Architecting an AI Inference Stack
Notes on architecting AI inference stacks and TPUs from Google's learning path, "Inference on TPUs".

Architecting an AI Inference Stack
The state of the art is rapidly changing and there is a high cost of change.
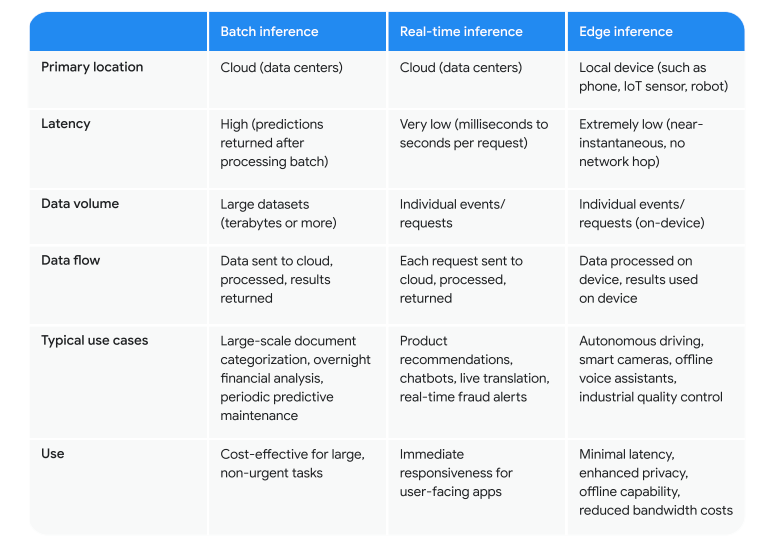
What is Inference?
The way we use a model to do something useful. Using a trained model. Needs to be fast, scalable and cost-effective.
AI Serving - infra and process required to deploy a trained model and available at scale.
Frameworks for AI/ML
Keras
An API for building models, neural networks. Multi-backend. Works with different execution engines.
Pytorch and Jax
Numerical computing librarys. Used for model definitions.
Can also use all 3 to train models.
Inference
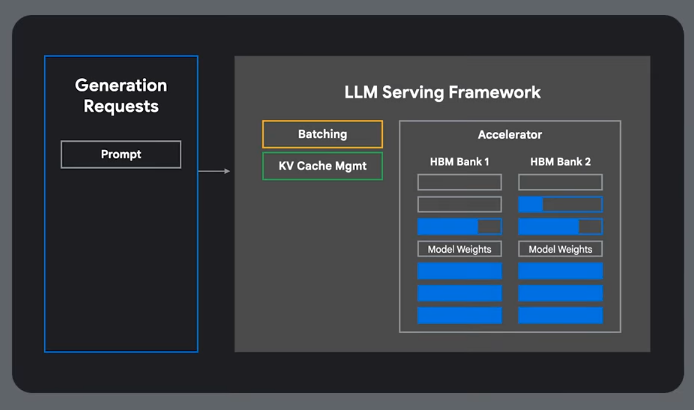
Need dedicated inference engines and frameworks.
NVIDIA Triton Framework
TGI Huggingface
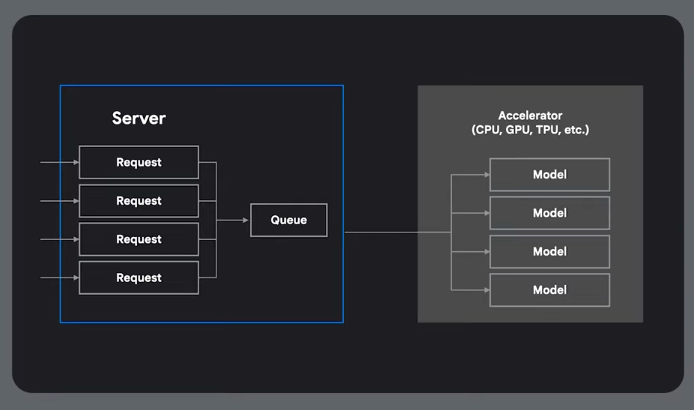
vLLM
