Deepmind AI Research Foundations Part 3
Notes I took whilst studying "Google DeepMind: AI Research Foundations". Covers fine tuning and accelerating your model.

Fine Tune Your Model
Used to transform a general pre-trained model into a specialized one. You take the base model and continue to train on a smaller high quality dataset of sample conversations or instructions.
The base model is just doing text completion (pre-trained or PT). The fine tuning allows us to do things like answer questions using the model (instruction tuning or IT).
We go from PT to IT using supervised fine-tuning (SFT). The dataset for this needs to be high quality and may be sourced from humans or from LLMs. Typically prompt-response pairs.
SFT
Data scale is lower than pre-training, but quality requirements are higher
- Collect specific data
- Prompt curation from public sources or machine generated
- Filtering - decontaminate the data, reduce overlapping samples
- Template - post-training data format, uses control tokens e.g. start of turn, end of turn, model and user.
Training objective for SFT is the same as with pre-training.
Reinforcement learning from human feedback (RLHF) - last stage in instruction tuned models, used to align output with human preferences. Use a reward model to provide this output.
Full fine tuning - update all model params.
Parameter efficient methods (PEFT) - Update a subset of params e.g. LoRA. Reduce memory footprint needed for fine tuning.
If the task is similar to an existing capability or we have a small data set, then PEFT can be used.
Evaluation
We need to eval the model post fine tuning.
-
Benchmarks - task specific datasets with ground truth samples. Use metrics or an LLM to compare.
-
Human assessments - side by side comparison of 2 LLM outputs e.g. LMArena for crowd sourced comparison.
Full Parameter Fine Tuning
Continue training your transformer on the new task by performing additional steps of gradient descent.
For each mini-batch in the fine tuning dataset:
-
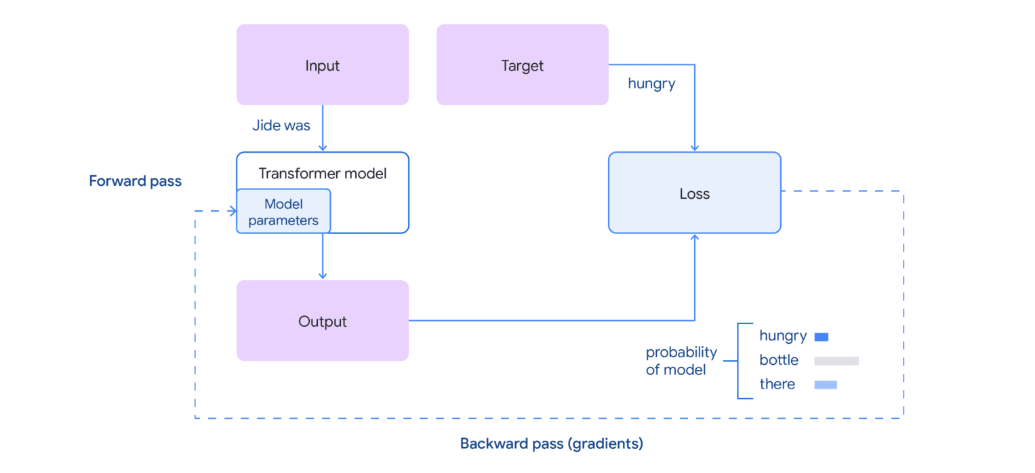
Forward pass - take previous tokens and predict the next token
-
Loss calculation - compare the predicted token to the target token and calculate the prediction error
-
Backward pass - compute the gradient loss wrt each param using backpropogation
-
Update params - use gradients to update model's weights and biases to minimise the loss using some optimizer like an Adam optimizer
You start with existing weights from a pre-trained model.
You use a smaller, more focused, high quality dataset.
Fine tuning requires fewer weight updates so is faster than pre-training.
Practical Tips
Learning rate is kept smaller to prevent the model forgetting it's pre-training. More "localized" learning in a smaller region. Helps to prevent catastrophic forgetting.
