Deepmind AI Research Foundations Part 1
Notes I took whilst studying "Google DeepMind: AI Research Foundations". Covers building your own small language model and language representation.

The Power of Language Models
Most languages share common patterns:
- Syntax - the way words are put together
- Semantics - the meaning of words
- Contextual dependencies
It's because of these common patterns that language is learnable - this is what language models are based on.
Language models mostly predict the next word in a sequence based on the previous word. There is a distribution of next possible words and typically we chose the most likely as the prediction of the next word.
Language models are also a general framework for processing and analyzing any kind of sequential data including music.
LLMS have a large capacity to encode patterns and knowledge.
SLMs are like LLMs but are trained on less data and have a smaller capacity.
Predict the next word
Sadly, this is probably more reflective of how I think an LLM creates a probability distribution than the way I talk:
To generate language you need to learn rules and patterns. You learn these patterns over time by listening and using language. The linguistic rules that language models use to generate text are captured using probabilities. Given the context, a good LM will assign high probabilities to sensible words and low probabilities to less sensible words.
The role of probabilities
An LM starts with some context. This is a sequence of words. It uses this context to predict the most likely next word and adds it to the sequence/context. It then makes the next prediction with this word included in the sequence/context. Eventually we get a full sentence. If the model chose words that didn't make sense, the text would probably be unintelligible and break implicit rules of a language.
There is an element of randomness (the temperature of the mode). Some level of random sampling improves diversity in what we're generating e.g. say we're generating stories, then if we have low temperature or something entirely deterministic then we'll get the same output/story.
LMs use a combination of probability distros and random sampling.
Think about the implications of language models in applications that influence communication. How do you think stereotypes or other types of biases in the input data could affect the predictions it makes and what steps could be taken to mitigate potential issues?
Also how biases in the input impacts predictive efficacy in non-word based language models.

N-Grams
"You shall know a word by the company it keeps"
- John Rupert Firth
We use statistical analysis to determine which words appear together (co-occurrence) or in similar contexts. We can measure not just the co-occurrence of words but also of larger units like sentences or even question-answer pairs.
- Unigrams - single words
- Bigrams - pairs of words
- Trigrams - three words
An n-gram is a sequence of n words that appear together.
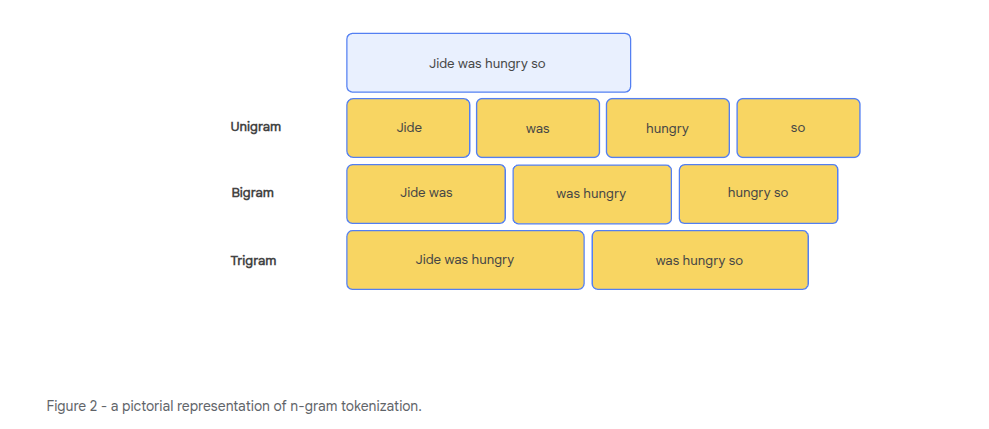
An n-gram models uses probabilities that are calculated from the count/distribution of different n-grams from a dataset.

