Anthropic APIs
My notes on the design of Anthropic's APIs and some general design considerations for provider based APIs and SDKs. Covers rate limiting, service tiers, SSE flow and some of the REST API endpoints.
Analyzing the Anthropic SDKs and APIs
Whatever language you choose, fundamentally, Anthropic's services are provided by a REST API with support for streaming via SSE. This is not so different from other providers, but I will cover those separately.
Rate Limiting
The API caters for spend limits and API request limits based on credit purchased tiers.
"You may hit rate limits over shorter time intervals. For instance, a rate of 60 requests per minute (RPM) may be enforced as 1 request per second. Short bursts of requests at a high volume can surpass the rate limit and result in rate limit errors." - Anthropic
Batching and Rate Limits
Rate limits are applied on a per model basis for non-batched requests.
However, if you use message batches, that has it's own set of rate limits which are applicable across all models. This includes a HTTP request limit across all batch endpoints, as well as a limit on the number of simultaneous individual tasks that are pending processing.
ITPM, OTPM, RPM and Caching
Rate limits are based on:
- ITPM - Input tokens per minute
- OTPM - Output tokens per minute
- RPM - Requests (HTTP API) per minute
You can think about this as being rate limited as a function of how many requests/interactions we're making, the size of our requests/inputs and the size of the output that's being generated.
Because caching is also employed, this needs to be factored into the rate limiting. When we add something into the cache, it counts towards the input tokens limit.
When we read something out of the cache, sometimes it does count towards your input token limit and sometimes it doesn't:

The output token limit is estimated based on what max_tokens you pass in, then once the real number is known, it is adjusted as necessary.
If you get rate limited you get a 429 error and a header field called retry-after which tells you how long to wait before retrying.
More details on why you've been rate limited are available in the response headers as well as a host of other information.
The rate limiting algorithm is Token buckets based - periodic replenishment of tokens into a token bucket which constrains the max capacity (remove tokens from bucket on use).
Improving the Rate Limiting DX/UX
-
Provide users with estimates/approximations of better values to be using for
max_tokens- a suggestedMaxTokens field in a response from/messages/which can be applied by the user to themax_tokensfield in subsequent requests. -
Would perhaps imply or require similar/predictable behaviour on a single API_KEY to be able to keep the
/messages/endpoint stateless (may be better for production but by then you've probably got the issue ironed out).
Questions and Considerations for Rate Limiting
-
Are there enough cases in real use where OTPM rate limiting occurs due to max_tokens < actual generated tokens?
-
If streaming a response back and then the OTPM gets broken, should you just stop sending stuff back, or delay it? Is there a better UX?
Service Tiers
There are 3 service tiers:
- Batch - for async workflow that can be outside your normal capacity
- Standard - default, everyday use
- Priority - purchasable prioritization for a better SLA
If you have access to priority tier, then it's on by default. A user can specify a service_tier of auto (will use priority tier if there is sufficient priority tier input and output tokens limit remaining) or standard_only in the body of the request.
Error codes
Provides standard HTTP status codes. Status code 529 is for when the Anthropic API itself is overloaded across all users.
Beta Headers
You can specify comma separated features in a anthropic-beta field in the header of requests in order to access specific beta features.
API Endpoints
Messages
This is the main endpoint most people will use to interact with LLMs. Every time we invoke a model we are passing in a messages array. Models are trained to generate output based on conversational turns between a "user" and an "assistant" - consecutive turns from the same role are collapsed into a single turn. Models generate the next message in the conversation.
Each input message is composed of a role field and a content field.
As there is no "system" role for messages, you can specify a system prompt at the top level of the request message:
model="claude-3-7-sonnet-20250219",
max_tokens=2048,
system="You are a.....", # <-- role prompt
messages=[
{"role": "user".....}
]
Because each request is stateless (the management of conversational state is pushed to the client as a responsibility), we have to accumulate the turns ourselves. This stateless nature also allows us to:
- Modify conversation history and turns
- Optimise conversation history
- Prefill - by changing the role of the last turn to be that of the assistant
Using the /messages/ endpoint you can also configure stop sequences, temperature, extended thinking and specify any available tools.
Tools
LLMs can call server side tools itself. It can also instruct a client to make the call to a tool and then provide it with the result as part of the conversation.
Client side tools are those which you have to call on the behalf of the LLM and then provide back in a tool_result with a matching tool_use_id to identify the original tool use request which was made by the model.
