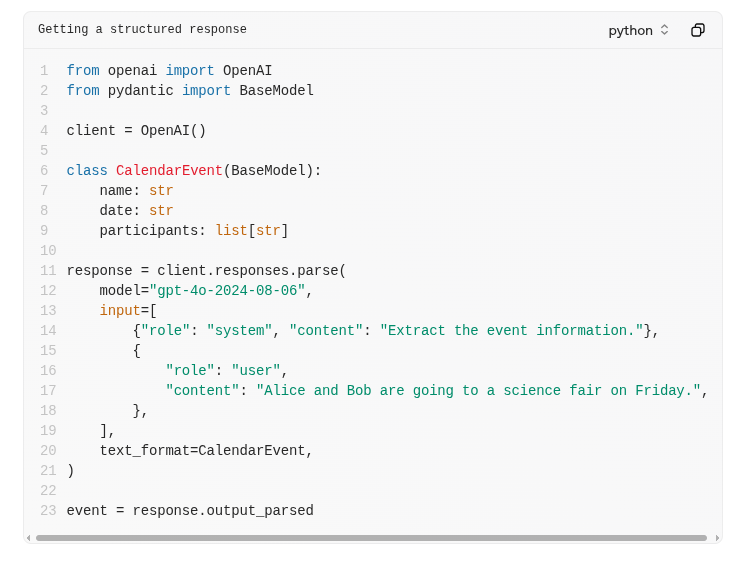 Source: OpenAI
Source: OpenAI
The approach with the Anthropic API is to provide a user prompt which guides the output format:
"You’re a Customer Insights AI. Analyze this feedback and output in JSON format with keys: “sentiment” (positive/negative/neutral), “key_issues” (list), and “action_items” (list of dicts with “team” and “task”)."
Background Mode
OpenAI supports async/background mode where you can poll for results - you set a field called background=True. From the response you get an Id which you can use to poll for the result.
This kind of behavior is achieved in Claude using batching, which has it's own rate limits.
Webhooks
You can handle callbacks based on event types:
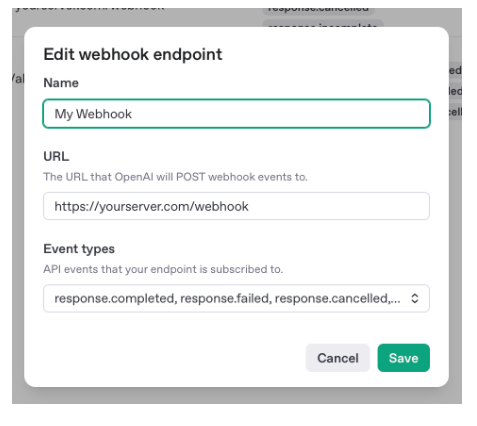 Source: OpenAI
Source: OpenAI
Batching
The way OpenAI support batched requests is via crafting and then uploading a file via their files API. This input file is then references when making the actual request to create the batch.
Just like with Anthropic, the rate limits for the batch API are different from their other per-model rate limited APIs.
Streaming
The OpenAI API supports streaming over SSE by specifying a stream=True field on requests.
There is a more fine grained breakdown of events than with Anthropic's SSE:
 Source: OpenAI
Source: OpenAI
Reasoning/Thinking
OpenAI provide models with reasoning abilities. This is similar to the extended thinking feature in Claude.
The feature is enabled by setting a reasoning= field in the request:
 Source: OpenAI
Source: OpenAI
Reasoning tokens - used by models to think by considering multiple approaches. Reasoning tokens are discarded from the model's context, but billed as output tokens.
You need to adjust your max_output_tokens to handle reasoning - you can get a response with a status of incomplete because the context window allocated is too small to handle the additional tokens being generated for reasoning.
Just like with Claude, you should be passing back the reasoning or thinking steps when you're using tools to allow for better continued reasoning. This can be done using the previous_response_id if you're using the Responses API.