General LLM serving

LLMD
For large scale deployments
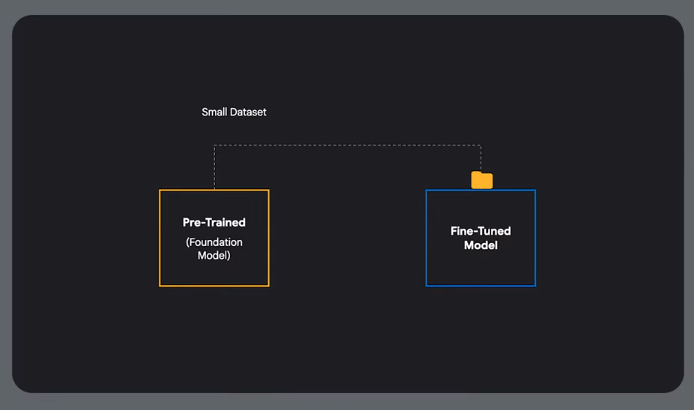
Fine tuning
Adapting an existing model for a domain or task
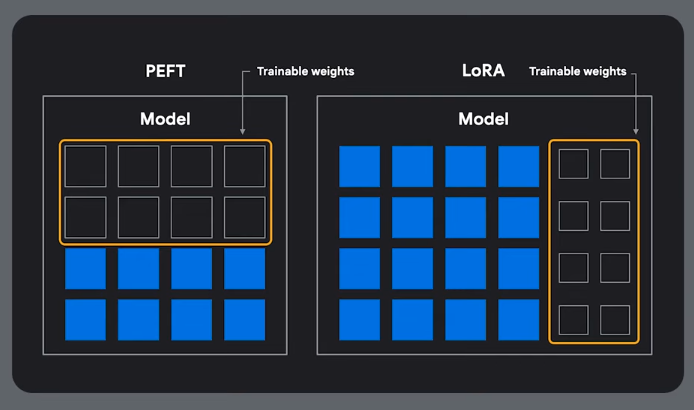
PEFT and LoRA
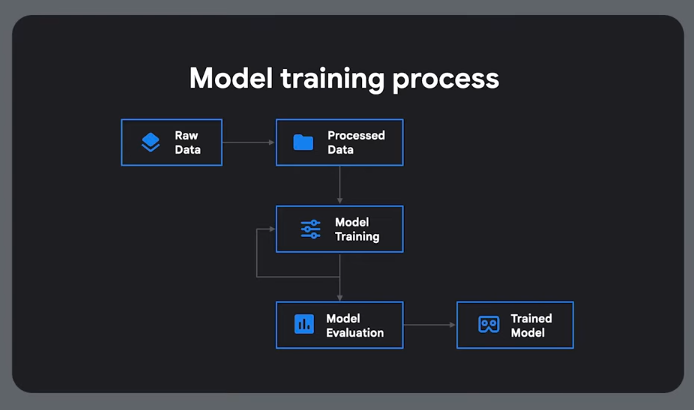
Defining and Training, Inference and Fine Tuning

Model types and Performance Bottlenecks
Compute, memory, memory bandwidth and network.
Types of models:

LLMS
Diffusion - Text to Image
Visual Language Models - multi modal
Mixture of Experts
Common Bottlenecks
Compute Bound
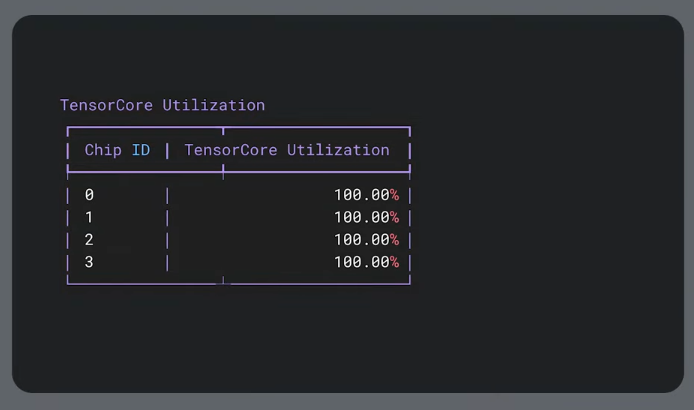
During training of dense models or diffusion inference. Add more chips.
Memory Bound
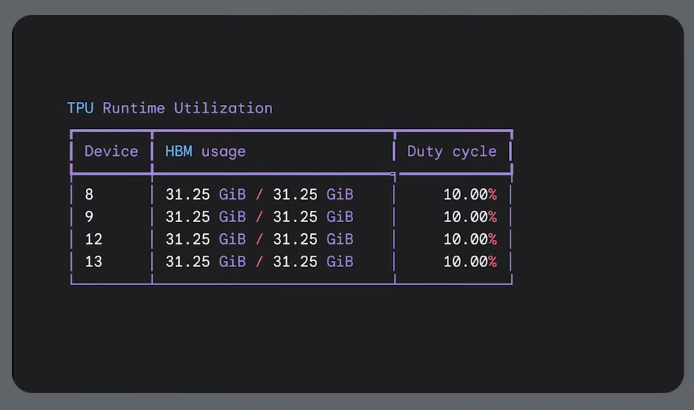
Provision high memory machines.
Quantize the model down to 8 or 4 bits.
Memory Bandwidth Bound
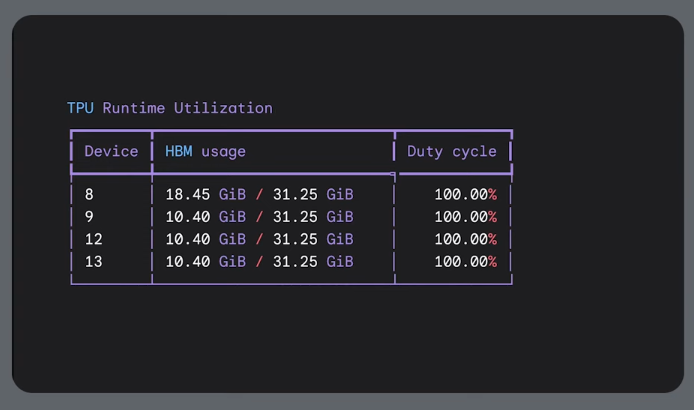
The TPU is waiting for data. You need to move data from memory to the TPU. MOE models can suffer from this.
