Ollama Basics
Some basics on Ollama. Includes some details on quantization, vector DBs, model storage, model format and modelfiles.

Ollama Architecture and Design
Ollama is a tool for running local LLMs. It also allows you to locally customise models and share those optimisations with others. It provides the ability to pull models from a remote repository, store models locally and provides a unified API across models to allow you to generate content/chat.
The server side encompasses a REST API and a way to load models (Ollama automatically unloads the model after a configurable 5 minute timeout) and interact with it - this is achieved using llama.ccp which is an inference engine.
The way of interacting with a model over REST is not too dissimilar to the Anthropic API or the OpenAI API.
Types of Models
-
Source - text or base models. Not designed to respond to a question, just to predict the next word.
-
Fine tunes - input in a specific format. Chat and instruct models. Respond to a question. Instruct models respond to a specific type of prompt, whereas chat models are designed for a back and forth flow.
-
Code model - fill in the middle style models.
-
Multimodal - not just text as an input. Can be images, videos, audio, text2speech, speech2text etc.
Quantization of a Model
To reduce the runtime of generation, we can quantize a model - the model weights and parameters are quantized. This reduces their precision, allowing them to be represented using smaller data types, which can provide faster inference and less memory usage.
You can compare the same prompt with different quantizations of the same underlying model. You can also try the same prompt with the same model with different number of params e.g. an 8b variant vs a 70b variant of the model.
Some models are designed better for function and tool calling. Higher param models with larger quantization needed for success.
Reasoning - quantization can impact a model's ability to reason.
Embeddings
We feed text into an embedding model to convert it to a vector. The size of this vector is dependent upon the model. The model converts text into a vector which represents the text in a number of numerical dimensions (some use low dimensions, some use high).
These vectors allow us to compare chunks of text and figure out their similarity.
Vector DBs and RAG
We can end up with a lot of chunks as part of a RAG pipeline. These can be stored in a vector DB. We need to store the chunk and the embedding for that chunk for efficiency. This allows us to take a new text query, create an embedding for it and then compare that generated embedding with the embeddings we have in our vector DB to find the most semantically similar ones. These similar chunks can be used to add context for your model as part of the prompt sent to the model.
Model Storage
When you pull a model, we get it's manifest:
 Source: Rifewang, Medium
Source: Rifewang, Medium
We see a model manifest defines a model as a bunch of layers like we would for a container. The digest referenced is in the blobs folder:
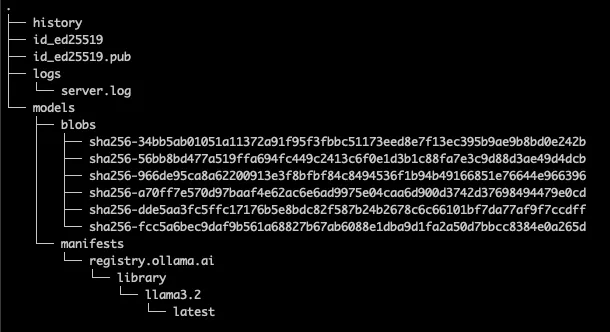 Source: Rifewang, Medium
Source: Rifewang, Medium
When you chat with a model, you can save that chat as part of the model using ollama save chatName which will create a new layer and add it to the manifest, saving the actual data into a file in the blobs directory.
Modelfiles
Template, Params, System Prompt, License - these are the components that make up a model in Ollama.
Modelfiles allow us to customize existing LLMs with prompts, message history etc then create a model based on that file which can be served and used.
- FROM - the base model to use e.g.
FROM llama3.2 - PARAMATER - set various parameters including:
- num_ctx - Context window size
- temperature - the temperature to use
- stop - set the stop sequence to use
- TEMPLATE - define a template for what gets passed to the model using Go template syntax
- SYSTEM - the system prompt to use in the template
- ADAPTER - LoRA adapters to apply to the base model
- LICENSE - any license to include
- MESSAGE - a message history for the model to use, for example:
MESSAGE user Is Toronto in Canada?
MESSAGE assistant yes
Different models can use different prompt formats.