Reasoning tokens may be discarded, but you can get a human readable summary by specifying it with the reasoning details:
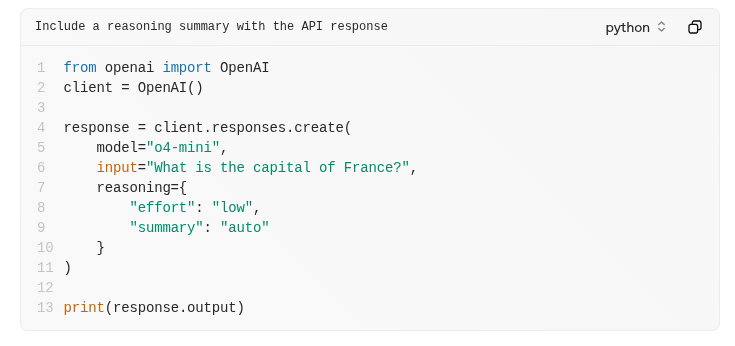 Source: OpenAI
Source: OpenAI
In the response back, you'll now get a summary field:
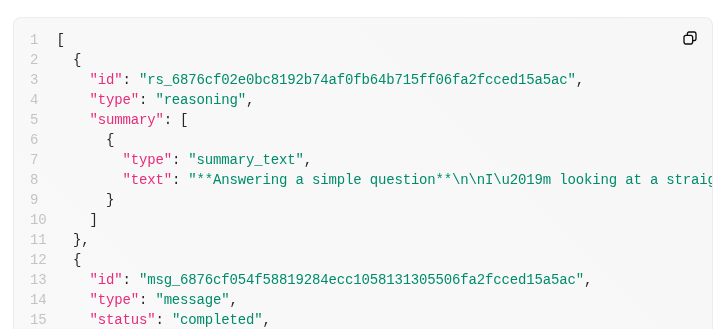
You can see why this can consume so many tokens:
"text": "Answering a simple question\n\nI\u2019m looking at a straightforward question: the capital of France is Paris. It\u2019s a well-known fact, and I want to keep it brief and to the point. Paris is known for its history, art, and culture, so it might be nice to add just a hint of that charm. But mostly, I\u2019ll aim to focus on delivering a clear and direct answer, ensuring the user gets what they\u2019re looking for without any extra fluff."
Context Window and State
The chat completions API offers the traditional stateless method of handling context - you as the calling client accumulate turns and provide them to the model via an API call.
The Responses API offers a stateful methodology - instead of returning previous context, you set a previous_response_id with that id returned in the previous request to the responses API.
This allows for ID chaining (but introduces server side state) in order to not include multiple turns from client side API calls.
Responses API vs Chat Completions API
These are the main way you can interact with models, like the /messages/ endpoint with Claude.
The responses API was developed after the chat completions API in order to simplify the ability to do more agentic tasks and use MCP.
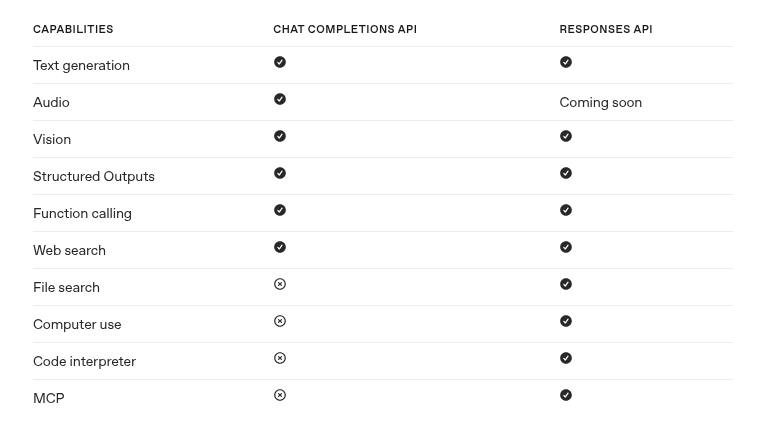 Source: OpenAI
Source: OpenAI
Responses are retained for 30 days by default which allows users to be able to get previous responses using an API call with the ID of the response we want.
The request has some interesting options like the prompt_cache_key, a safety_identifier for detecting violators of usage policies, enabling the response to be stored with store and some additional output structure configuration via include.
System Prompts
System prompts are provided with an instructions field on the request - if we use ID chaining by setting previous_response_id then the system prompt is not carried over.
Model Optimisation
OpenAI provides a variety of ways to optimise the underlying LLM you're using.
This can allow you to user shorter prompts, less examples, train on proprietary data without using it as part of one/many shots, train smaller models to do something very specific, use less tokens overall and therefore reduce costs.
Anthropic provide some features for model optimisation - Claude 3 Haiku can be fine tunes for use in Amazon Bedrock.
Embeddings
OpenAI provides an embeddings API, whereas Anthropic delegate this to other providers.
Links and Resources
https://platform.openai.com/docs/api-reference/introduction
https://www.anthropic.com/news/fine-tune-claude-3-haiku
https://docs.aws.amazon.com/bedrock/latest/userguide/custom-model-supported.html