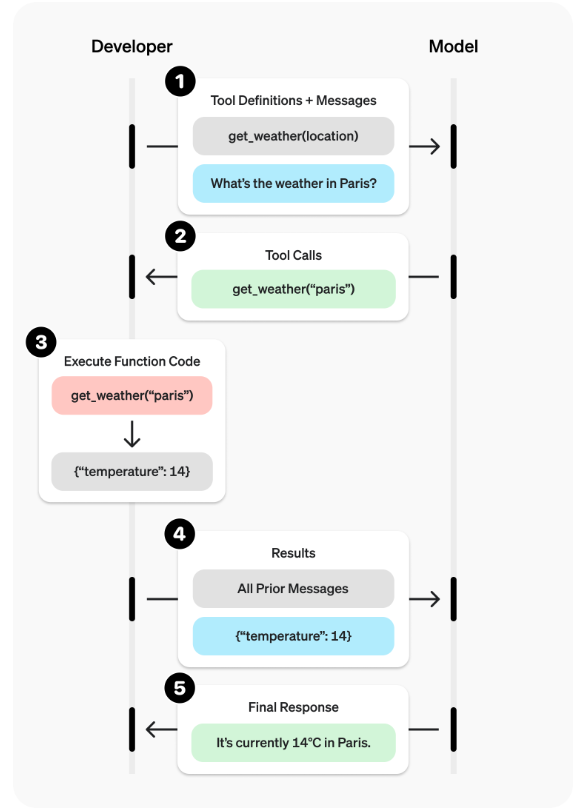 Source: OpenAI
Source: OpenAI
We let the LLM know about tools with a schema which basically describes what the tool is used for and the parameters we need to provided with in order to call that tool - it is a contract or an API for the tool with enough details about it that an LLM can infer how to use and call it. There is no output schema definition for a tool, it's simply JSON.
Batched Messages
There is support for batched requests via a /messages/batches/ endpoint. This takes an array of requests, each of which has a custom_id field in order to match each request with an individual response at a later time (once the requests are complete) via polling.
The result includes an id field which is the identifier for the entire batch of requests.
You can also cancel a batch request (whilst it's being processed) and delete the result of a batch (once it is complete).
The status of a batch request is determined by the processing_status field - you can poll on the /messages/batches/{msgBatchId} endpoint to determine the status.
Other Endpoints
There are also endpoints for listing and getting model details, counting how many tokens a request will use (an estimate of the input tokens) and a files API which allows for file management and upload - each file resource is referenceable in messages/prompts.
Files API Enhancements
An enhancement to the /files/ API could be to allow an additional field in the body of the request for tags or other metadata which may be useful for file management or identifying subsets of files for a model or tool input.
Technical Patterns and The Context Window
The context window is the working memory for a model. It is the cumulative conversational flow/turns and it grows as the conversation advances (progressive token accumulation) with previous turns preserved.
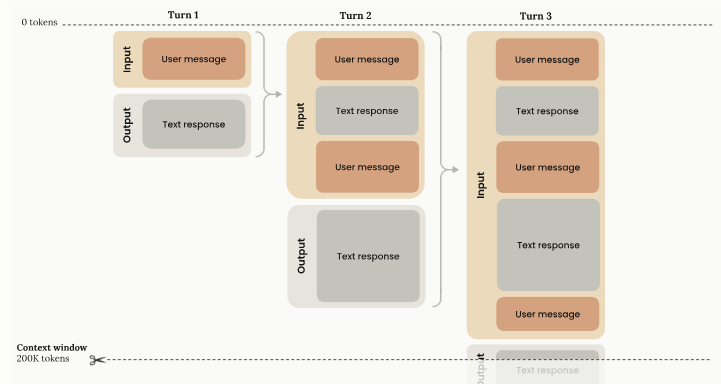
Extended thinking blocks (and redacted blocks) are auto-stripped by the API - they are not used by Claude for generating subsequent outputs and are only billed as outputs once:
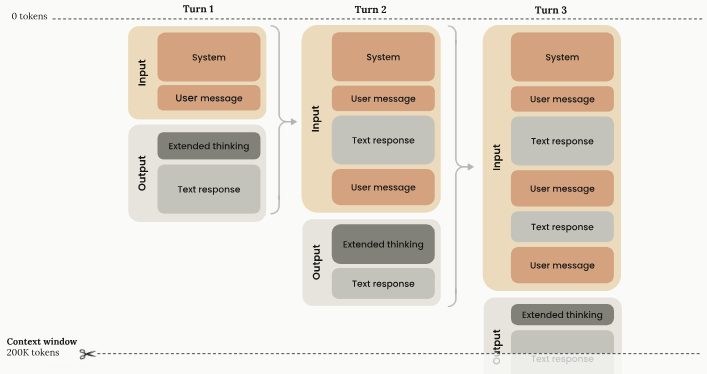
For tool use however, we must include the thinking blocks, response, tool use request and the tool result for subsequent turns - this indicates that thinking blocks are a critical driver of determining tool usage.