For an n-gram model, the context window is the previous n-1 words e.g. for a trigram model, the context window contains 2 words and we are predicting the 3rd word.
Limitations of n-grams
- Small corpus (sample) size
- Unknown words out of sample
- Small datasets result in models that generate the same content
- Long range dependencies in the context window get ignored as we only look at the last n-1 words - the words before that are not used in the context window
Weighing values: Culture and ethics in the trolley problem
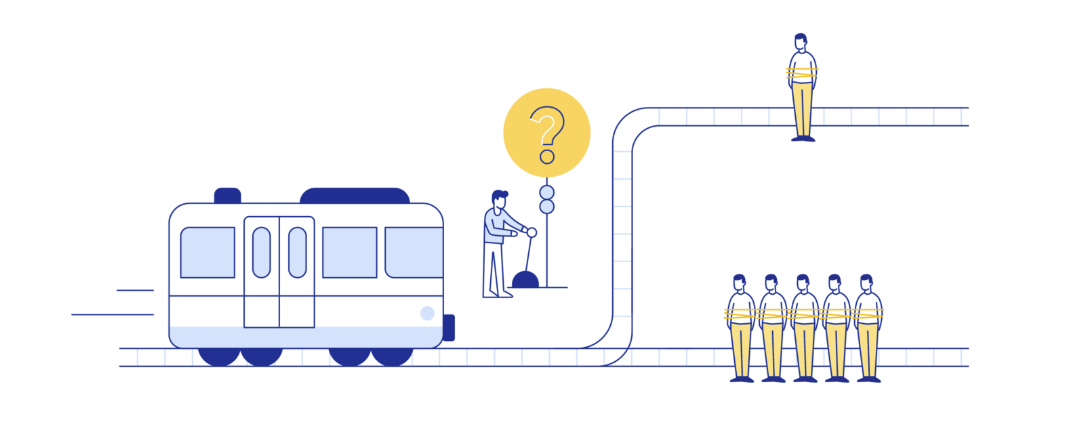
A train is headed for 5 people tied to the train tracks. A person can pull a lever and send the train to a track where only 1 person is tied too it.
Pulling the lever - we should strive to achieve maximal good regardless of what it takes (we save 5 people by killing 1)
Don't pull the lever - there are moral rules we should not violate like taking an action that leads to the loss of life i.e. your action of pulling the lever is what kills the 1 person, it is not your inaction (not pulling the lever) that would kill the 5 people but the fact the train is already heading towards them.
Decisions about who should live or die may be shaped by perceptions of worth based on social and cultural factors.
This problem can relate to LLMs e.g. autonomous vehicles may have to decide between hitting 1 of 2 people. Research shows that LLMs will make different decisions based on the language used - they reflect cultural biases and differences from their datasets.
LLMs make statistical calculations about prior statements on moral dilemmas. They do not undertake moral reasoning.
e.g. you train a model using a corpus on European and North American values (individual agency and rules based ethics) vs training a model using a corpus from an Eastern tradition like Daoism (non-interference and holistic thinking).
Anatomy of a Language Model
Inference - using a model to make predictions. Predicting or modelizing the probability distro over the next token given a context and the params of the model.
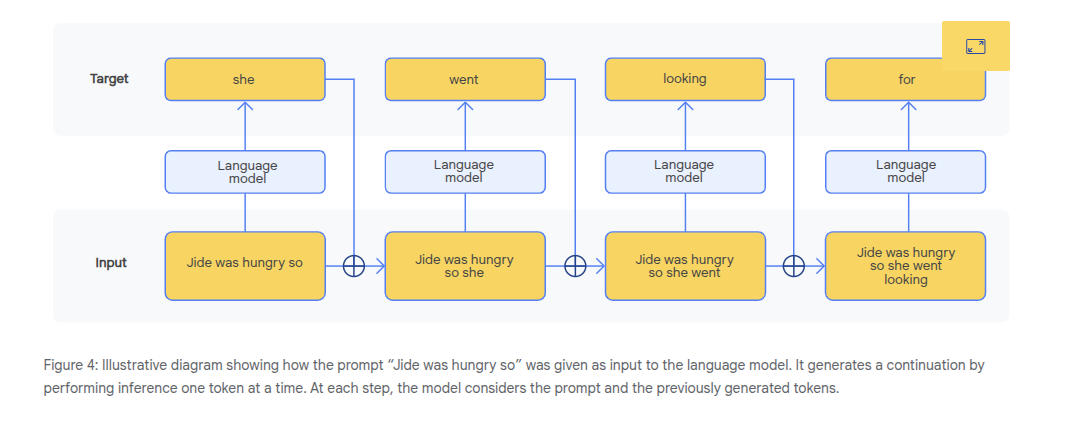
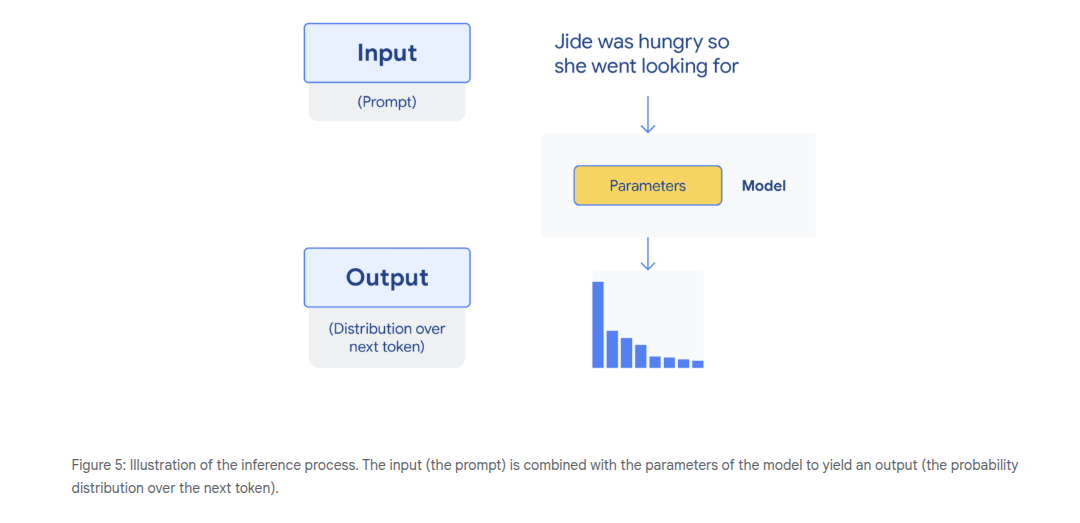
Transformers are neural networks. Their inputs must be a vector/list of numbers. We map specific tokens or words to numbers to do this. The output is the probability distro over these token identifiers (the numbers), which is then mapped back to words in order for it to be humanly readable.
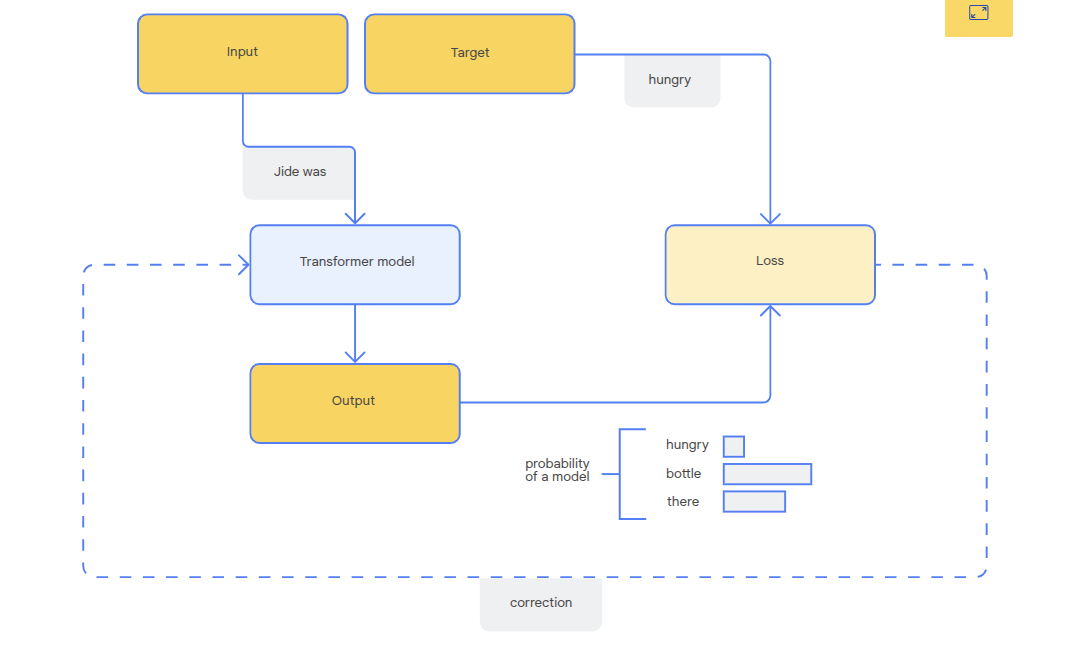
Training a Model
Training occurs using sets of inputs and target answers/responses.
- Predict - tries to predict the target given an input
- Compare - the prediction is compared to the actual target. The difference is the loss.
- Adjust - Model params are adjusted based on the loss in order to improve the next guess. This is an optimization phase.
You can easily get datasets for inputs and targets by processing existing text. For example:

As we train over time, we want to see decreasing loss - a sign that the model is getting better (capturing desired qualities, improving syntax, semantics and relevancy).
A well-trained model aims to find the underlying statistical regularities in the language, allowing it to generate coherent and meaningful text even when faced with novel prompts or contexts. This strikes a balance between learning the patterns in the training data and retaining the ability to generate creative and novel outputs.
ML Development Pipeline
Data
Preprocessing the data. Cleaning and preparing it for model training. Dependent on the scenario but can involve removing duplicates, emojis and removing typos.
At this stage you can also remove harmful or biased text. Once the data quality is good, the text can be tokenized.
Locally relevant models are more complex - handle code switching, dialects and low-resource languages (small digital sample size).
Train
The cost of training is high - computing power and energy. Lots of projects leverage existing pre-trained models like Gemma as a starting point, because they already have language understanding and broad general knowledge.
Fine Tune
Adapting a model for a particular purpose or behaviour.
-
Supervised fine tuning (SFT) - taking a pre-trained model and training it on a smaller more focused dataset for that task.
-
Reinforcement learning from human feedback (RLHF) - aligns AI behaviour with human preferences.
Evaluate
Accuracy, performance, safety, fairness and overall usefulness. Models are evaluated on specific benchmarks - the development of these benchmarks is also critical in research.
Human eval - rating the quality of responses, done by a human. Includes A/B testing models.
Deploy
Once evaluation criteria are met, a model can be deployed for real world use. Ongoing monitoring and evaluation feeds back into the development cycle in order to refine and update the model.
The key lies in adapting each stage of this pipeline to the specific task and the unique linguistic, cultural, and infrastructural realities of the target region. Building local expertise to manage this pipeline is essential for creating truly impactful AI solutions.
Evaluating a Model
Determining if your model is good at a specific task; that which it was designed for.
-
Factual accuracy - model output aligns with trusted knowledge base
-
Relevance - does an answer directly address user's question
-
Safety - e.g. not giving financial or legal advise
-
Fluency - does it generate things which are gramatically correct, structured correctly
-
Thematic and stylistic coherence
-
Context sensitivity - how does output vary with changes to context
-
Bias
Metrics
Curate input promps and corresponding ideal outputs. Compute metrics by comparing model output to the ideal.
This approach is fast and cheap, allowing you to quickly check if a change to your model made it better or worse. However, these metrics are often superficial and cannot truly capture qualities like creativity or factual correctness.
You can monitor training loss to see if it's decreasing.
Human judgement - rating scales, AB testing, qualitative feedback