Network Bound
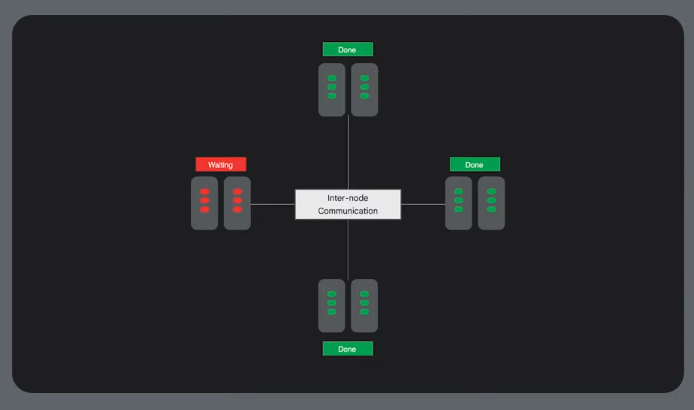
When you need to split the model across multiple machines. Distributed training and large scale MOE models - can require a low latency interconnect.
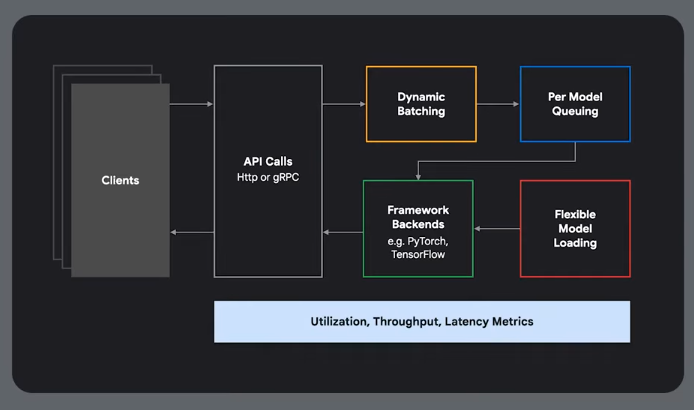
Orchestration
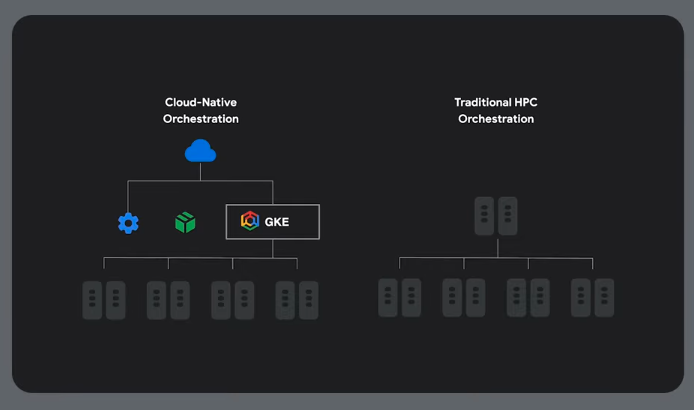
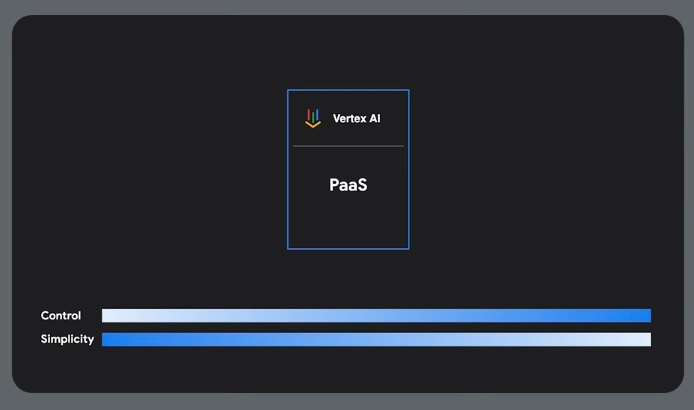
Vertx AI is a managed Google solution.
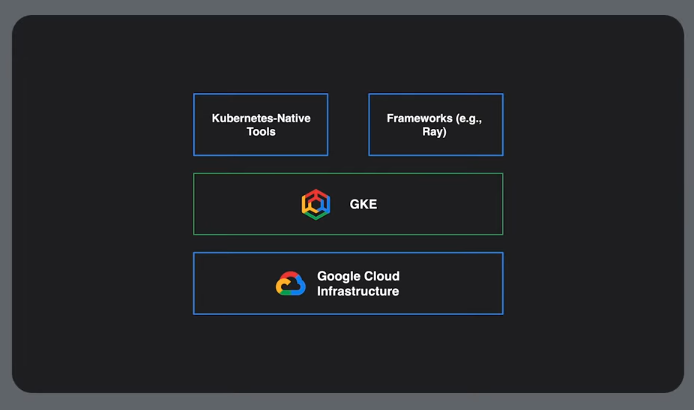
GKE Approach
Hardware and job orchestration
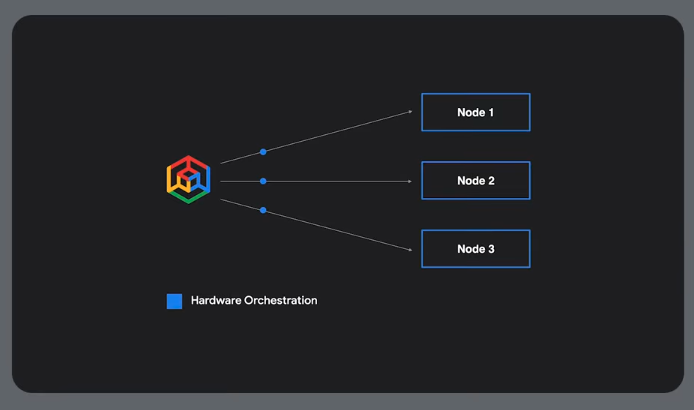
Can also use leader-worker sets, or a framework like RAY to distribute tasks.