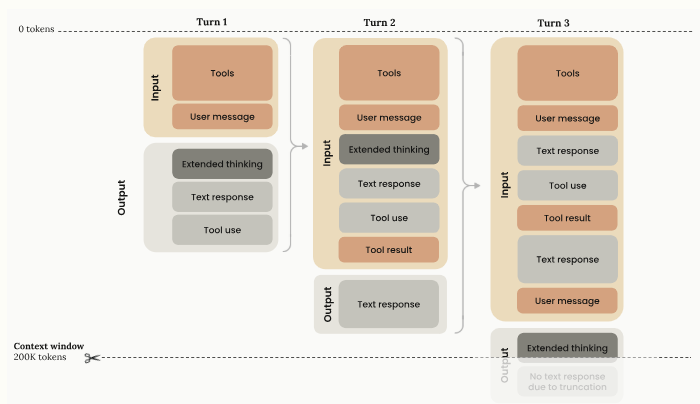
MCP
You can specify a mcp_servers array on a /messages/ endpoint request to specify remote MCP servers and their available tools:
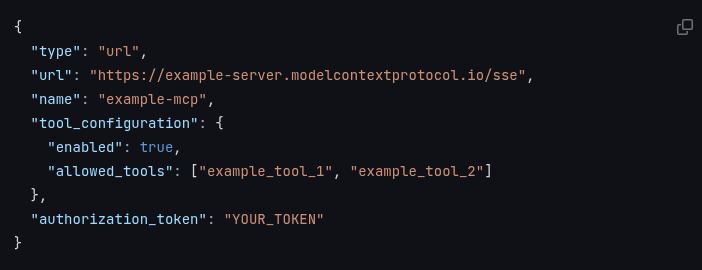
This provides the client a way of knowing how to access services from remote MCP servers. Because when we use tools we include the whole history in the context (thinking), the request by an LLM to use a tool is linked back via the tool_use_id field returned on tool results. This also allows a specific tool use to be tied to a specific remote MCP server.
Streaming API
We can make a stream request for responses back over SSE by specifying a stream field:
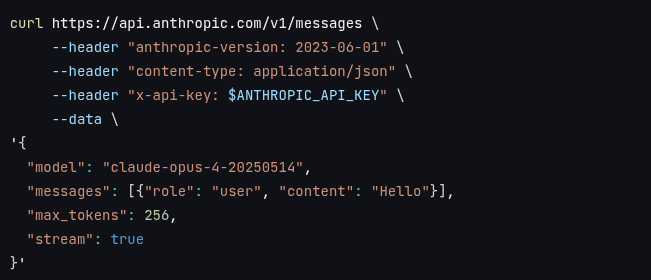
The server can then respond with a 200 OK and the content-type header set to text\event-stream.
Alternative mechanisms include returning a sessionId on the response, which is used to form a URI for an SSE session from the server to the client, which is initiated by the client.
Events
Basically we can get messages broken down into multiple chunks. Those chunks can be made up of content which itself can be broken down into multiple chunks.
There are some core basic events like Ping and Error.
The core events are around indicating the start and end of a message. A message can be made up of multiple content blocks, so we have event types that indicate the start and end of these content blocks.
We have message deltas which indicate things like stop reasons, and we have content block deltas which are outputs of content which we need to accumulate ourselves (they can be partial content, whether that's just partial text from a sentence or partial JSON).
OpenAI's platform also offers streaming support via SSE - from a design pov it's got a wider range of events.
Model vs System/Product Features
- Prompt Caching - a system feature
- Extended thinking - a model feature
- Streaming messages - a system and model feature
- Batch processing - a system feature
- Citations - a model feature
- Multilingual support - a model feature with possible system level enhancements
Links and Resources
https://docs.anthropic.com/en/api/rate-limits
https://docs.anthropic.com/en/api/service-tiers
https://docs.anthropic.com/en/api/errors
https://docs.anthropic.com/en/docs/build-with-claude/context-windows
https://docs.anthropic.com/en/docs/build-with-claude/streaming#content-block-delta-types
https://modelcontextprotocol.io/overview
https://platform.openai.com/docs/guides/function-calling?api-mode=responses