When we fine tune on say question-answer pairs, we need to limit the loss calculation to only occur on the responses, not inadvertantly the questions as well. When we're generating a target sequence, we can using a PAD character to remove the question:


- Pad and truncate samples so they can be grouped as batches
- Shuffle data to avoid similar examples appearing in the same batch
- Adhere to the max length of the pre-trained model
- Use small batch size for memory - also makes the gradients noisier (small sample size) and can help prevent overfitting
Monitoring Model Performance During Fine Tuning
We use a validation strategy to ensure our tuned model performs well without losing pre-trained knowledge. Prevent overfitting to the tuning data set.
Check if your model can still make generalized extrapolatins.
Ensure language abilities are retained by including beginnings of statements that need to be completed in the evaluation dataset.
Evaluation
Language quality is subjective. Generalized metrics can fail to capture the goal of the fine tuning task e.g. a metric for the language quality is not related to factual accuracy.
Issues with Fine Tuned Models
-
Overfitting to the fine-tuning dataset after being trained for too long
-
Hallucinations - generation of factually incorrect information. Priotizes sounding right vs being right. Done to ensure the output matches the pattern it learned during fine-tuning. Can occur due to small fine-tune dataset size.
-
Forgetting - the model is not updated on the pre-training dataset during the fine-tuning phase, so the fine tuning phase can over-write weights from pre-training. Models can also forget general abilities they learnt during pre-training like forming coherent sentences.
Full param fine tuning is more susceptible to catastrophic forgetting as all params are updated during the fine-tuning phase.
Foundation Models
Common base or bedrock models. Pre-trained on a massive and diverse dataset so it has broad general capabilities like correct syntax, semantics and strong reasoning ability. Built to be fine tuned and customized. Typically have billions or trillions of params.
Can learn and reflect societal biases due to the dataset they're trained on - which gets perpetuated through their active use.
Examples: Gemma from Google, BERT
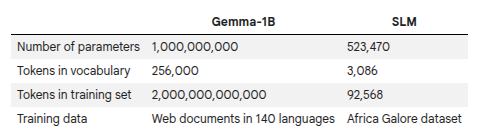
Model Capacity and Size
The Gemma 1B model has approximately 1.3 billion
parameters (1B for the main transformer blocks and
300M for the token embeddings). A model of this size
typically requires around 4GB of memory, so it fits
on a T4 GPU with 15GB of memory. However, a 27B
model, that is a model with around 27 billion
parameters would require roughly 100 GB of memory
(27 × ~3.7 GB), which exceeds the capacity of
a single T4 GPU multiple times.
LoRA - Low Rank Adaptation
LoRA - fine-tune large models that only requires a small number of the total parameters to be trained.
Training can require 4-5x more GPU memory than for inference.
The goal of LoRA is to reduce the number of parameters
when fine-tuning a model. Since both the attention
mechanism and the multi-layer perceptron in every
transformer block contain dense layers, it is possible
to apply LoRA to some or all of these dense layers,
resulting in a much lower number of layers that
need to be trained
Parameter Efficient Fine Tuning
Train only a subset of the model's parameters. e.g. train the last 2 layers and keep the rest of the layers unchanged. The unchanged weights are frozen.
Another approach is to add adapter layers after each transformer block. The adapters then adjust the entire network's layers. Can get better performance, but requires additional layers to be added.
LoRA works by decomposing a matrix into 2 smaller sub-matrices. You can get back to the original matrix using multiplication.
e.g.