Developing a Problem Statement
The problem statement describes the issue or gap you are looking to address and explains why the research is needed.
Developing a problem statement is a core research skill. It forces you to clarify exactly what you believe is worth exploring or building, and why it matters.
A good problem statement:
- Define the core issue that the research aims to address
- Provide context and background
- Specific with boundaries and scope
- Realistic
- Justify the need for resources

Represent Your Language Data
Before a model can process text, you must first decide on the fundamental units it will work with.
You need to find a way to represent meaning - it's relationships and context in a numerical format.
The steps in all language models to solve these challenges:
- Preprocessing - cleaning your input
- Tokenization - defining what a word is
- Embeddings - a vector or coordinate in high dimensional space to map meaning
What is Code Switching?
The practice of alternating between languages, dialects, accents, or cultural behaviors to align with the social norms of a specific setting or audience.
Pre-Processing
Context depenends on the problem we're looking to solve.
- What information is important to accomplish my task?
- What noise is getting in the way?
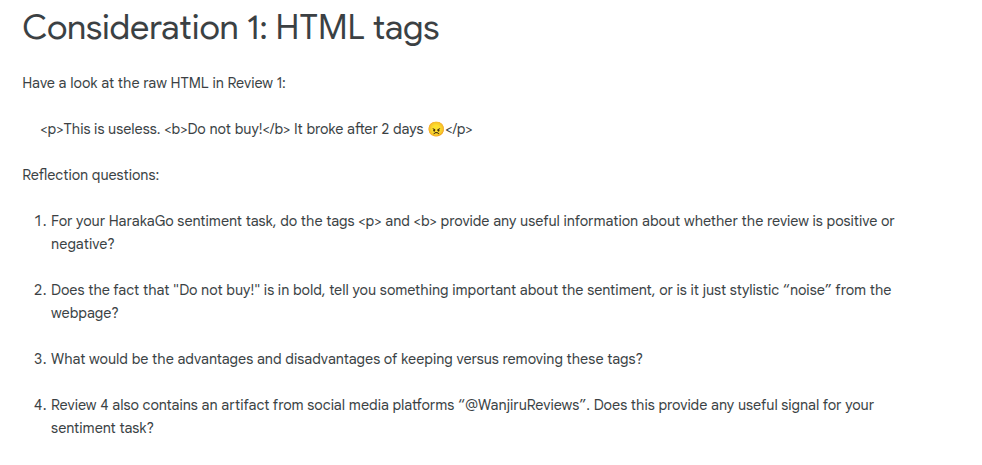
SOmetimes HTML tags do add information e.g. if you're processing a news article or a product page, then things like headings or list items in HTML add information for the model.
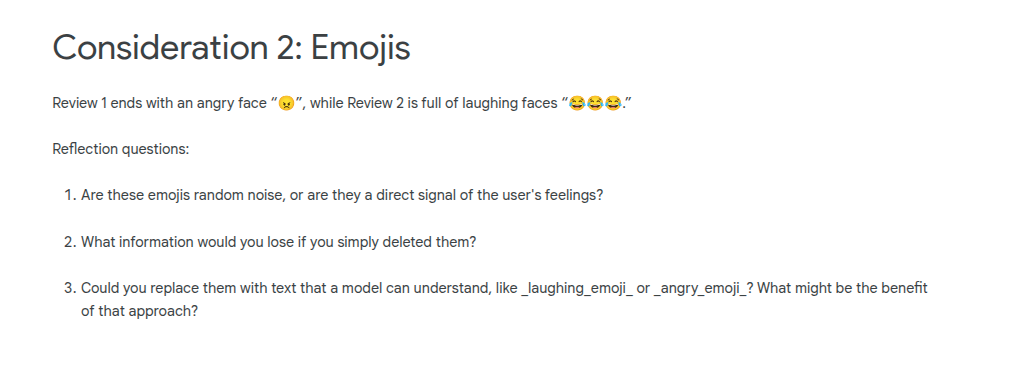
Emojis are a language independent signal of emotion and sentiment. However, if your input is something like a medical research paper, then emojis may just be noise so should be stripped out.