Slurm/HPC Approach
Use Google's cluster director.

vLLM for Throughout and Lower Latency
Memory Inefficiency
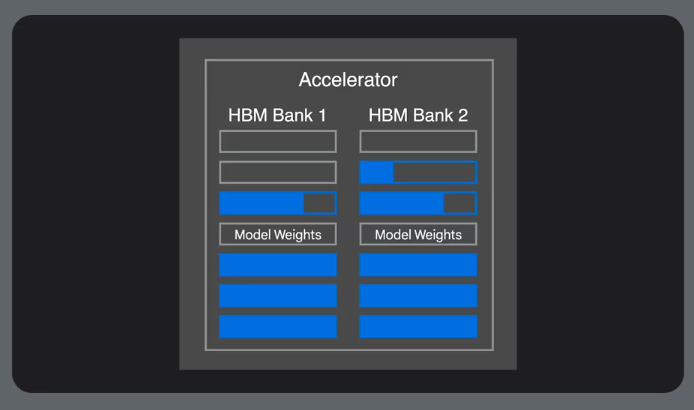
Standard practices are memory inefficient.
Latency from Queing
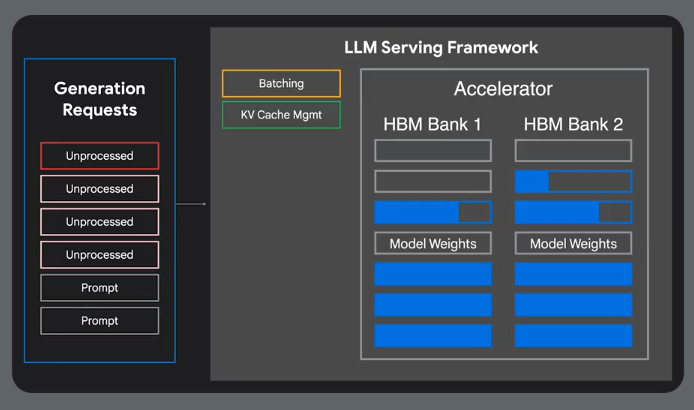
Multi host serving due to large memory requirements
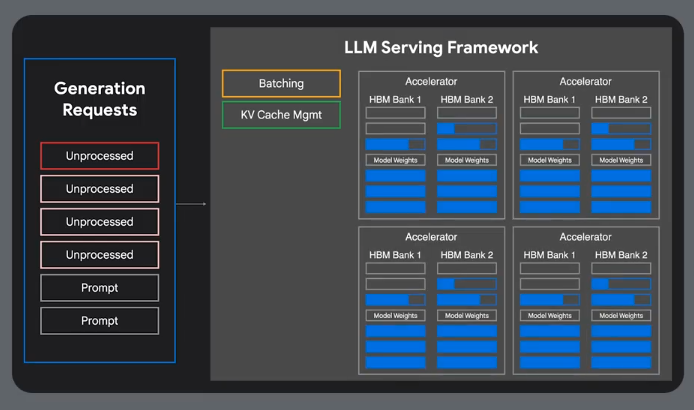
vLLM

-
Paged attention - manages model memory in non-contingous blocks
-
Prefix caching - caches computation for shared prefixes
-
Multi-host serving - distribute the model across multiple GPUs and TPUs.

Has lots of tunable params.
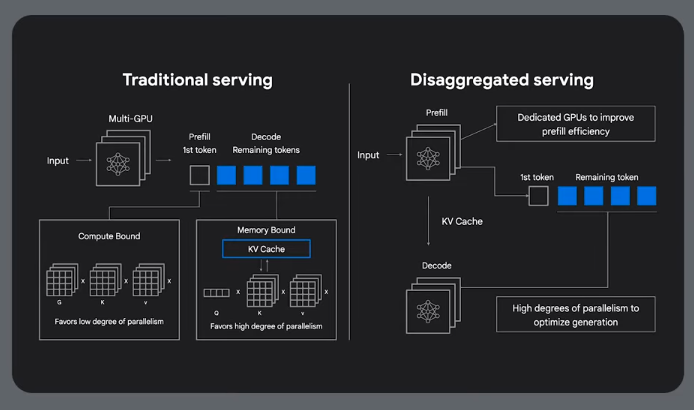
Prefill
Prefill: this stage processes the input prompt and
generates an intermediate representation (like a
key-value cache). It s often compute intensive.