In LoRA we:
- Freeze the pre-trained weight matrix W0
- Approximate the updates to the weights using the product of the decomposed matrix
- Both the pre-trained weights (W0) and the weight updates are multiplied by the input before outputs are added
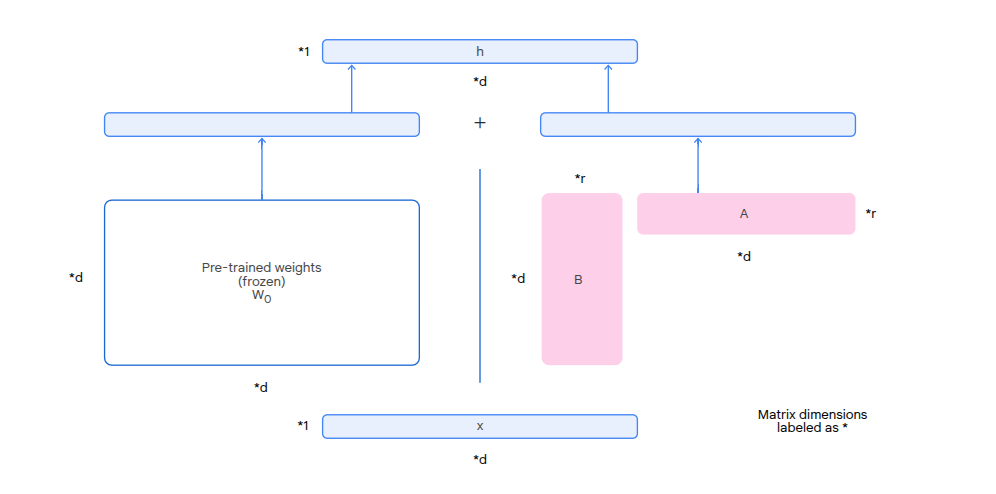

If we were training on the weights, we'd be training d^2 weights in total.
When we train on the decomposed matrices, we are training 2dr weights. You don't need to train and update W0 during LoRA, just the 2dr weights in the decomposed matrices.
SFT and Negative Examples
Negative examples: In supervised learning, it is
difficult to teach a model what not to do. However,
for several use cases, you want your model to avoid
certain responses. For example, you may want your
model not to insult your user. You do not want your
model to give harmful responses, or more generally,
to cause negative consequences. Since the pre-trained
models that you are building on are large and already
trained on a vast amount of data, you cannot easily
control what capabilities they possess. If you only
present examples to be imitated during fine-tuning,
you cannot successfully teach the model to avoid
negative behavior.
Reinforcement Learning From Human Feedback (RLHF)
Prompt a model to produce multiple responses - use preference data to fine tune the model. Preference pairs are relatively easy to construct.
Preference scores an entire response, not just individual tokens step by step.
Reward Model
Trained on human preferences that have been gathered in advance. Taught to imitate how a human would rate something and assign a numerical score. A fast automated judge to provide ratings during the main LLM training.
Policy gradient - identify which weights contribute to a high scoring output, adjust those to make similar outputs more probable.
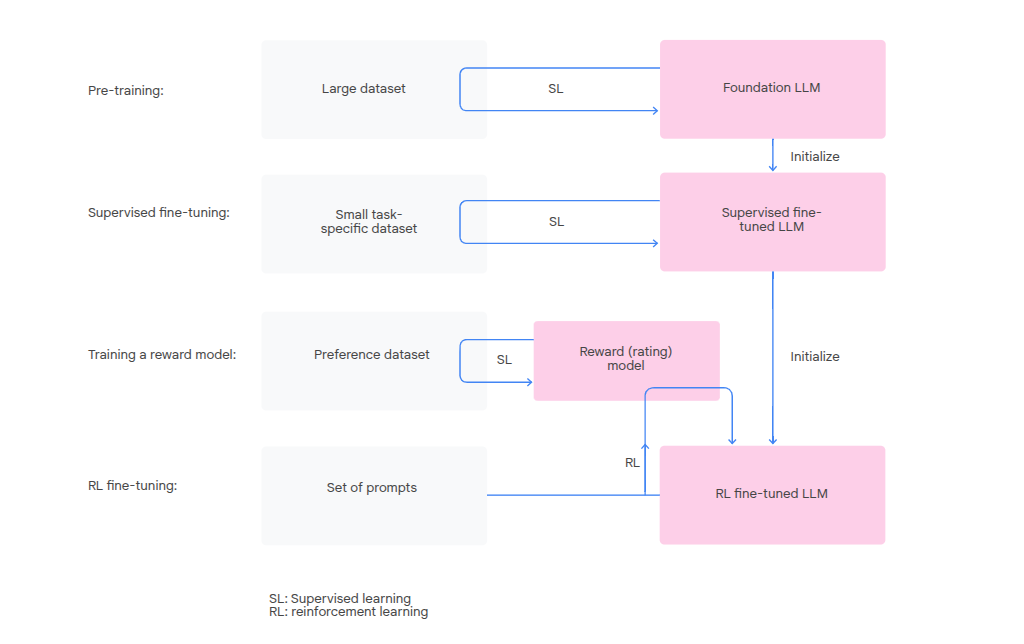
- Pre-training - foundational models
- Supervised fine tuning - small dataset to fine tune the LLM to a specific task
- Training a reward model - predict a score based on human preferences
- Fine tuning the supervised fine tuned LLM with reinforcement learning - use the reward model to guide the LLM
Foresight and Governance
Fiction is a way to imagine different possible futures.