This example requires understanding local language and slang.
Low Resource Languages
Because training an LLM from scratch requires a large amount of quality data, other low resource languages which are more niche or not so widely used end up being left behind.
This can also be a probem for NER (named entity recognition) which requires curation of specific datasets with annotations.
An example is FLORES-200 data set. It supports 200 languages, which is great, but of it is based on English centric content. When it gets translated, important cultural details like local food, greetings, clothing can be lost or misrepresented.
Direct translation of language can also lead to mis-interpretation and a lack of cultural context.
Data Resources
SMOL
A 6.1m word corpus from Google with professionally transalted parallel data in English and 115 other languages.
TICO-19
69k word corpus containing COVID-19 material in a variety of languages.
MasakhaNER
NER across 20 African languages
TinyStories
2m short stories from Microsoft Research using words understood by 3-4 year olds.
AfriSenti
Sentiment analysis data including 110k annotated tweets in 14 African languages.
What is Tokenization
Converting words into numerical format.
Sentence level tokenization
You make each sentence it's own unique token. It would be rare to see the same token twice or many times, making it hard to learn patterns.
Tokens are large and not repetitive enough for learning.
Word level tokenization
Each word is a token. Models can learn statistical relationships between tokens. The problem comes from out of vocabulary tokens.
Unknown vocab tokens are ignored or mapped to an <UNK> token.
Character Level tokenization
Each character is a token.
Loss of meaning - semantic concept of multiple characters is lost.
Inefficient sequences - long sequences, harder to learn patterns between distant parts of the text.
No out of vocab issues, but less meaningful on their own and computationally inefficient.
Zipf's Law
A small number of tokens are very common e.g. "the", "a", "and". If a token is only encountered a few times, it is hard to learn it's meaning.
This gives us a long tail distro of token frequency. We can use a log-log plot to rescale and view this better (log of the rank vs log of the frequency).

log-log plots reveal power relationships as a straight line.
Tokenization and Vocab Size
The size of the vocabulary is a critical design
choice that involves significant trade-offs.
A larger vocabulary allows for more information
to be distributed across tokens. With a
word-level vocabulary, tokens are whole words.
The distinct meanings of "time" and "the" are
captured in separate, specific token
representations. Information is clearly
distributed. With a character-level vocabulary,
on the other hand, the token "t" must contribute
to representing every word containing it, such as
"time", "the", and "train." This forces a single
token's parameters to hold a vast amount of
contextual information, making it difficult for
the model to learn representations that capture
precise meaning.
A larger vocabulary requires more parameters for
a model, which directly increases its size and
computational cost. Each token needs a unique
representation stored in the model's parameters.
A bigger vocabulary thus leads to a larger model
that demands more memory and processing power,
making both training and inference slower and
more expensive.
A larger vocabulary inevitably contains more
tokens that appear very infrequently in the
training data. The model cannot learn a reliable
representation for these rare tokens because it
lacks sufficient examples of their usage. This
"data sparsity" problem hinders the model's
ability to handle less common words or concepts
effectively.
Sub-word Tokenization
A compromise between character and word level encoding.
Simple words are kept as complete tokens.
Complex or rare words are broken down into smaller units.
BPE - Byte pair encoding.
Gemma Tokenizer has an expansive vocab which can help with <UNK> tokens.
# Load the tokenizer.
gemma_tokenizer = gm.text.Gemma3Tokenizer()
# Inspect the vocabaulary size.
print(f"Gemma's vocabulary consists of {gemma_tokenizer.vocab_size:,} tokens.")
<BOS> = Beginning of sequence
<EOS> = End of sequence
These are used for efficieny batching during training, but also during text generation they can demarc start and end of the sequence.
<PAD> = A padding token
BPE Algorithm
Starts with individual characters, iteratively merging the most frequent pairs into new larger tokens.
Example:
Frequencies from corpus:

Split each word into characrts and demarcate them with an end of word symbol.