Decode
Decode: this stage generates the output tokens,
one by one, using the prefill representation.
It is typically memory-bandwidth bound.
Disaggregated Serving
Seperating the prefill from the decode, allowing them to run in parallel to improve throughput and latency.
Scalable Inference
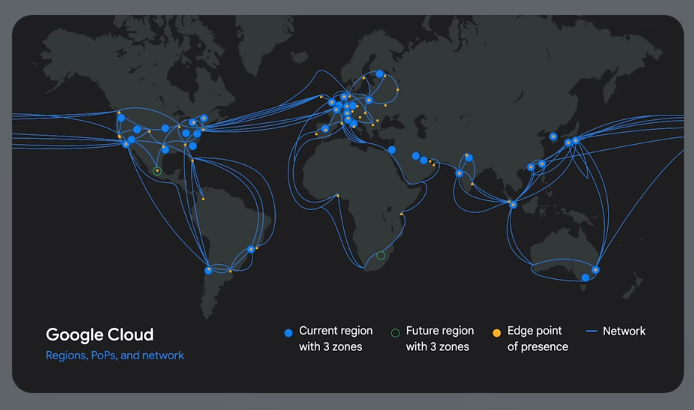
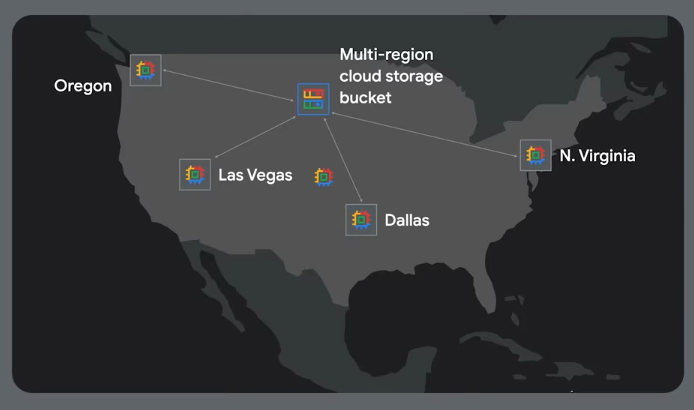
Multi-region setup:
Reduce end user latency.
Observability metrics:
You can also increase availability using a disaggregated serving approach:
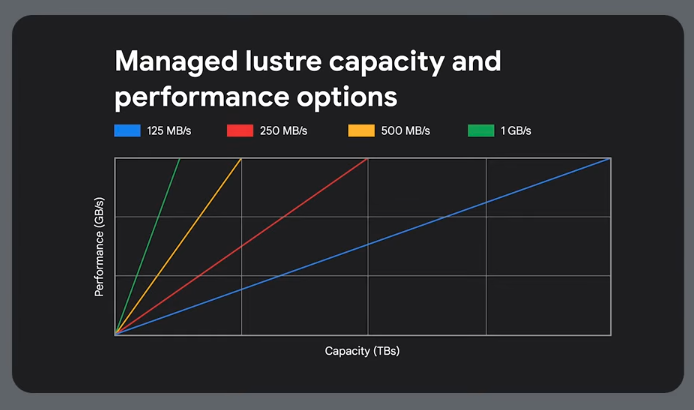
Storage
For cached data or at startup.

For low changing data use buckets:
For rapidly changing data
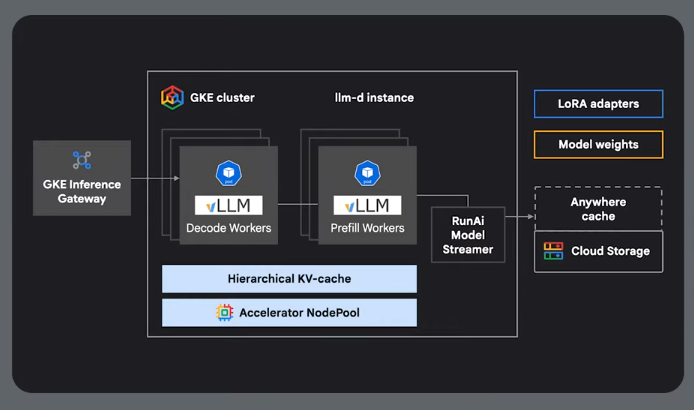
Reference Architecture
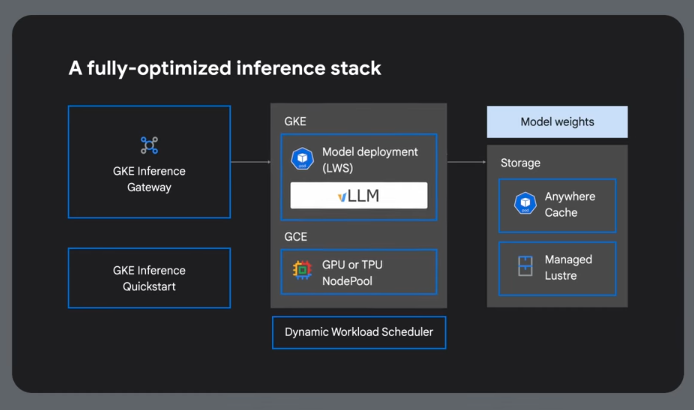
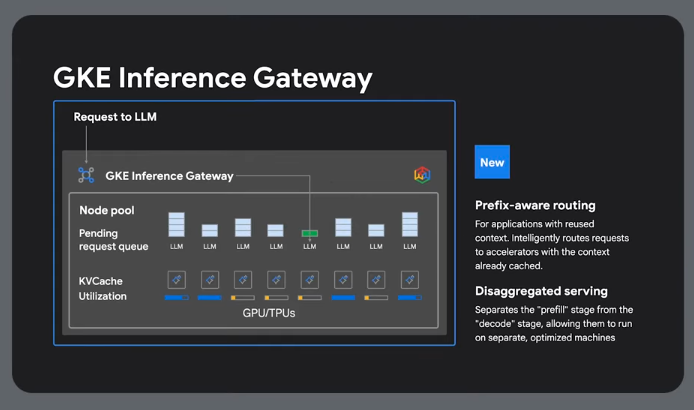
GKE Inference Gateway
GIQ - GKE Inference Quickstart
Analyzes benchmark data to identify the most cost-effective hardware configurations for specific performance needs.