Narrative scenarios help stakeholders antipate potential consequences as well as the meanings and values attached to technologies - can be an ethical warning system.
Foresight is a governance approach. A structure way of exploring multiple possible futures to identify signals, trends, opportunities and risks. Prepare for uncertainty and make better present choices.
Governance determines who has power, who is included in decision-making, and how accountability, fairness, and justice are ensured.
Foresight is not about predicting one inevitable outcome but about generating multiple plausible futures that reflect different values and explore multiple possible impacts. It also allows you to think about what kind of governance responses might be required before decisions become locked into place and hard to change.
Governance Approaches in the Context of AI
Source: Google
-
Enforce existing laws - making sure that existing laws such as data protection, anti-discrimination, labor, or consumer safety regulations are applied to AI systems.
-
Creating clear, bright-line rules - Bright-line rules are simple, non-negotiable prohibitions on practices that pose unacceptable risks. These rules are context-specific and agreed by the communities and societies that they impact. In contexts with limited regulatory capacity, bright-line rules help regulators act decisively and give organisations clarity about what is off-limits.
-
Placing the burden of proof on organizations - Instead of expecting the public or regulators to prove that an AI system is harmful after deployment, governance should require companies to demonstrate safety and fairness, and consideration of environmental impact before launch. At each phase of the AI lifecycle, from design and training to deployment and monitoring, firms can provide evidence such as independent impact assessments independent bias audits.
Technology is not Neutral
Technologies are not neutral; they embody and transmit values that influence how communities experience them.
Accelerate your Model
To train large models on small hardware footprint:
- Reduce model size - tradeoff on performance
- Decrease batch size - less examples processed per batch during training. Smaller training batches can lead to worse/noisier gradient estimations.
- Use lower precision types to store parameters - quantization and mixed/reduced precision training
GPU Architecture
Data from main memory is transferred to the GPU via SRAM (L1 cache) and vice-versa.
Memory bound - data can't get to the compute units fast enough and they idle waiting for data.
-
General compute unit - for general computations.
-
Tensor cores - for specific operation, matrix multiplication. Approx 15x faster than general compute at matrix operations. Don't support all data types e.g. f32 vs f16.
Compute bound - the data can move faster than the compute takes, you're fully utilizing your compute resources.
Sometimes faster to just re-calculate something than transfer it back and forth to main memory.
JAX -> XLA compiler -> Code that runs on GPU
You can also code on GPUs directly using CUDA. For deep learning people use Triton (Python) or Pallus Mosaic.
GPU During Training and Inference
Lots of matrix operations during training
FLOPs vs FLOPS
FLOP - Floating point operation
The matrix multiplication in a transformer block is a mixture of multiplication and addition.
-
FLOPs - plural of FLOP
-
FLOPS - FLOPs per second
Estimating FLOPs

P = the number of trainable model params
N = the number of tokens in the training dataset
6 is a rule of thumb based on a single epoch of work:
-
Forward pass - 2PN FLOPs, one multiplication and one addition.