We have a base vocabulary from the training data, but in practice we enumerate all 256 values if the base vocab is short. This prevents the tokenizer from mapping any characters that do not appear in the training data to the unknown token.
We then tally adjacent pairs:
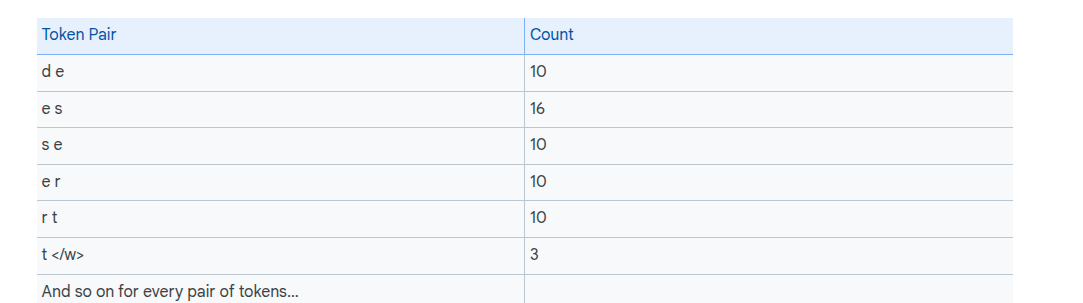
We then merge the most frequent pair, which is "es" in our case, into a single token.
We replace the values of "es" in the dataset with a token representing the new merged token:

We then repeat these steps.
When the model comes across words it hasn't seen before e.g. deserts, it can replace it with 2 words it does know i.e. "desert" and "s</w>"
You end up with a model that is much more robust towards small variations such as the difference between “test” and “tests”.

Vocab-size tradeoff
If we merge adjacent bytes infrequently, the vocab size ends up being small. Good for handling new and rare words. Low number of merges makes it more similar to a character level tokenizer.
If we merge too frequently, we end up with shorter sequences but the vocab becomes very large. May end up overfitting to the training set.
Tokenizer Tax
A tokenizer trained on a different language may end up having to break down relevant sub words into characters as it has not encountered them before. This leads to more tokens. You get charged by the token, therefore this is referred to as a tokenizer tax.
You can overcome this by using a custom tokenizer trained on your data.

Embeddings
A tokenizer lets us map a word to a numeric ID. We need a representation that captures relationships and nuances of language.
Each token ID is mapped to a list of numbers, a vector. The entire mapping is implemented for each token in a lookup table. This is an embedding.
Think of it like creating a map. Trying to describe the location of every city
in the world using a single, arbitrary ID number would be useless for navigation.
Instead, you use coordinates like latitude and longitude. These two numbers place
each city on a 2D map, allowing us to see that Agadir is close to Marrakesh and
very far from Tokyo. We can measure distances and understand the relationships
between them.
Token embeddings do the same thing for tokens, but instead of a 2D map of
geography, they create a high-dimensional "map of meaning".

Each number in the vector conceptually represents a token's position along a different axis of meaning. During training, the model learns to place tokens with similar meanings close together in this space.
The embeddings start as a matrix of random numbers. The model learns that to make better predictions through training - words appearing in similar context get pushed together, those with different meanings are pushed apart.
Design your own Embeddings
Words have many meanings and relationships - a single dimension can only represent a single axis of meaning at a time. This makes it hard to represent multiple relationships at once
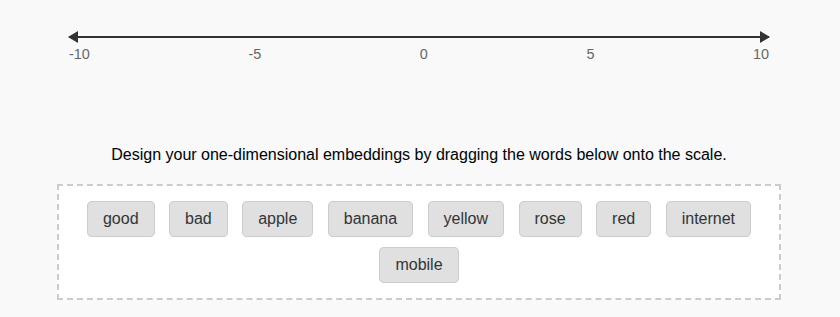
You can add more dimensions e.g. one dimension for good vs bad (sentiment), another for seperating fruits from technology and a third dimension for colour.
Modern language models use hundreds or even thousands of
dimensions to represent the vast contexts in which tokens appear.
Desired Properties of Embeddings
Meaningful Neighbours
TOkens with similar meanings should be close together. Semantic neighbourhoods.
We measure similarity using cosine similarity:
1 = Vectors point in the same direction
0 = Vectors are orthogonal/unrelated
-1 = Vectors point in opposite directions, they're opposites