Using TPUs for Inference
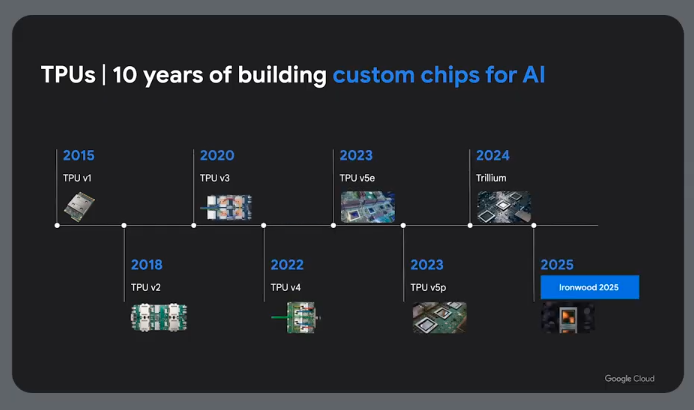
CPU - Central processing unit
GPU - Graphics processing unit
TPU - Tensor processing unit
Tensors
A data structure, a multi-dimensional array of numbers.
CPUs
CPUs offer flexibility. They load values from memory, do something with them and store them back in memory. Memory access is slow vs calculation speed and can limit the CPU's throughput (von Neumann bottleneck).
GPUs
GPUs were originally created for rendering and graphics workloads. Has thousands of smaller cores or ALUs allowing for a high level of paralellism. This is important for things like matrix operations. GPUs must also access registers and shared memory to read operands and store intermediate results.
TPUs
A TPU is a custom ASIC made by Google. They are designed specifically for tensor operations. Their primary task is matrix processing, multiplication and accumulation.
TPUs use a sytolic array architecture - a matrix of physically connected multiply-accumulators.
HBM = High bandwidth memory
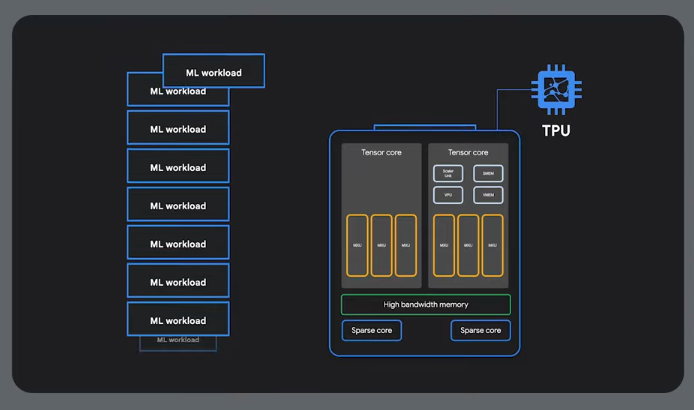
TPU Process
-
TPU host streams data into an inbound queue
-
TPU loads data from the queue and stores it in HBM memory
-
Post computation the results get dropped onto an outbound queue
-
TPU host reads the results from the outbound queue and puts them into the host's memory
-
To do matrix operations, params are loaded from HBM memory into a matrix multiplication unit
-
TPU loads data from HBM memory
Cloud TPU Architecture
Hardware utilization is important.