-
Backward pass - 4PN FLOPs, involves calculating a gradient which is approx 2x more expensive as the forward pass
Smart Numbers

We represent a float as:
- Mantissa - the significant digits e.g. 1.2345
- Exponent - the power of the value that scales the mantissa e.g. 2 in 10^2
- Sign - whether the number if positive or negative
Floating point representations assign a specific number of bits to each of these components, resulting in a trade off between range (the largest and smallest number, impacted mostly by the exponent) and precision (how accurate a number we can store without losing significant digits, impacted mostly by the mantissa)
bfloat16
Google Brain's float16 format. Reduces precision by using less bits to represent the mantissa. Preserves scale/range representation ability by using the same number of bits to represent the exponent as f32. Represent very large and small numbers but with less accuracy than a f32.
Keeping a large range results in training stability as we are less likely to encounter under or over flow.
Reduced precision results in faster matrix multiplications (can also store more in memory and so transfer more info to the GPU) and lower memory usage (storage).
float16 - half precision, it reduces both the range and precision via the exponent and mantissa respectively.
Reducing Computational Effort
Batch Size
Training in batches means we can better utiliz the capacity of the GPU - more datapoints can be processed in a single pass. Maximise the parallel computation capacity of the GPU by making sure all cores are utilized.
A larger batch size leads to more stable training as there is less noise in the gradient descent. It can lead to generalization issues e.g. from extreme values leading to extreme parameter values.
Too large a batch size can lead to diminishing returns or a slowdown as the overhead of managing data transfers outweighs the paralellization benefits.
Quantization
Convert the model weights into a lower precision representation.
Mixed Precision
Use different precision for different parts of the training process e.g. low precision matrix multiplication, high precision weight updates.
4Ms and Carbon Footprint
- Right model
- Efficient machines
- Modern mechanization (data centers)
- Right map (geographic location)
What Needs to be Stored in the GPU?
Foundational Data
-
Model parameters like the learned weights and biases like the query, key and value weights matrices.
-
Input data - the data currently being processed
Temporary Data During Training
-
Optimizer states - some optimizers like the Adam optimizer store running averages of past gradients (momentum) and squared gradient (variance) to help model convergence
-
Gradients - partial derivatives of the loss function wrt to each model param. One to one relationship between params and gradients.
-
Activations - forward pass output of each layer. Used to calculate gradients in the back pass. Discarded during inference as there is no backward pass needed.
Gradient Accumulation
Simulate a large batch using the memory required for a smaller/minibatch that fits on the GPU. Breaks down a batch into minibatches, each of which goes through a forward pass. Instead of modifying the weights after each minibatch, we accumulate the gradients (a running total) from the backward pass phase allowing us to free up GPU memory to process the next minibatch.
After all minibatches are processed, the average of the accumulated gradient is taken and the model params updated in a single step using this average.
Results in More stable training - larger batch size can be handled, better model performance, easier to reproduce academic research. Increased training times vs a single larger batch size. With minibatch, the time taken is proportional to the number of times we accumulate.
Advanced Scaling Techniques
The 2 fundamental hardware limits faced are memory capacity and compute efficiency.
Flash Attention
For a single head we can end up with a large matrix - the number of tokens squared for the intermediate attention matrix. This large matrix may need to be written to and read from GPU memory which is slower than the compute units - it becomes memory bound, leaving compute units idle.
Flash attention uses tiling. It also uses kernel fusion - the subcomponents of the attention operation (matrix multiplication, scaling, masking and softmax) are converted into a single kernel which the GPU can operate.
Multi GPU Strategies
A model can be too large to fit into a single GPU, or the dataset can be too large for a single machine to handle so we may need to scale horizontally.
-
Data Parallelism - each GPU has the same model but processes a different slice of the data. Communicate to average their gradients so all model copies learn collectively.
-
Tensor Parallelism - The model layers are split across multiple GPUs. Weights, gradients and activations become distributed. A large matrix multiplication operation may see the matrix being split across multiple GPUs.
-
Pipeline Parallelism - Different layers across different GPUs. Each GPU feeds sequentially into the next for the forward pass and respectively for the backward pass.