Dense Representations
In a sparse representation, many dimensions can be 0 for a particular word.
In a dense representation, almost every number in the vector is non zero and contributes to the overall meaning. These dimensions are statistical and may not be easy for humans to interpret, but allow for capturing complexity and subtlty.
Visualizaing a Meaning Space
-
Direct plotting - pick a few dimensions to graph
-
Dimension reduction - e.g. PCA to reduce the dimensions
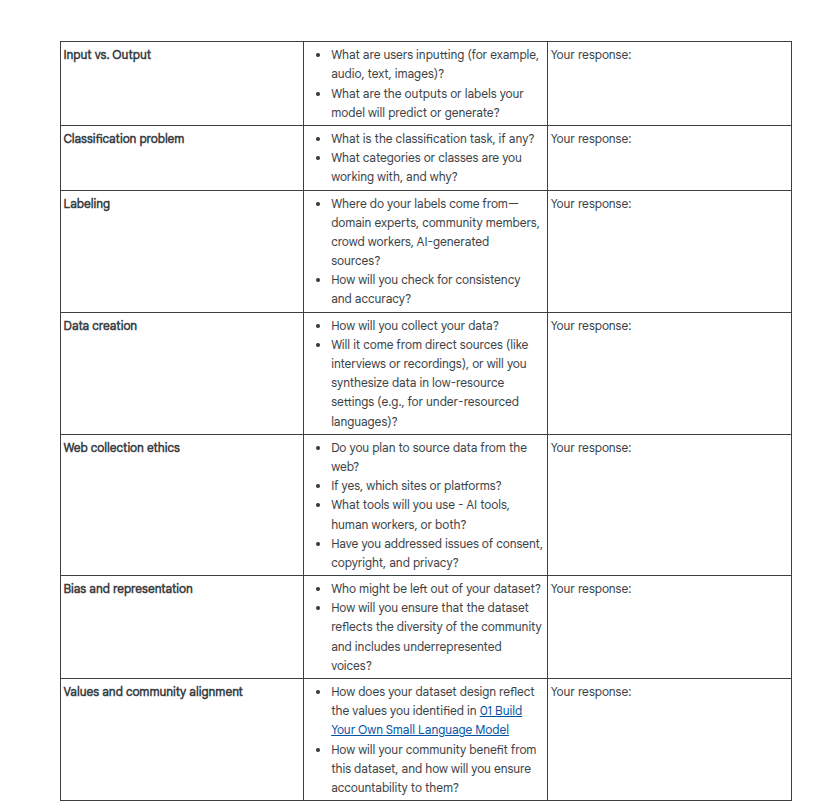
Data Card Template
For documenting decisions in an accountable way:
Links and Resources
Research paper by Ronen Eldan and Yuanzhi Li – TinyStories: How Small Can Language Models Be and Still Speak Coherent English? [1]
The TinyStories dataset is a large collection of short, fictional narratives designed for training language models in creative writing. It consists of over one million stories, each averaging around 100 words, covering diverse themes and genres. It provides a rich resource for learning narrative structure and storytelling. This paper provides an introduction to the project.
[1] Ronen Eldan and Yuanzhi Li. 2023. Tiny Stories: How Small Can Language Models Be and Still Speak Coherent English. arXiv preprint. arXiv:2305.07759. Retrieved from https://arxiv.org/pdf/2305.07759'
Article by Google for Developers – Supervised Learning [2]
This short article provides an overview of supervised machine learning and summarizes core concepts such as data, model, training, evaluating, and inference.
[2] Google for Developers. 2025. Supervised Learning. Retrieved from https://developers.google.com/machine-learning/intro-to-ml/supervised
Article by Google for Developers – Prepare Your Data [3]
This article provides a detailed account of the processes of tokenization and vectorization. It includes a number of examples and provides an introduction to key concepts such as one-hot encoding and word embeddings.
[3] Google for Developers. 2025. Step 3: Prepare Your Data. Retrieved from https://developers.google.com/machine-learning/guides/text-classification/step-3
[Orevaoghene Ahia, Sachin Kumar, Hila Gonen, Jungo Kasai, David R. Mortensen, Noah A. Smith, and Yulia Tsvetkov. 2023. Do All Languages Cost the Same? Tokenization in the Era of Commercial Language Models. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. Retrieved from https://doi.org/10.18653/v1/2023.emnlp-main.893.
Research paper - Timnit Gebru, Jamie Morgenstern, Briana Vecchione, Jennifer Wortman Vaughan, Hanna Wallach, Hal Daumé Iii, and Kate Crawford - Datasheets for Dataset
A foundational piece on ethical dataset practices. This paper proposes a structured way to document datasets similar to a “nutrition label”, so others can understand their limitations, risks, and intended uses. It underpins the Data Card approach you have been working with in this course [1].
[1] Timnit Gebru, Jamie Morgenstern, Briana Vecchione, Jennifer Wortman Vaughan, Hanna Wallach, Hal Daumé Iii, and Kate Crawford. 2021. Datasheets for datasets. Communications of the ACM. 64, 12. 86-92. https://doi.org/10.48550/arXiv.1803.09010
Research paper - Wiebke Hutiri, Mircea Cimpoi, Morgan Scheuerman, Victoria Matthews, and Alice Xiang - TEDI: Trustworthy and Ethical Dataset Indicators to Analyze and Compare Dataset Documentation
This paper introduces a new framework for comparing dataset documentation practices. It will be useful if you want to evaluate how transparent and ethical different datasets are, and to think critically about what good documentation should look like [2].
[2] Wiebke Hutiri, Mircea Cimpoi, Morgan Scheuerman, Victoria Matthews, and Alice Xiang. 2025. TEDI: Trustworthy and Ethical Dataset Indicators to Analyze and Compare Dataset Documentation. arXiv preprint. arXiv:2505.17841. https://doi.org/10.48550/arXiv.2505.17841