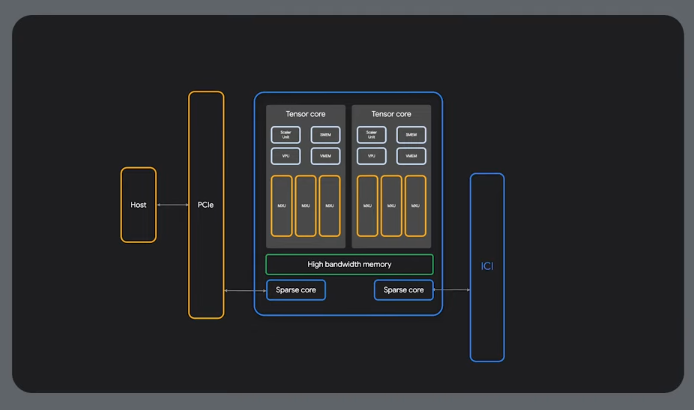
Data flows through the systolic array
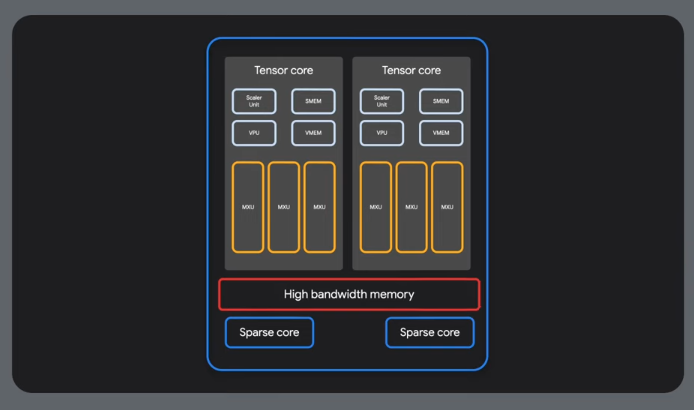
Sparse cores - used for sparse data.
MXUs - for dense calculations
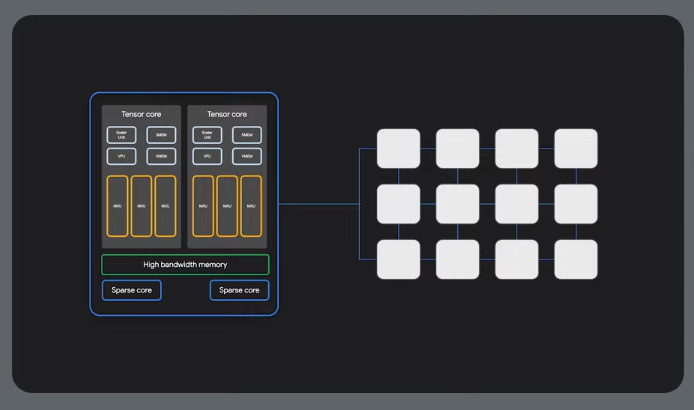
Physical organisation
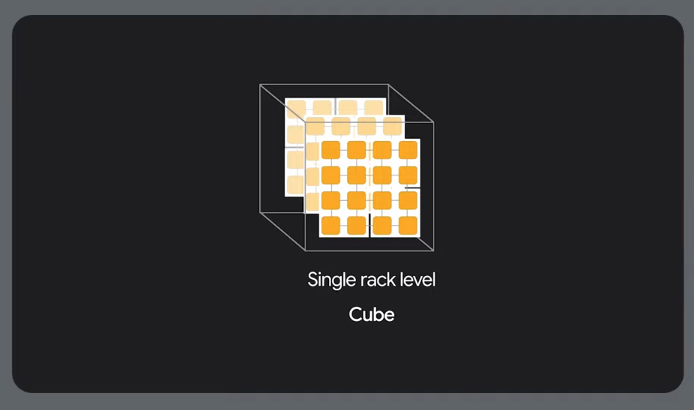
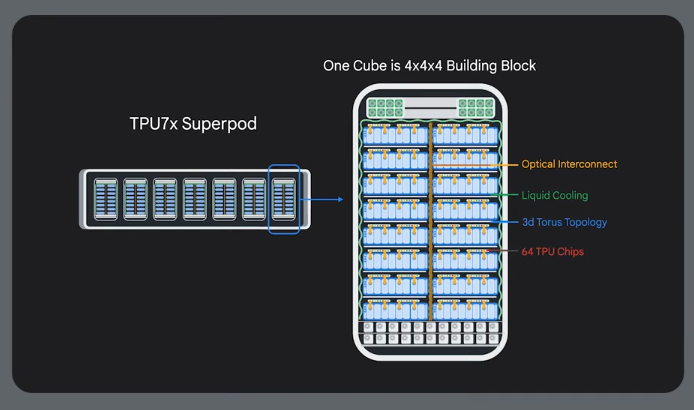
64x64 cubes
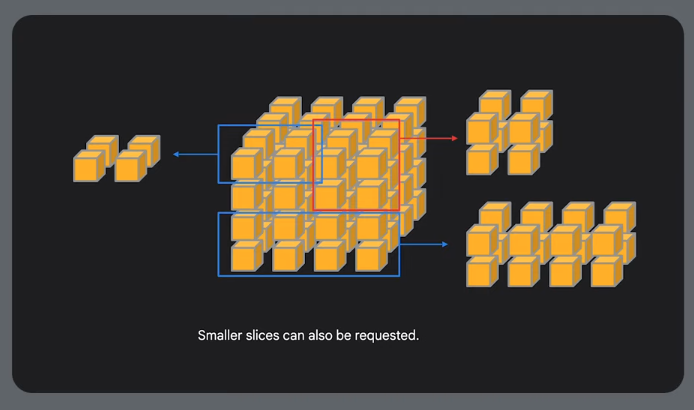
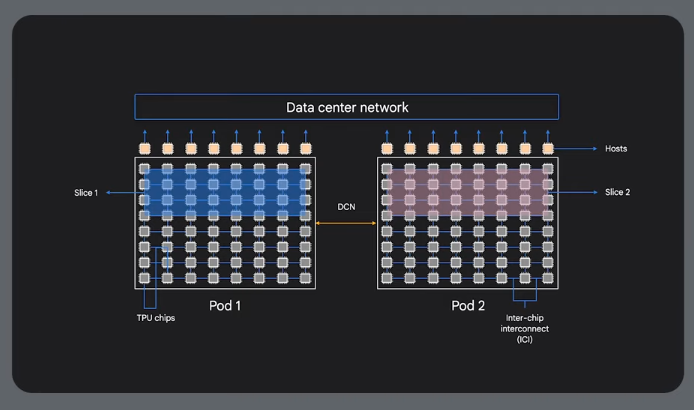
Slices
High speed slice interconnect (ICI or inter-chip interconneect) - neighbour connectivity:

Useful for distributed training.