GGUF and Safetensors
These are different formats a model can be saved in. GGUF encodes the tensor data and a set of metadata:
 Source: HuggingFace
Source: HuggingFace
In comparison, Safetensor format only stores the tensor info:
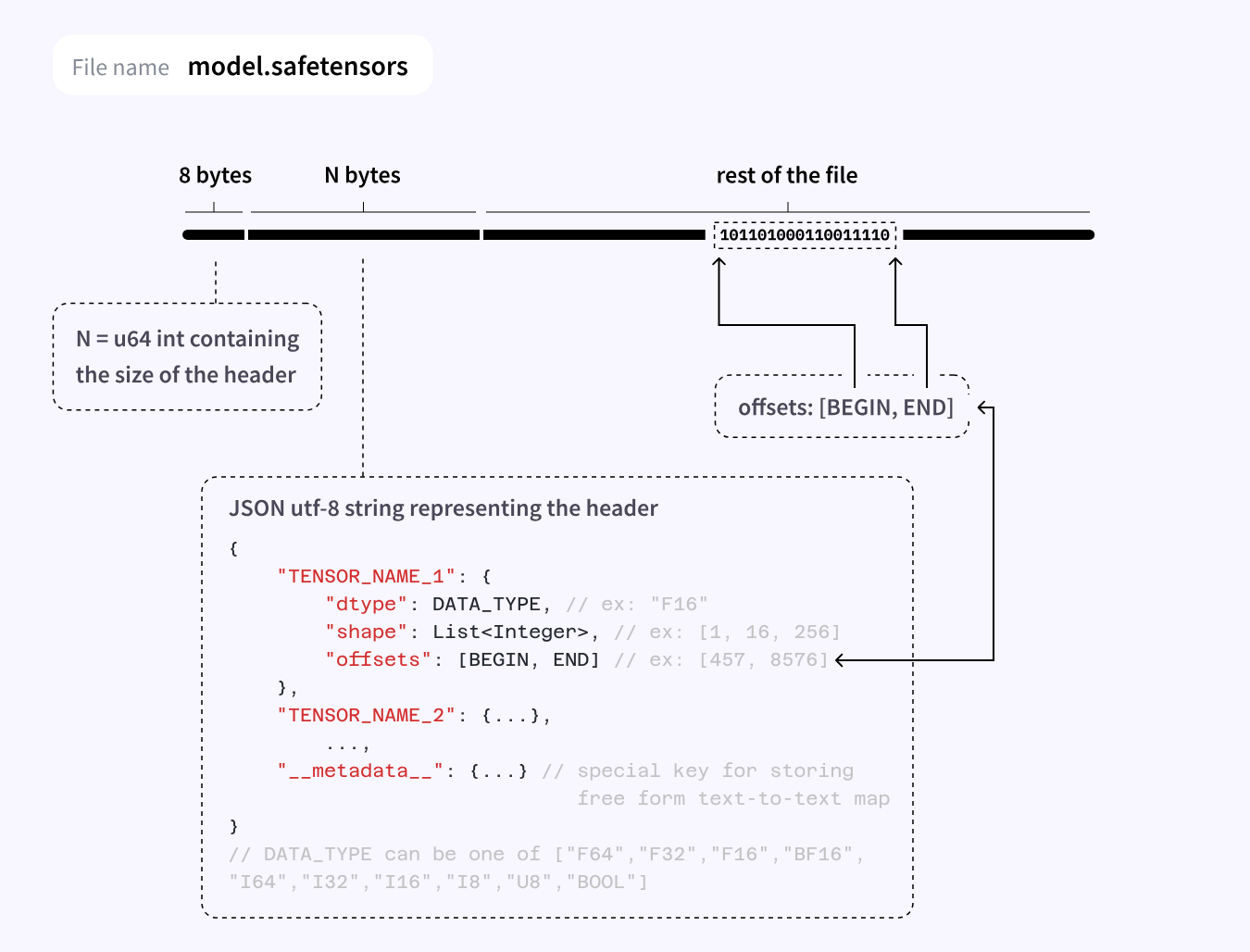 Source: HuggingFace
Source: HuggingFace
Llama.cpp Inference Engine
This is the actual inference engine being used to load models and serve them - Iam struggling to find high quality resources on how this actually works and how it compares to say the TensorFlow serving architecture (which is also used to serve models) or vLLM so will need to circle back in a future set of notes to compare different serving methodologies.
Links and Resources
https://medium.com/@gopichand5201/overview-of-ollama-architecture-deep-dive-8c03097d6996
https://www.youtube.com/playlist?list=PLvsHpqLkpw0fIT-WbjY-xBRxTftjwiTLB - Ollama Course, Matt Williams, founding maintainer of Ollama, Tech Evangelist at Ollama and DataDog.
https://github.com/ollama/ollama/blob/main/docs/modelfile.md - Modelfile docs
https://huggingface.co/docs/safetensors/index - Safetensor format, Huggingface