Research article - Wendy H. Wong - Don’t Forget That There Are People in the Data: LLMs in the Context of Human Rights: A Response to Samuel R. Bowman
This article reminds us that datasets are not neutral: they contain traces of real human lives, cultures, and rights. It connects data ethics to human rights, making clear why ownership, consent, and representation are not just technical issues but matters of justice [3].
[3] Wendy H Wong. 2024. Don't Forget That There Are People in the Data: LLMs in the Context of Human Rights: A Response to Samuel R. Bowman. Critical AI. 2, 2. https://doi.org/10.1215/2834703X-11556029
Research paper - Mehdi Ali, Michael Fromm, Klaudia Thellmann, Richard Rutmann, Max Lübbering, Johannes Leveling, Katrin Klug et al. - Tokenizer Choice For LLM Training: Negligible or Crucial?
This paper challenges the idea that choosing a tokenizer is a minor technical detail, showing that this single decision has a significant impact on both a model's final performance and its training cost. The authors find that common metrics used to evaluate tokenizers are not always reliable predictors of how well the final language model will perform, an important lesson for real-world model development [4].
[4] Mehdi Ali, Michael Fromm, Klaudia Thellmann, Richard Rutmann, Max Lübbering, Johannes Leveling, Katrin Klug et al. 2024. Tokenizer Choice for LLM Training: Negligible or crucial?. In Findings of the Association for Computational Linguistics: NAACL 2024. 3907-3924. https://doi.org/10.48550/arXiv.2310.08754
Research paper - Orevaoghene Ahia, Sachin Kumar, Hila Gonen, Jungo Kasai, David R. Mortensen, Noah A. Smith, and Yulia Tsvetkov - Do All Languages Cost the Same? Tokenization in the Era of Commercial Language Models
This paper provides data-driven evidence for the "tokenizer tax" that you learned about in this course. The authors conduct a systematic analysis across 22 languages and show that the choice of tokenizer is not just a technical detail but an issue of economic fairness and equity. The research shows that users working in many languages are forced to pay more for language model APIs, often for worse results, simply because the underlying tokenizers are not optimized for their language [5].
[5] Orevaoghene Ahia, Sachin Kumar, Hila Gonen, Jungo Kasai, David R. Mortensen, Noah A. Smith, and Yulia Tsvetkov. 2023. Do all languages cost the same? tokenization in the era of commercial language models. arXiv preprint. arXiv:2305.13707. https://doi.org/10.18653/v1/2023.emnlp-main.614
Resource: Gemma 3 Developer’s Guide
This resource provides details about the Gemma tokenizer that you have been experimenting with in this course [6].
[6] Google. 2025. Introducing Gemma 3. Retrieved from https://developers.googleblog.com/en/introducing-gemma3/
Textbook chapter - Daniel Jurafsky and James H. Martin - Words and Tokens
This textbook chapter provides an in-depth review of most of the topics in this course, including tokenization and the BPE algorithm [7].
[7] Daniel Jurafsky and James H. Martin. 2025. Words and tokens. In Speech and Language Processing: An Introduction to Natural Language Processing, Computational Linguistics, and Speech Recognition with Language Models, 3rd edition. Online manuscript released August 24, 2025. Retrieved from https://web.stanford.edu/~jurafsky/slp3/
Research paper - Tomas Mikolov, Kai Chen, Greg Corrado, and Jeffrey Dean - Efficient Estimation of Word Representations in Vector Space
This is a seminal paper that introduced a method to learn good word embeddings from large text datasets. While this paper was written before large language models were introduced, it discusses methodologies for evaluating word embeddings that are still relevant today [8].
[8] Tomas Mikolov, Kai Chen, Greg Corrado, and Jeffrey Dean. Efficient estimation of word representations in vector space. arXiv preprint. arXiv:1301.3781. https://doi.org/10.48550/arXiv.1301.3781