Built in resilience and routing.
Multi-slice training across data centres
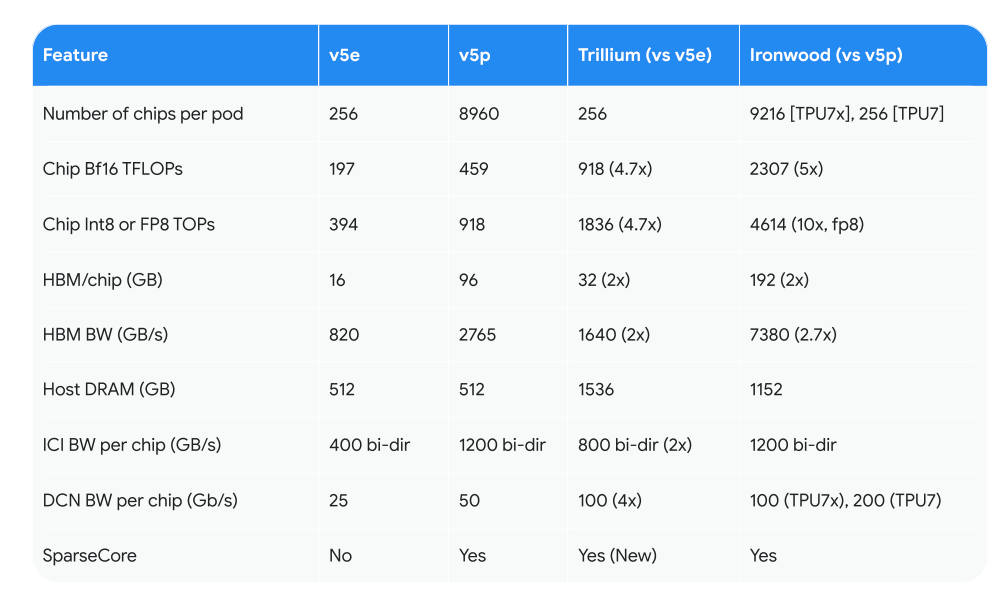
There are a variety of TPUs that balance memory, cost etc making them more or less useful for training vs inference.
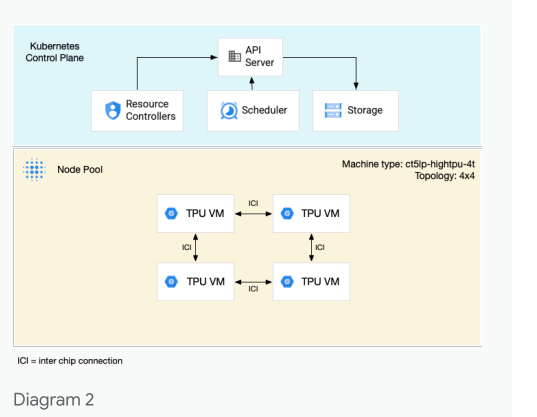
TPU Cloud Architecture
Made available on Google cloud as compute resources, as TPU VMs.

Or also on K8s:
Consumption and Usage
-
Speed - how quickly do you need the TPU compute capacity
-
Duration - how long do you need it for
-
Batch or online inference?
-
Can your workload tolerate pre-emption
-
Pricing/budget

CUDS - Commited use discounts
DWS - Dynamic workload scheduler
Calendar - Reserved capacity for a specific amount of time
Flex-start - Start time flexibility, batch jobs, not pre-emptible
vLLM GPUs and TPUs
Use a dual container approach within a single pod to support both GPUs and TPUs as the base image is different. Only one vLLM server will be active based on the underlying hardware.
This also allows us to use GKE for scaling and have new nodes come online which could be GPUs or TPUs.
Links and Resources
Fast and efficient AI inference with new NVIDIA Dynamo recipe
Scalable and Distributed LLM Inference on GKE with vLLM
Set up a Google Cloud project for TPUs
JAX and Keras for LLM Development using TPU for Distributed Fine-Tuning